

Right-Sized AI Infrastructure. Marvell XPUs
Diversity in AI workloads demands diverse AI datacenters. Sometimes, custom silicon is the answer.

Ready to study Marvell’s datacenter business?
Marvell tends to zoom in and talk about the components that power said AI datacenters, namely “XPUs and XPU attach”. And we’ll talk about those.
But first, let’s zoom out.
Marvell helps hyperscalers develop custom AI datacenters.
While “custom datacenters” might sound niche, pretty much all AI datacenters are custom. And of course, the AI datacenter TAM is insane.
But I thought the vast majority of the market uses Nvidia GPUs with NVLink and Infiniband or Spectrum-X… so what do you mean by custom? Seems like mostly all Nvidia…
Recall that AI clusters are made up of many components beyond just the compute (GPU/XPU). They also include networking (scale-up and scale-out), storage, and software. And yes, while many AI clusters share similar components, the resulting system configuration is often distinct.

And just like the image above, each hyperscaler needs to choose the right building blocks and tune the AI cluster to meet its specific needs. A lot of the tuning can be done in software, but some workloads place specific demands on the underlying hardware configurations.
And sometimes the existing Lego blocks don’t quite meet the hyperscalers specific needs. Which makes the case for designing the Lego blocks you need; i.e. working with a company like Marvell or Broadcom to make custom silicon for your datacenter.
But first, lets take a step back and look at the evolution of the merchant silicon offerings.
From the earliest days, new Lego blocks started to emerge that let AI datacenter designers manage trade-offs and tune for specific workloads.
AI Datacenter Diversity
Early in the AI datacenter game, the compute option was largely standardized (e.g. Nvidia Ada/Hopper/Blackwell), and the scale-up network was too (NVLink). So it kind of felt like all roads led to Nvidia.
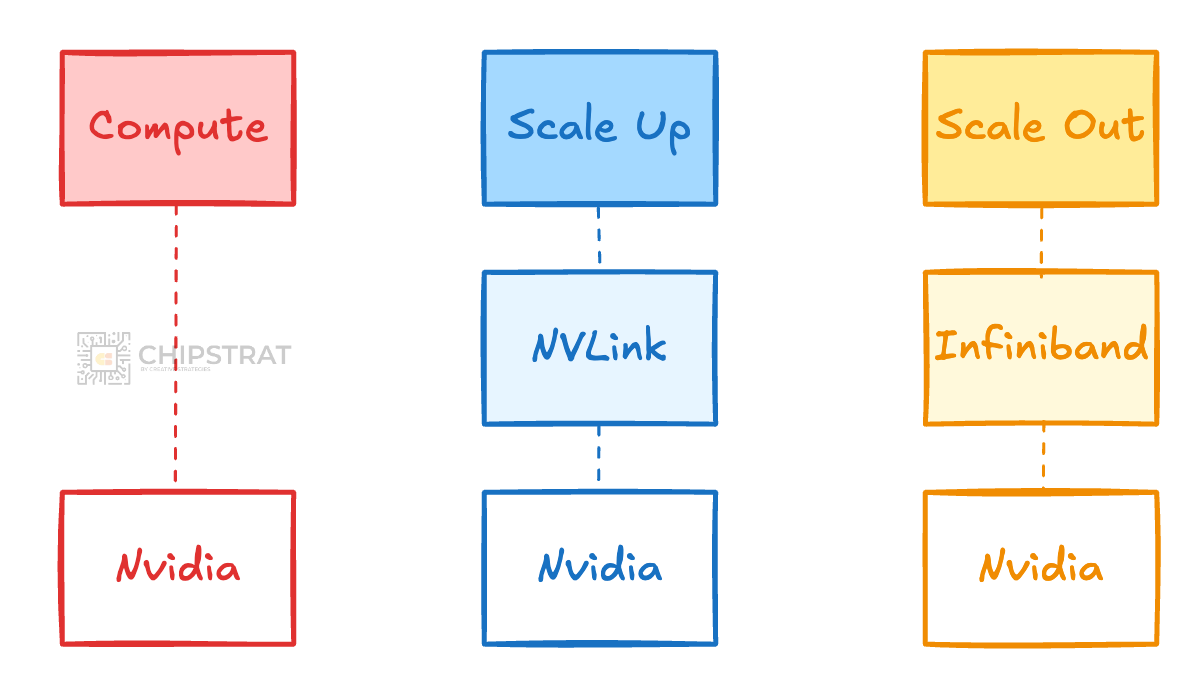
But, for some time now, the scale-out infrastructure has been split between Infiniband and Ethernet, and increasingly so. (More here).
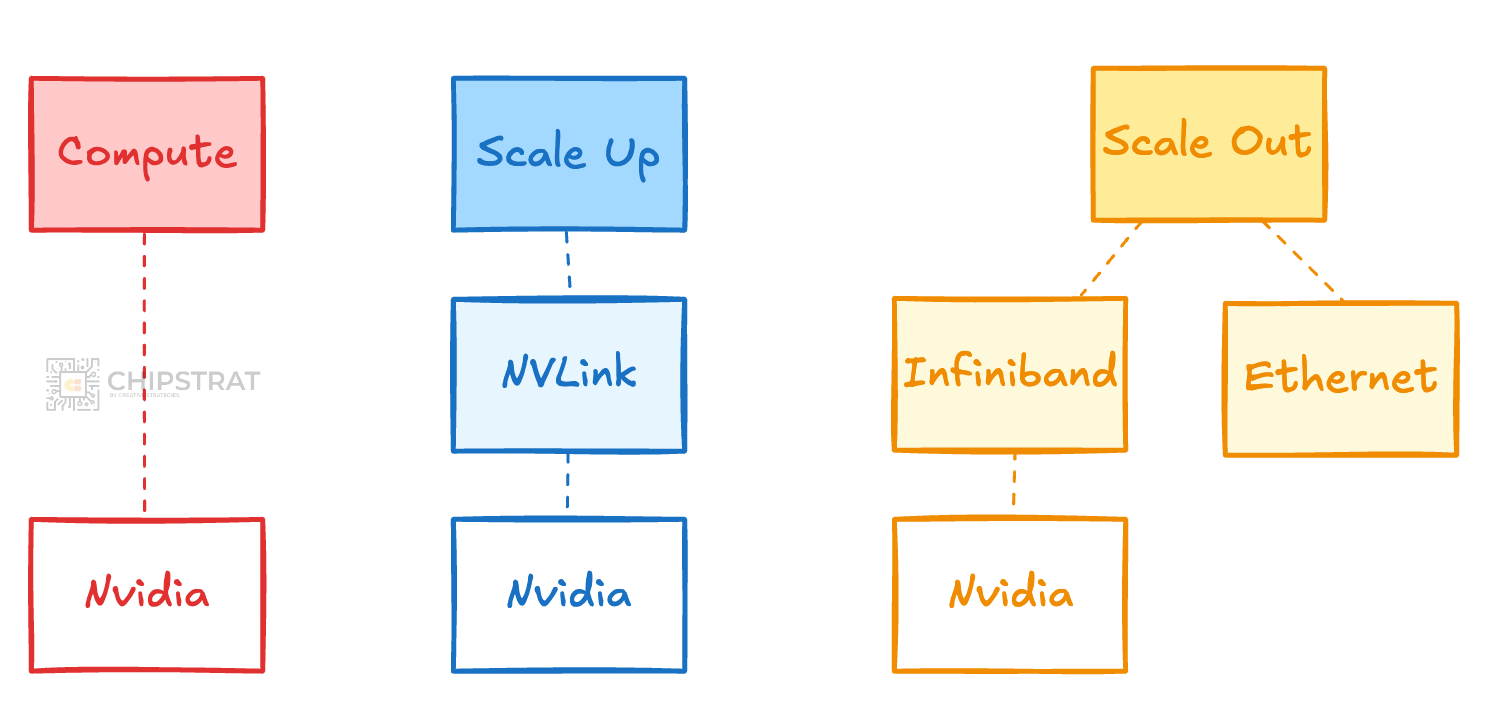
You can start to see the increase in Lego blocks…
Scale Out Networking Diversity
Here’s an example from Meta to illustrate.

Meta basically A/B tested two AI training clusters. Many components are the same, but the scale-out fabric was different; one with Ethernet and the other Infiniband.
BTW, Meta nicely described the custom nature of their infra tuned to meet Meta’s specific needs:
At Meta, we handle hundreds of trillions of AI model executions per day. Delivering these services at a large scale requires a highly advanced and flexible infrastructure. Custom designing much of our own hardware, software, and network fabrics allows us to optimize the end-to-end experience for our AI researchers while ensuring our data centers operate efficiently.
