

Meta's MTIA Roadmap
Inference-centric design tradeoffs are smart. ROIC is clear. Implications across the supply chain.

QUICK HITS
Four MTIA chips in two years, all inference optimized
ROIC story is straightforward
Further validates the industry is past “GPUs for everything” value prop
Implications for Broadcom, Nvidia, AMD, HBM suppliers, TSMC, Arista, and inference startups
The narrative around AI silicon and GPUs has changed. Six months ago, the default assumption was that GPUs are the answer for everything. But as I wrote about last October in Right-Sized AI Infrastructure, as AI workloads mature and become better understood, the economics favor purpose-built hardware over general-purpose GPUs. I’ve been long saying this, see GPU bloat stifles AI from Feb 2024. But that was long before reasoning models and agentic AI, so the industry was still stuck on “is GenAI even useful?” and “what if LLM architectures change?
The demand for transformer-based LLM inference is exploding. As Ben Thompson stated this week, we’re in a new era and demand is increasing exponentially :
This [functional agents] increases the market in two directions: first, humans can run multiple agents, and secondly, agents can leverage reasoning models multiple times to accomplish a task. This isn’t just an exponential increase in the addressable market for tokens, it’s two exponential increases squared.
In this era of intense demand (NEED MOAR TOKENS FOR MY AGENTS!), developers care about latency (MAKE AGENTS FASTER!) and throughput (DANG OPUS IS EXPENSIVE!)
The market is responding rationally. In just the past several months we’ve seen NVIDIA+Groq and OpenAI+Cerebras. And those were pre-ChatGPT chips, aka they made design decisions not optimized for transformer LLM inference.
We’ve also seen maturing XPUs and roadmaps, including Trainium 3/4/5, Microsoft Maia 200/300, and now Meta MTIA 300/400/450/500.
Meta’s annoucement was this detailed technical blog articulating four iterations of MTIA that have shipped or are planned within roughly two years.
And they were very transparent with specs, timelines, etc. This is really cool. Of course, a company like AWS with Trainium is going to share XPU specs because it’s cloud rental business might rent out the XPUs too. But Meta’s only using them internally; no cloud biz. So Meta doesn’t HAVE to share as much info. But they shared anyway. This is good for investor transparency, for current employees and potential hires, and for us nerds.
Here are said specs from Meta:
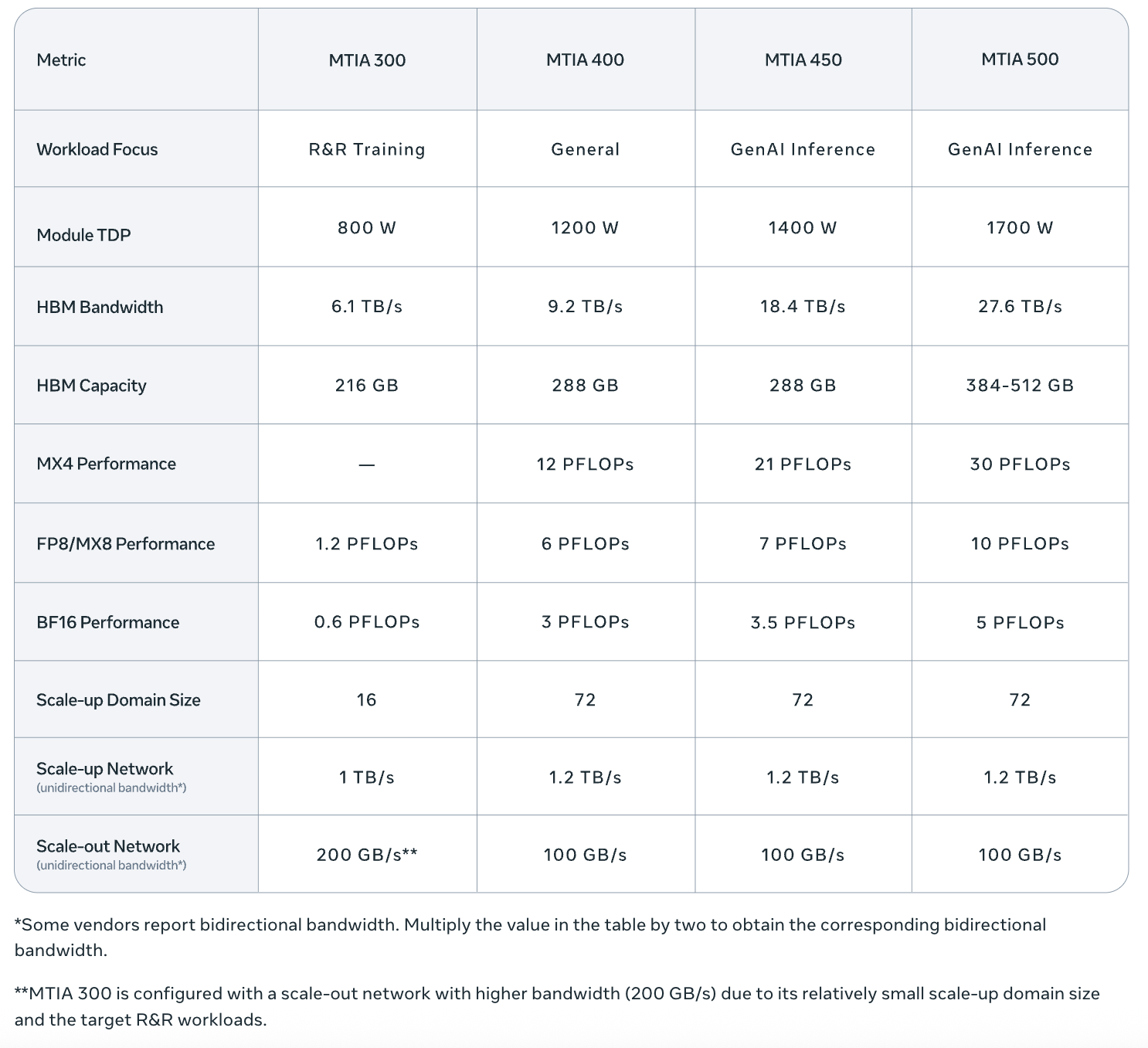
And the roadmap makes sense.