With this in mind, we built one cluster with a remote direct memory access (RDMA) over converged Ethernet (RoCE) network fabric solution based on the Arista 7800 with Wedge400 and Minipack2 OCP rack switches. The other cluster features an NVIDIA Quantum2 InfiniBand fabric. Both of these solutions interconnect 400 Gbps endpoints.
Ok, interesting, we’re starting to see a bit of diversity in this Meta example, something like:
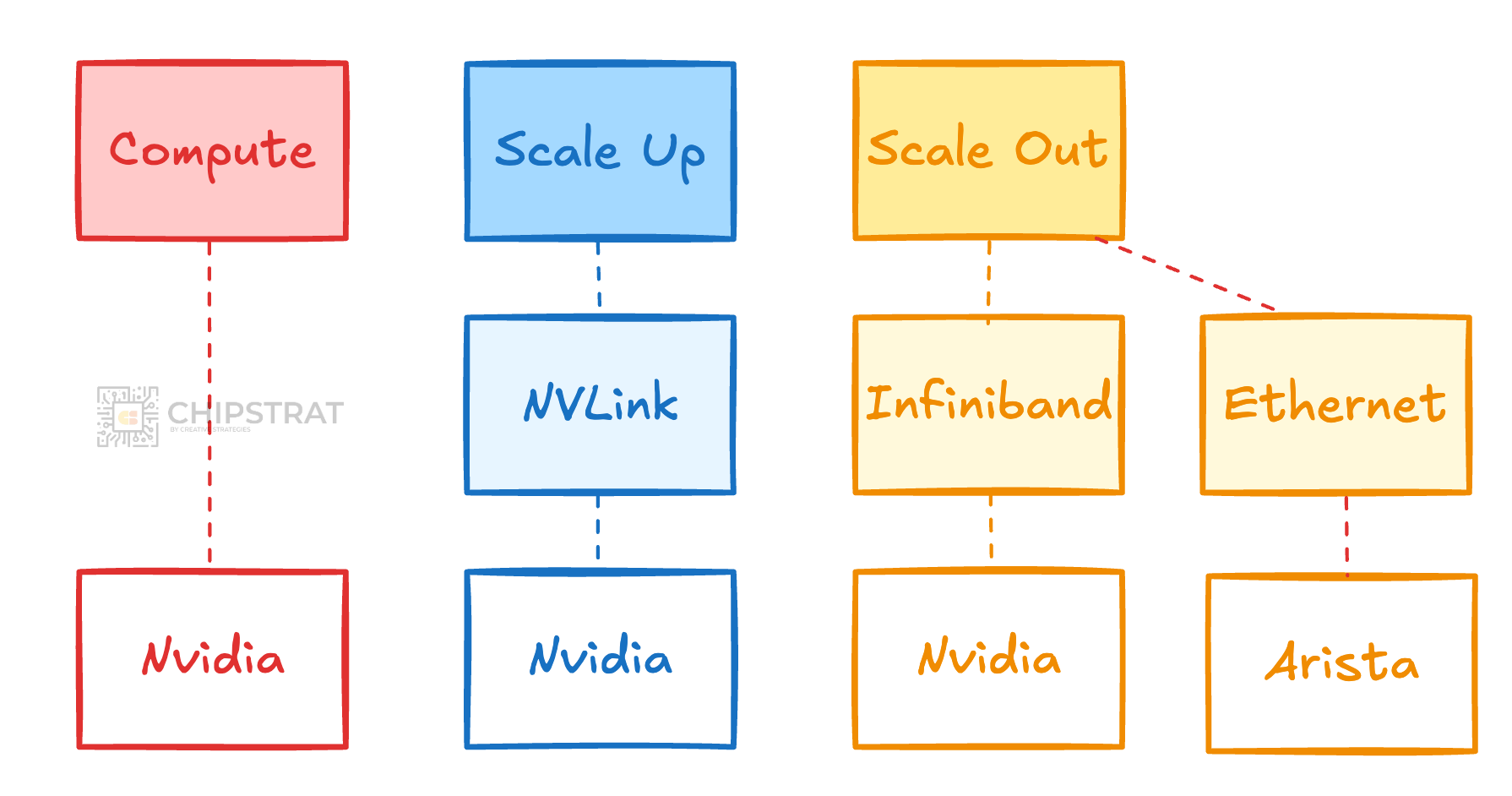
But why would Meta A/B test this scale out fabric?
With these two [fabrics], we are able to assess the suitability and scalability of these different types of interconnect for large-scale training, giving us more insights that will help inform how we design and build even larger, scaled-up clusters in the future. Through careful co-design of the network, software, and model architectures, we have successfully used both RoCE and InfiniBand clusters for large, GenAI workloads (including our ongoing training of Llama 3 on our RoCE cluster) without any network bottlenecks.
Meta is politely saying that compute performance and network performance are always top priorities (especially for the massively communication heavy AI training jobs) but cost and supply chain diversification matter too.
I know, it’s easy (especially for engineers) to treat performance as the ultimate goal, whether that means maximizing tokens per dollar or optimizing tokens per watt within a fixed power envelope.
But you have to think like the GM of the business; your job is to also manage risk and costs.
This is a boon for vendors; can they unbundle a component of the stack and manage to jump into the final configuration?
Scale Out Diversity
We can already see this diversification in Ethernet-based scale-out components, with players like Broadcom, Marvell, Credo, Arista, Cisco, Juniper/HPE, Astera Labs, Alphawave Semi, and Ayar Labs all competing for sockets and fabrics.
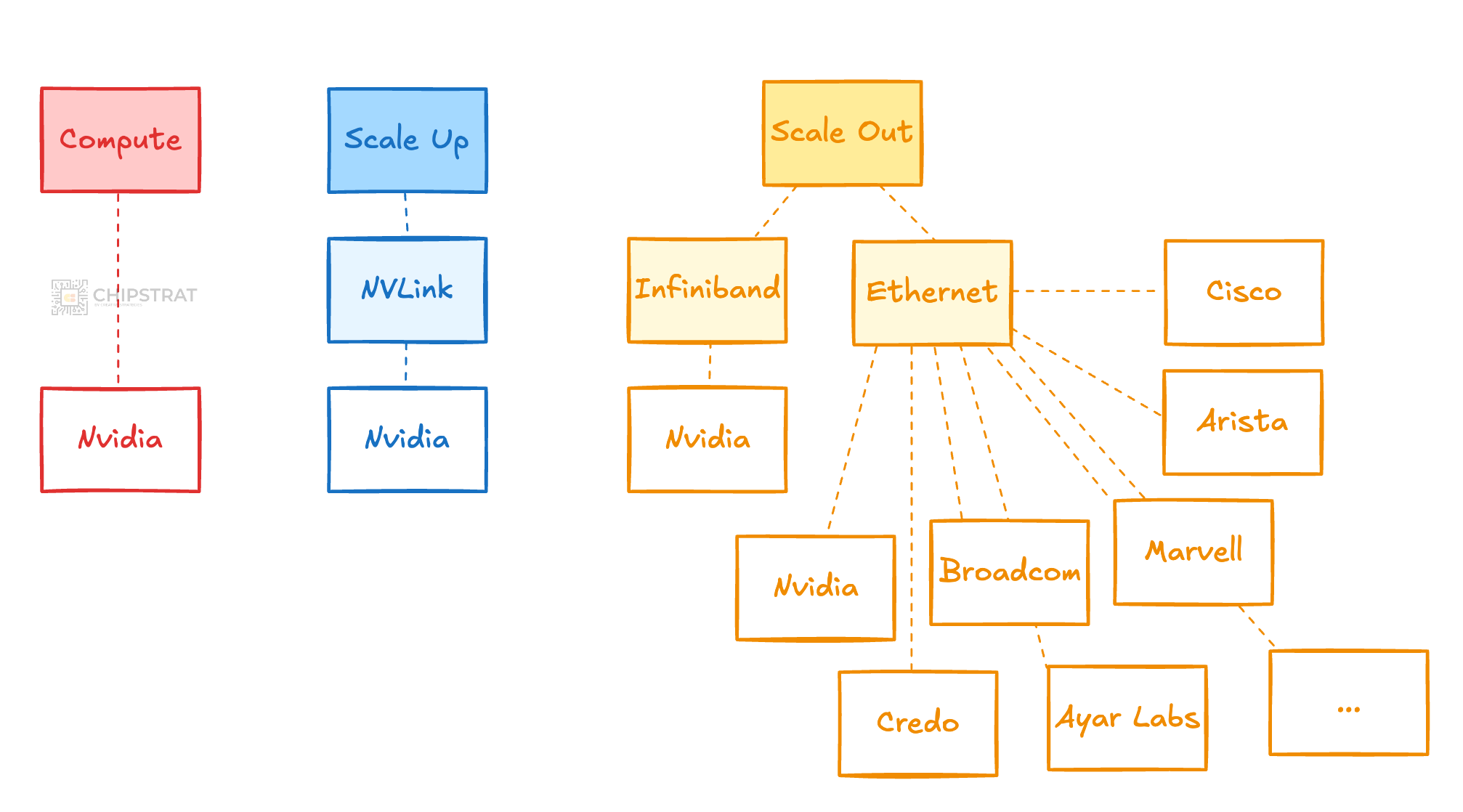
Nvidia, of course, has brilliantly countered this with a fairly new and insanely profitable rocketship Ethernet scale-out business called Spectrum-X (more here).
Interestingly, this expansion means the number of configuration knobs inside even an all-Nvidia datacenter is increasing.
Remember, of Nvidia’s 7 families of chips, 5 are networking!

So even with standardized compute, the diversity of networking options (and we haven’t even talked co-packaged optics) is driving an accelerating combinatorial explosion in AI datacenter design options.
Scale Up Diversity
This diversity in vendors is happening with each component in the system, not just scale-out.
We’re seeing new scale-up protocols emerge with UALink and Broadcom’s SUE (Scale Up Ethernet).
Next year AMD’s 400-series Instinct offerings are marketed on the BYOV (Bring Your Own Vendor) value proposition:

And lots of companies understand scale-up TAM and are clamoring for attention.
Suddenly, there are all sorts of options to choose from:
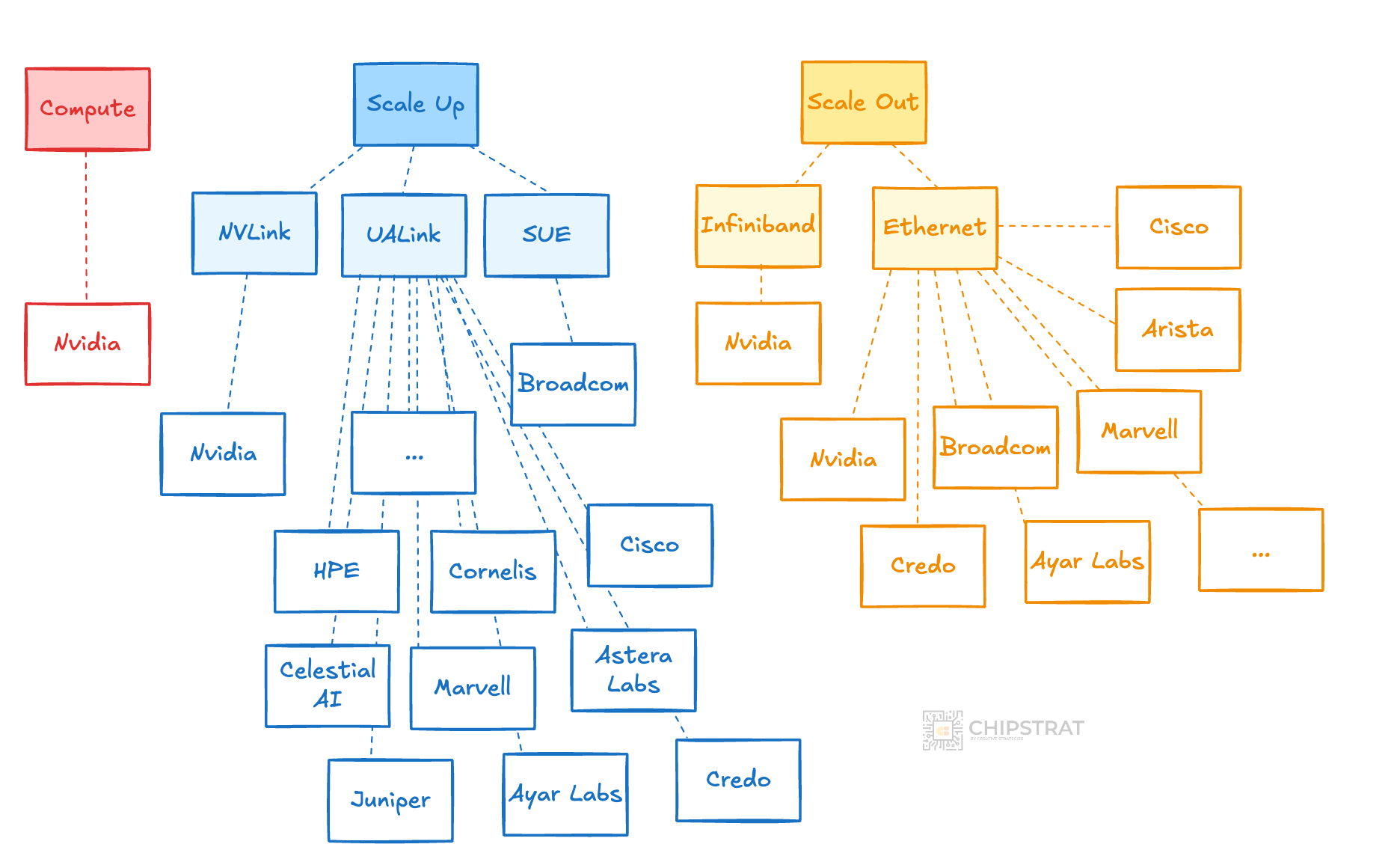
Whew. And that’s just the networking players.
Compute Diversity
Compute options are becoming more diverse too, and not just from new competitors entering the market, but from each vendor’s expanding product stack.
We started with Nvidia’s Ada and Hopper clusters, and now have Blackwell in multiple variants: B100, B200, GB200 NVL72, GB200 NVL36, B300, RTX Pro 6000, and others.