As I wrote in Meta’s ROIC Strategy: GEM Now, LLMs Later, Meta’s business has always been powered by ML/AI infrastructure. Facebook launched the algorithmic feed in 2011, and ever since then ML recommendation systems have driven what 3.5B daily users see and which ads they’re shown. To the tune of $150B+ annual advertising revenue. Hence, the custom inference silicon roadmap is driven by workload, starting with clearest ROI (recommendation systems) and moving toward GenAI.
By the way, Meta and many others are showing that multi-vendor hardware portfolios are no problem. We need compute. We can deal with the software implications of building across stacks.
From the Meta Q4 earnings call:
“We extended our Andromeda ads retrieval engine, so it can now run on NVIDIA, AMD, and MTIA. This, along with model innovations, enabled us to nearly triple Andromeda’s compute efficiency.”
Done right, custom silicon for recommendations is margin expansion on the core business. Custom silicon for GenAI inference is cost reduction on the fastest-growing workloads. A penny saved is a penny earned. Same story AWS tells with Trainium 3+, same story as Microsoft and Maia 200+.
And again, it’s inference-first. From Meta’s blog:
“Mainstream GPUs are typically built for the most demanding workload — large-scale GenAI pre-training — and then applied, often less cost-effectively, to other workloads such as GenAI inference. We take a different approach: MTIA 450 and 500 are optimized first for GenAI inference, and can then be used to support other workloads as needed”
IMO this pushes back on concerns around The Information’s recent article: Meta’s Internal Chip Design Efforts Hit Roadblocks
Meta last week scrapped the most advanced chip it was developing for training AI models, after struggling with the chip’s design.
This generated some hand-wringing for Broadcom and Hock had to address it on the earnings call. But in context, it’s a bit of a nothing burger, right? Given where we are today, internal custom silicon efforts like Meta’s ought to prioritize inference. Use Nvidia GPUs for training. AMD Helios racks too. IMO there’s no urgent need to build custom silicon for training.
The ~6-month cadence is possible because… chiplets!
Because each chiplet can be upgraded separately, we can implement improvements in months rather than years. Moreover, different chiplets can be manufactured at different process nodes that are most cost-effective while meeting performance and power requirements.
Disclosure, big chiplet fan here.
AMD has long punched above it’s weight thanks to chiplets. And here’s Meta doing the same.
And as you would expect, all the systems use the same chassis, rack, and network infra. Yay OCP.
Oh, and so much related news.
Remember Meta’s Sep 2025 acquisition of Rivos, a “CUDA compatible RISC-V AI startup”? From Reuters
“Our custom silicon work is progressing quickly and this will further accelerate our efforts,” a Meta spokesperson said when contacted by Reuters.
Rivos was already collaborating with Meta on MTIA before the acquisition, according to reporting from The Next Platform:
Rivos, which was founded in May 2021, was pretty secretive about what it was up to and it had a partnership with Meta Platforms where it apparently helped in the design of the MTIA 1i and MTIA 2i compute engines (using the more recent and descriptive way of talking about them). The exact nature of this collaboration was unknown. Separate from this, Rivos was working on its own RISC-V CPU and GPU designs.
And four chips in two years requires a large silicon team. Which apparently Rivos had:
With the backing of Walden International with the help of Dell Capital Ventures and Matrix Capital Management, Rivos started off with more than a hundred employees on day one, and Tan was named chairman of the board. This has, in part, given Rivos access to advanced EDA tools and to foundry expertise and capacity at Taiwan Semiconductor Manufacturing Co. Hiring nearly 50 engineers from Apple in 2023 landed it in a lawsuit with Apple, and Tan negotiated a settlement.
Oh interesting. Also, Lip-Bu Tan is EXPERIENCED.
Software seems not to be a problem. Meta’s MTIA blog emphasizes PyTorch/Triton/vLLM compatibility at the ML framework layer. And Rivos also claimed to have built a “CUDA-compatible software stack”. And Meta is good at software.
Sure seems like MTIA will be successful.
Behind the paywall:
HBM vs SRAM: two planes of inference competition, and where MTIA sits
Supply chain impact: Broadcom, NVIDIA, AMD, HBM suppliers, TSMC, Arista, inference chip startups