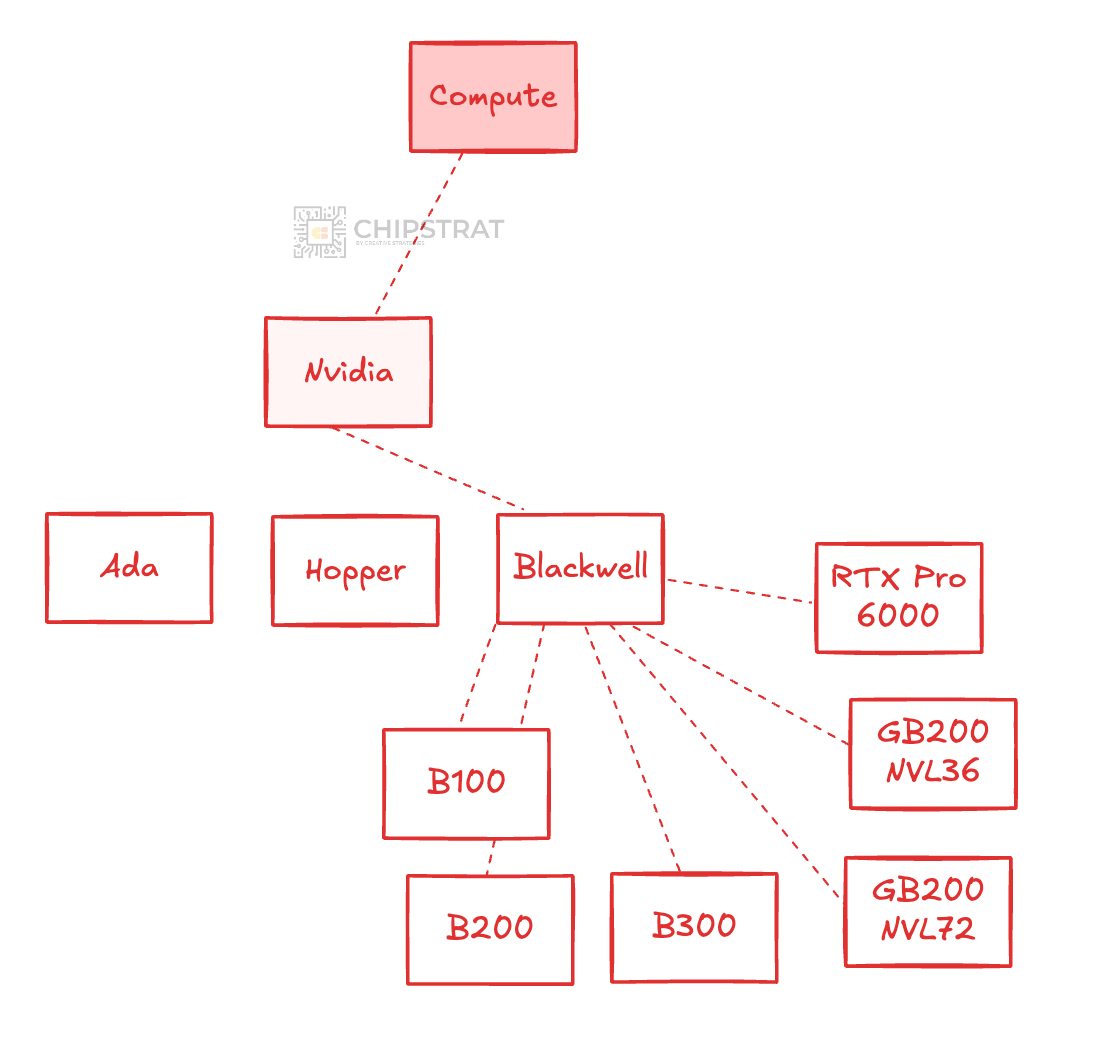
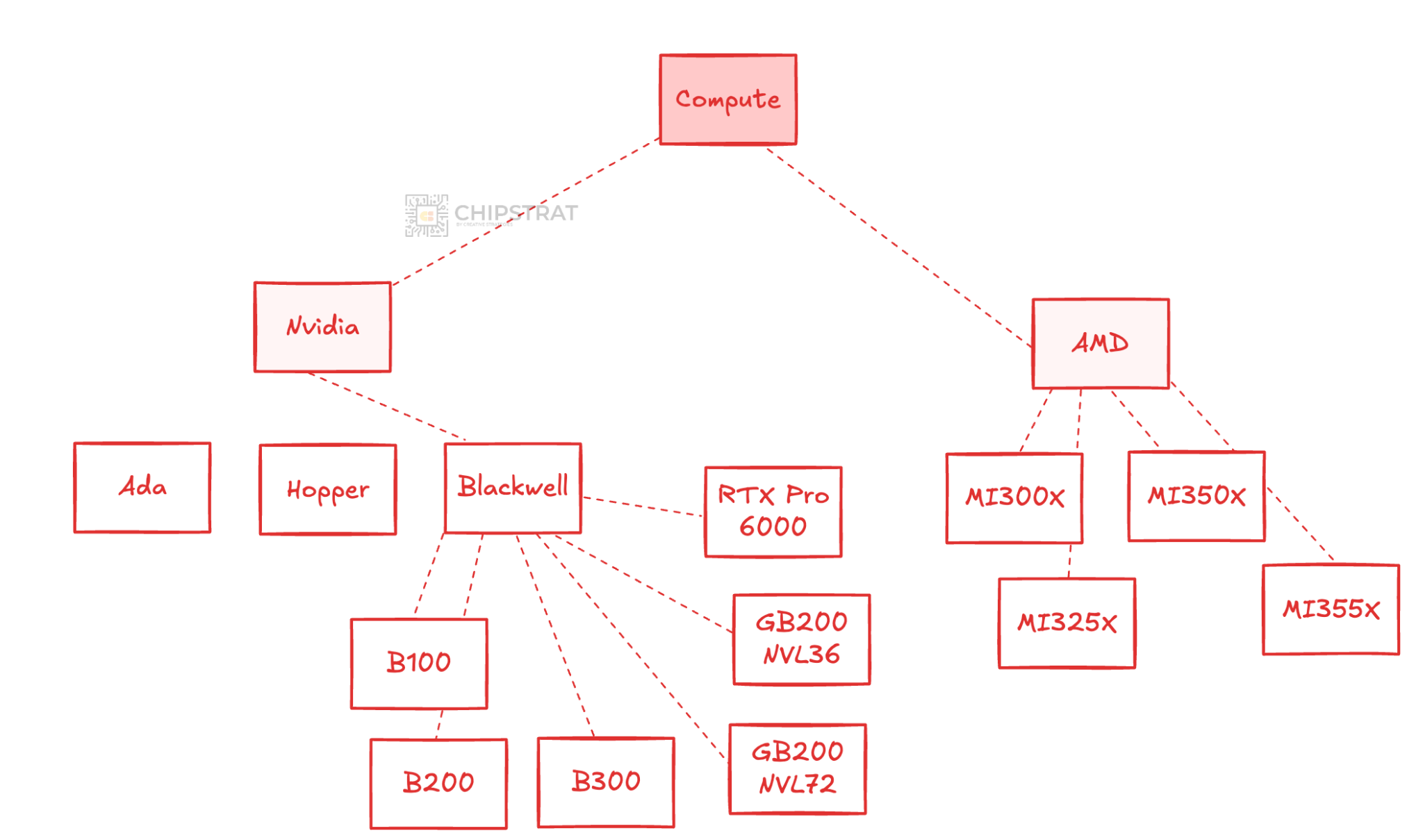
AMD’s Instinct lineup has also grown, spanning the MI300X, 325X, 350X, 355X, and forthcoming 450 that OpenAI will deploy.
And of course many generations of custom AI accelerators (TPU v7, Trainium3, MTIA 2), and even a small amount of startup accelerators in the mix.
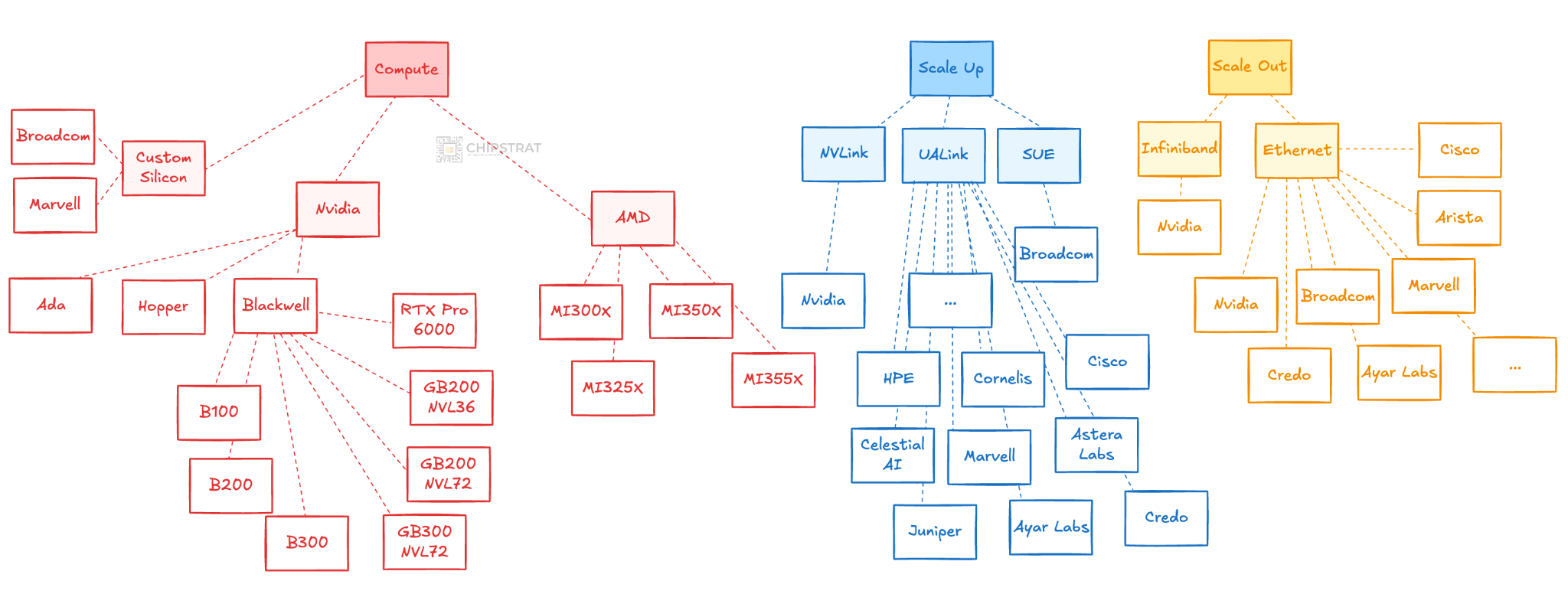
Now this is just focusing on the accelerator compute, but of course the companion CPU matters too.
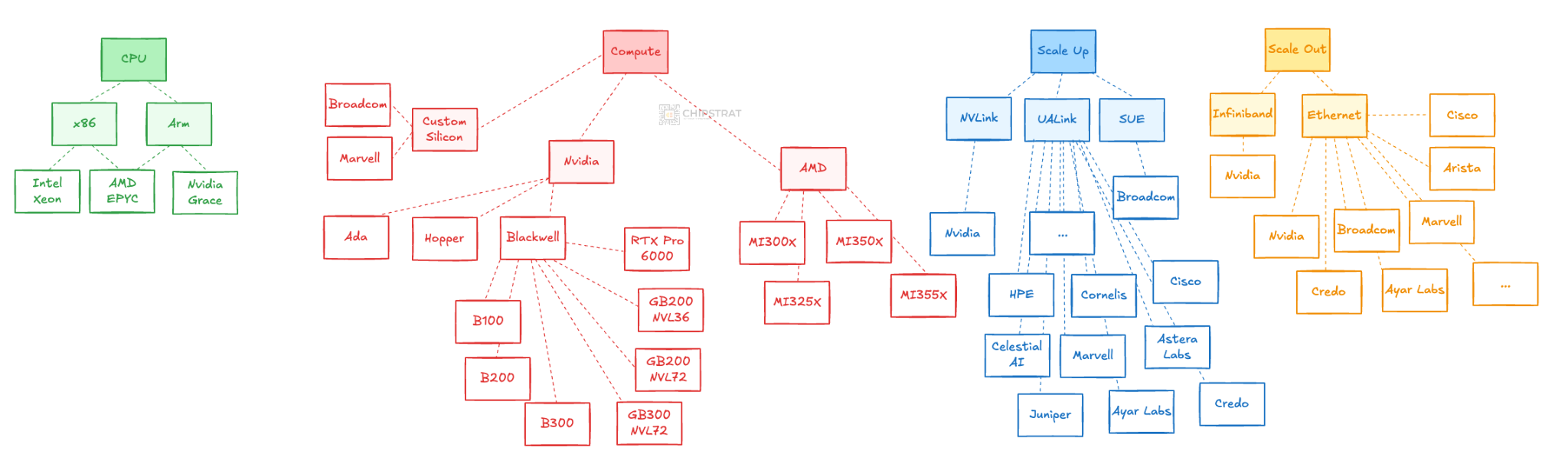
So many Lego blocks to choose from!

Memory and Storage Diversity
Note that these AI accelerators have varying ratios of HBM capacity and bandwidth to compute; this diversity is good for the diversity in AI model sizes.
Remember when the MI300X was released and featured HBM capacity leadership, which was a great fit for specific models?
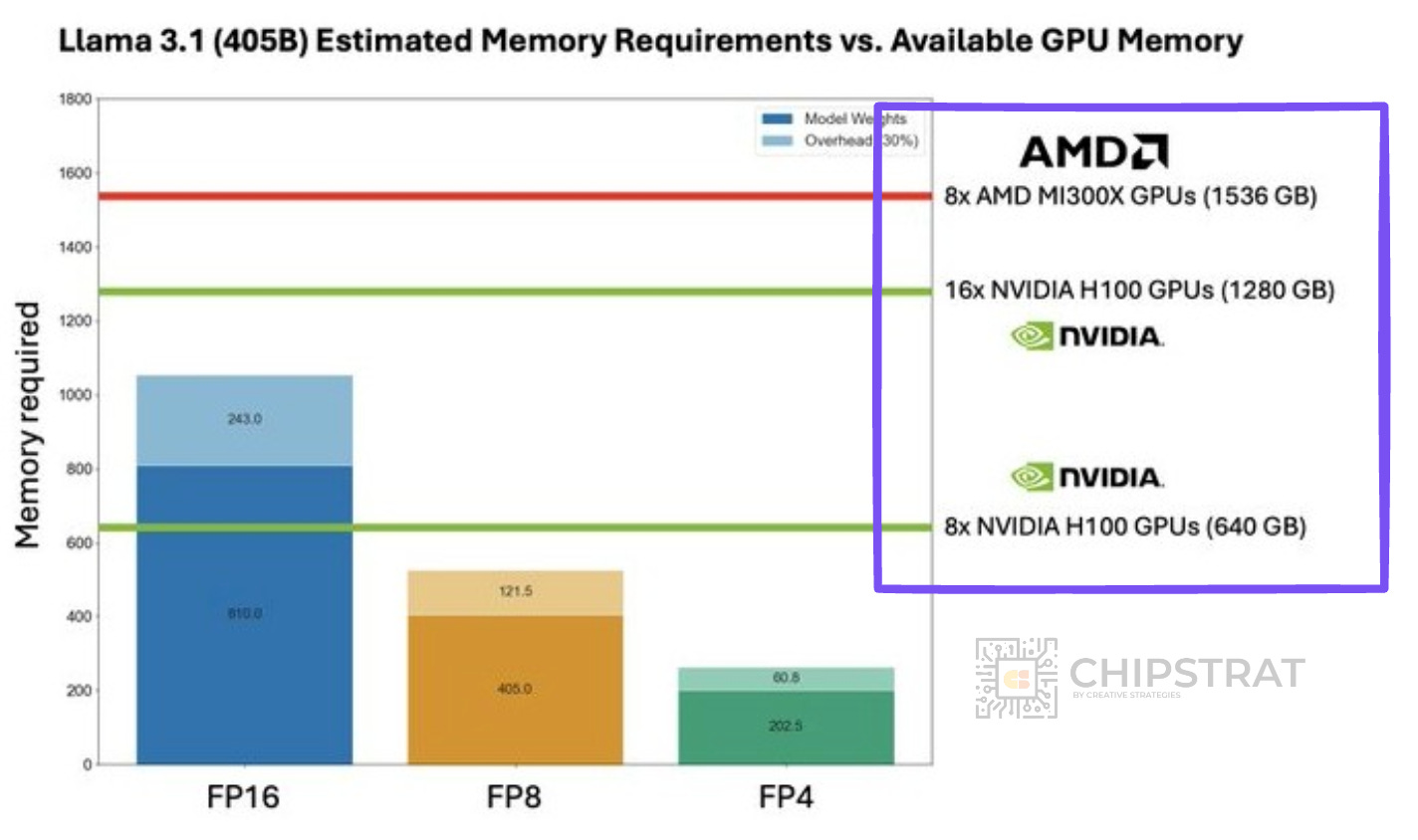
This was a great example of the benefits of choosing your compute/HBM ratios carefully to cost and performance optimize your workload.
And oh by the way… HBM will soon have customizable base dies!

From Micron’s recent earnings call,

Custom HBM base dies… yet another degree of freedom for designers.
Now, granted, HBM is an interesting one because it’s tied to the accelerator right now; if you want a certain HBM to FLOPs ratio, you can only choose from whatever ratio merchant silicon vendors offer.
Or you could make your own AI accelerator with someone like Broadcom or Marvell so that you could tune the HBM to FLOPs ratio precisely… (we’ll talk more on this later).
By the way, this hints at the need for architectural innovation that can decouple HBM from the accelerator die. What if you could disaggregate HBM from the compute so that chip makers could easily scale that HBM die to meet their particular workload needs?
By the way, everyone is coming around to the realization that AI is exponentially increasing the amount of content created.
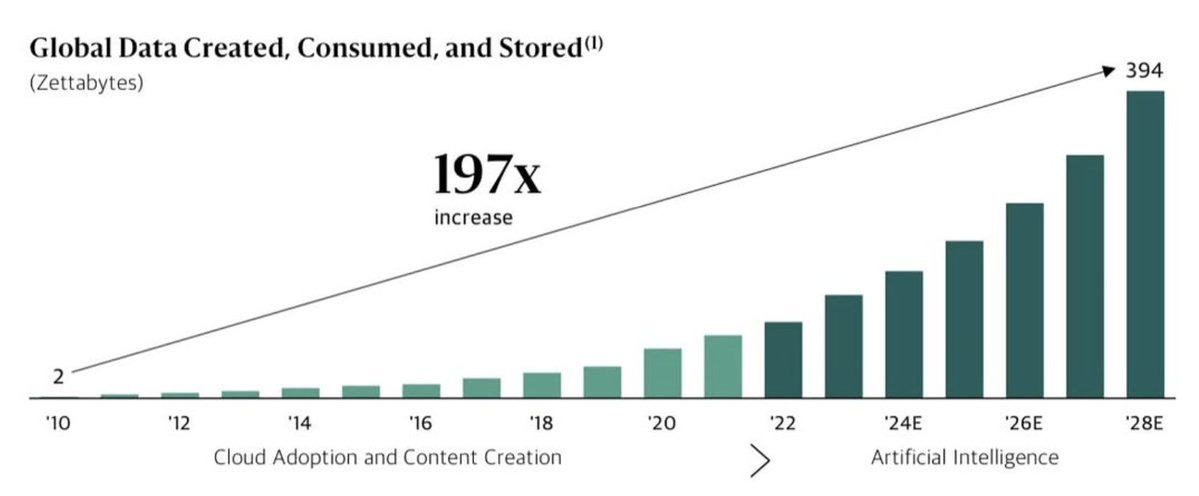
This obviously implies AI datacenters need to think through the storage needs of their workloads and plan infra accordingly.
Micron summarizes it nicely. AI is a huge driver up and down the memory hierarchy.
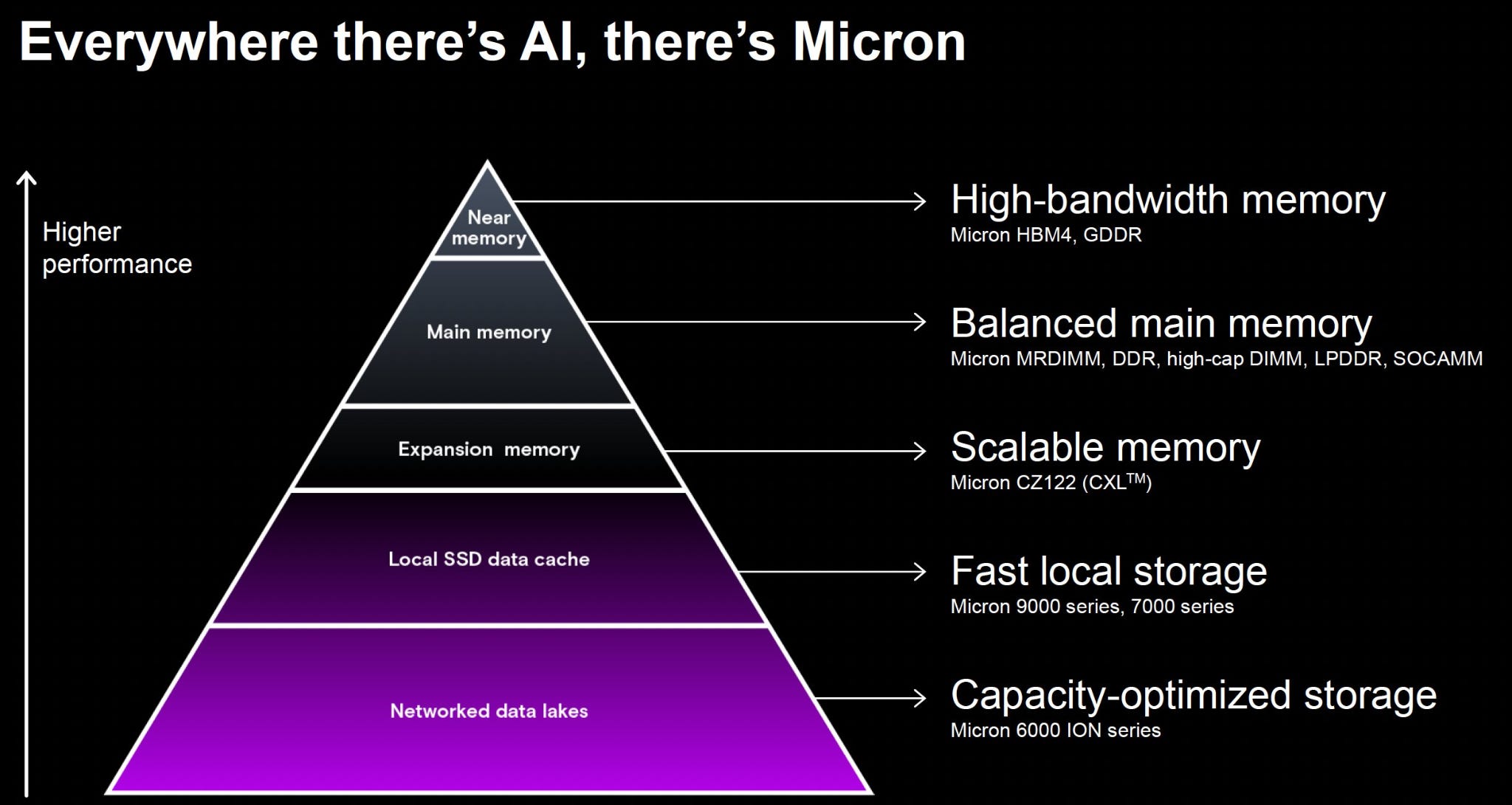
Alright, so we’ve established that the main building blocks each now come with a growing set of vendors and product choices.
So with all those combinations on the table, how do hyperscalers actually decide what to build?
Workload Diversity
Which components are truly necessary? That depends entirely on the workload and its specific user experience requirements.
Where do your needs fall on this radar chart?
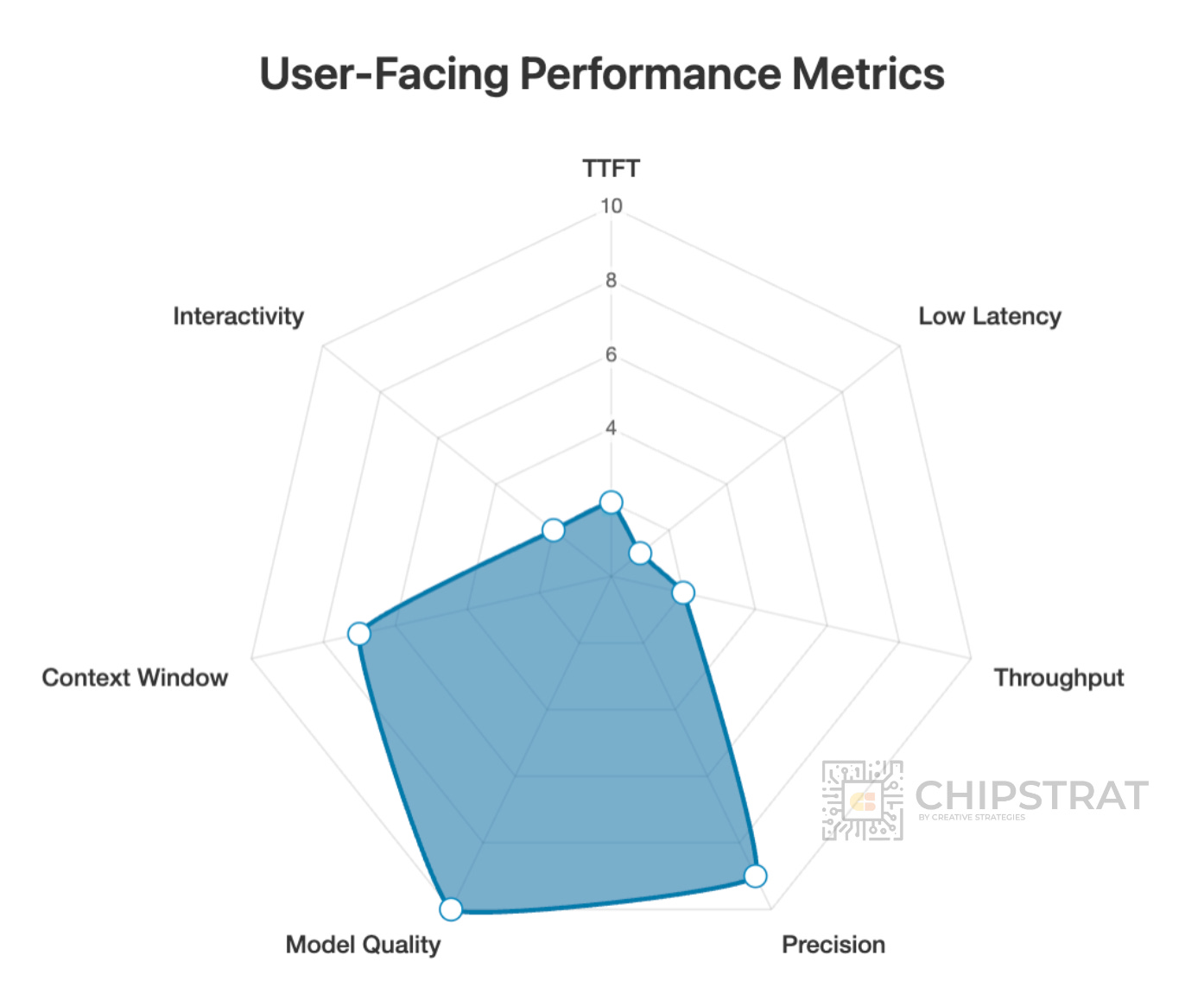
Do you need super fast time-to-first-token, e.g. an audio use case? After all, dead air feels like the AI is broken (“did it hear me?”). Thus the “shape” of the requirements for an voice-to-voice workload might look like this:
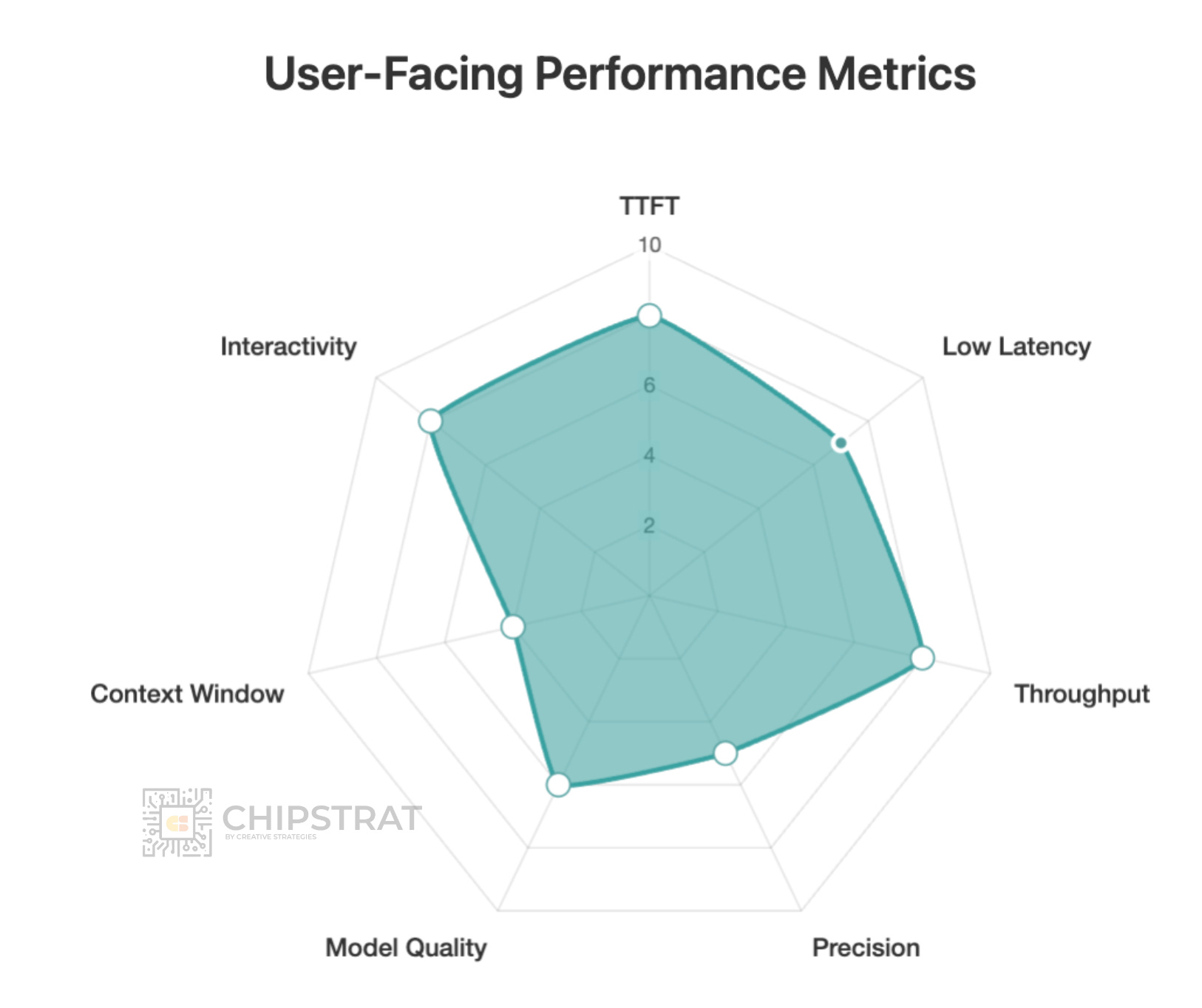
For instance, a voice-to-voice AI workload needs a very fast time-to-first-token (TTFT); dead air makes users think it’s broken (“did it hear me?”). But it doesn’t need ultra-low end-to-end latency, since it only needs to respond at a natural speaking pace. Nor does it require the most sophisticated model.
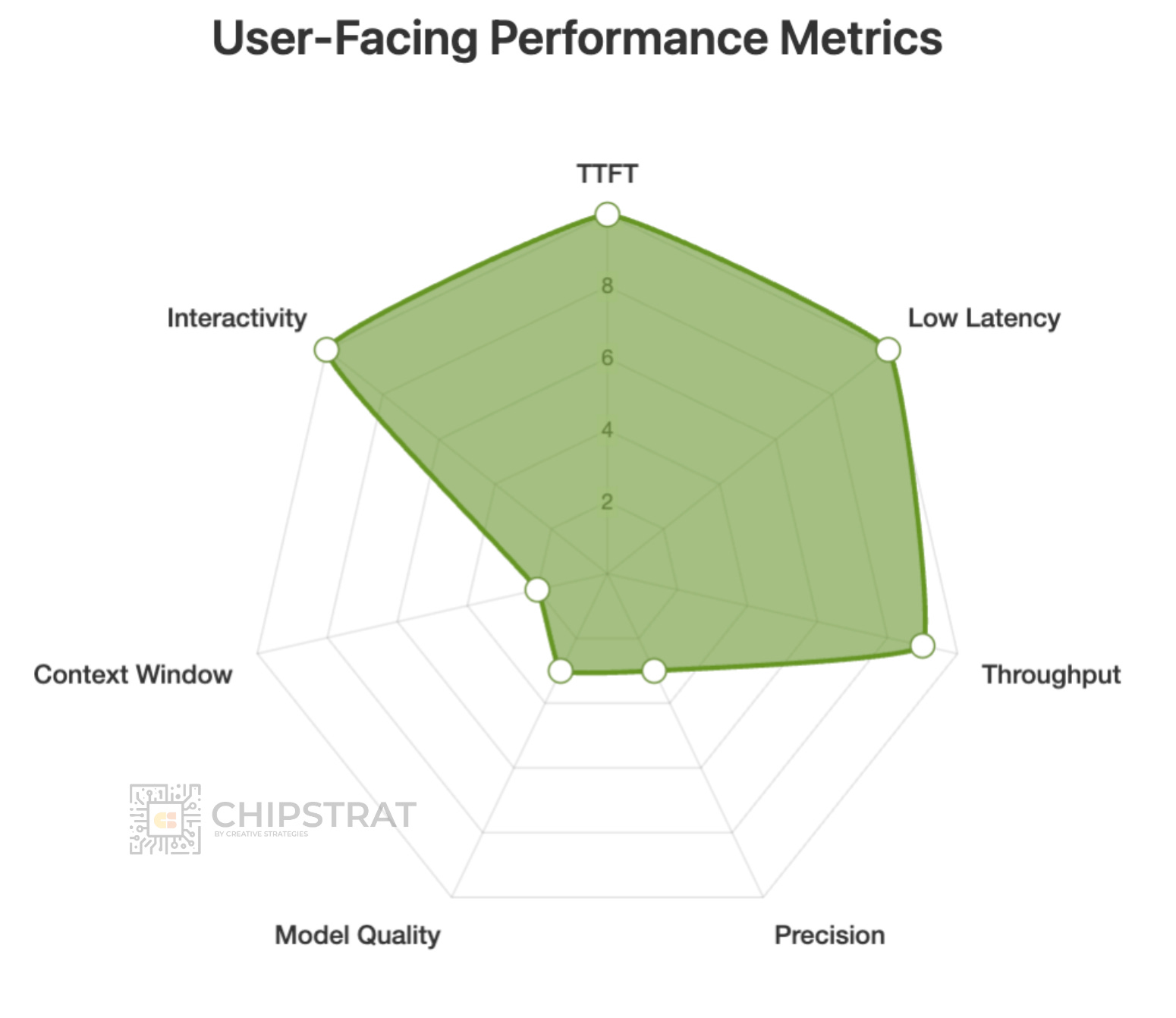
But other workloads might need super-duper low end-to-end latency, like if you’re Google and rewriting ad copy on the fly:
That needs to be FAST but the LLM can be pretty simple.
Hmmm, that looks familiar! The shape of these two workloads are fairly similar!
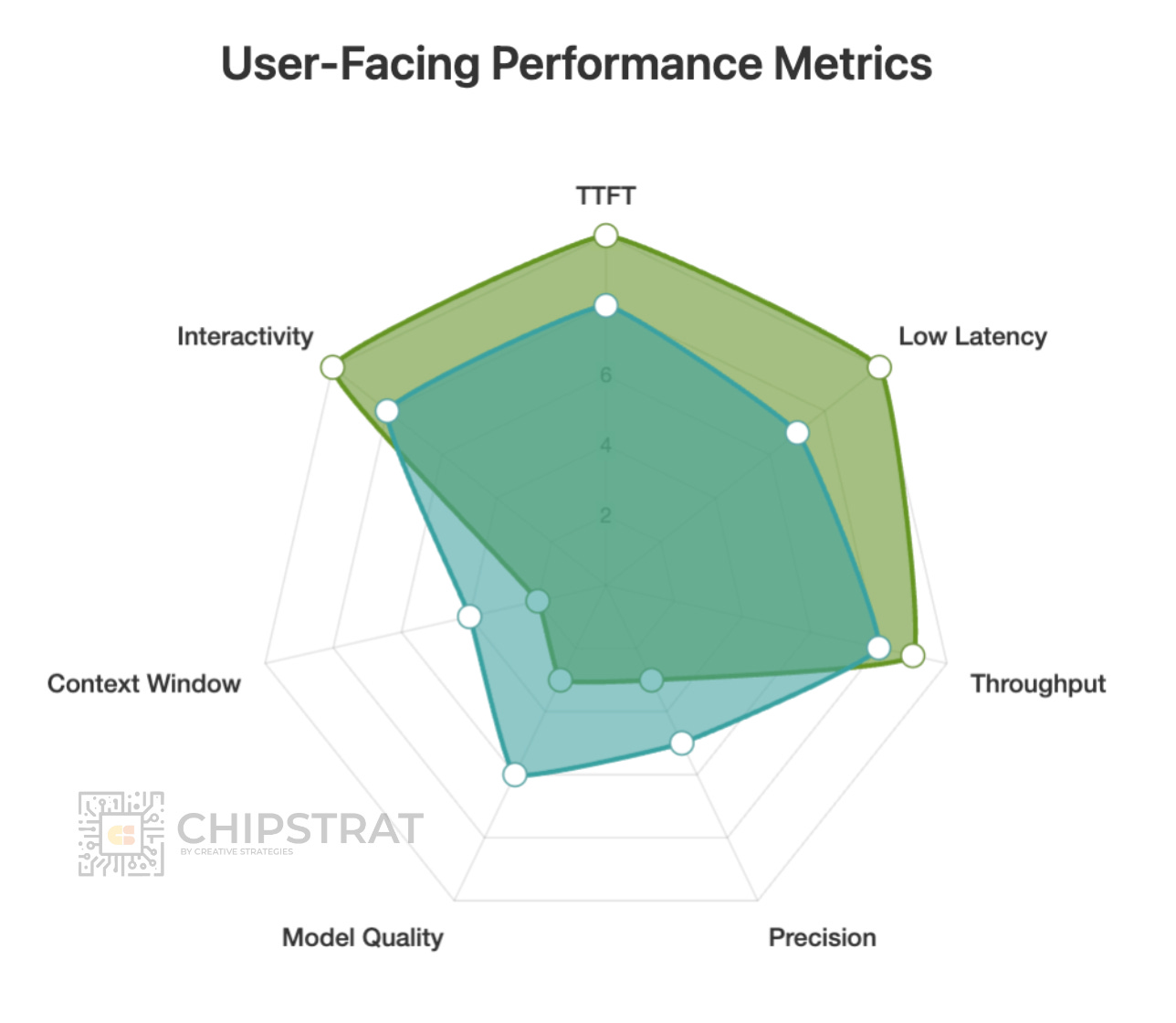
Guess what? The underlying AI datacenter system infrastructure requirements end up looking similar too!
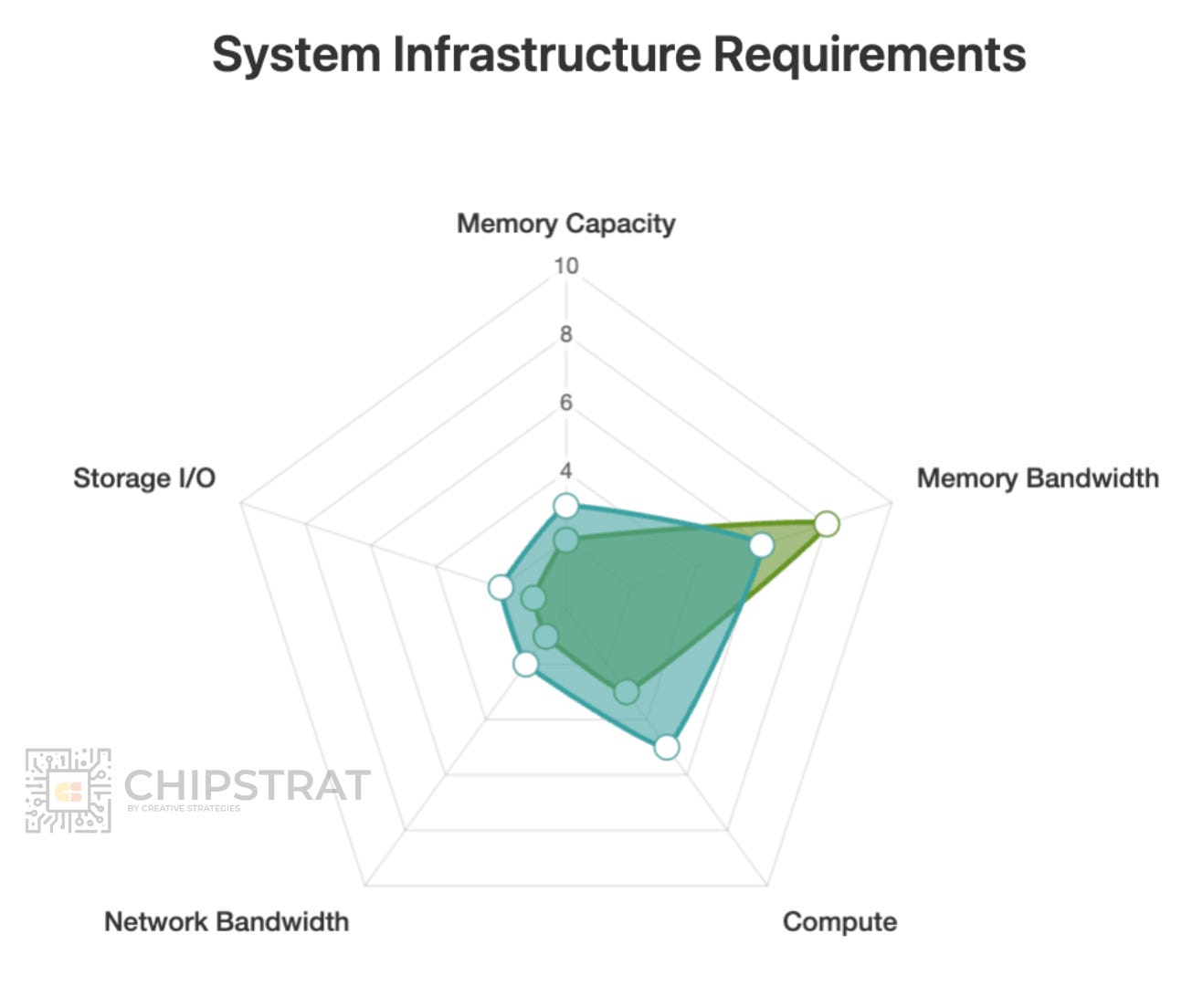
Both use cases work well with small to medium-sized models, so they don’t need huge HBM capacity. Inference traffic is modest since these compact, probably dense models don’t communicate much across nodes. Compute demand isn’t extreme eithe. The key requirement is high memory bandwidth to minimize time-to-first-token.
On the other hand, there are workloads with vastly different user requirements and translate into vastly different infrastructure requirements.
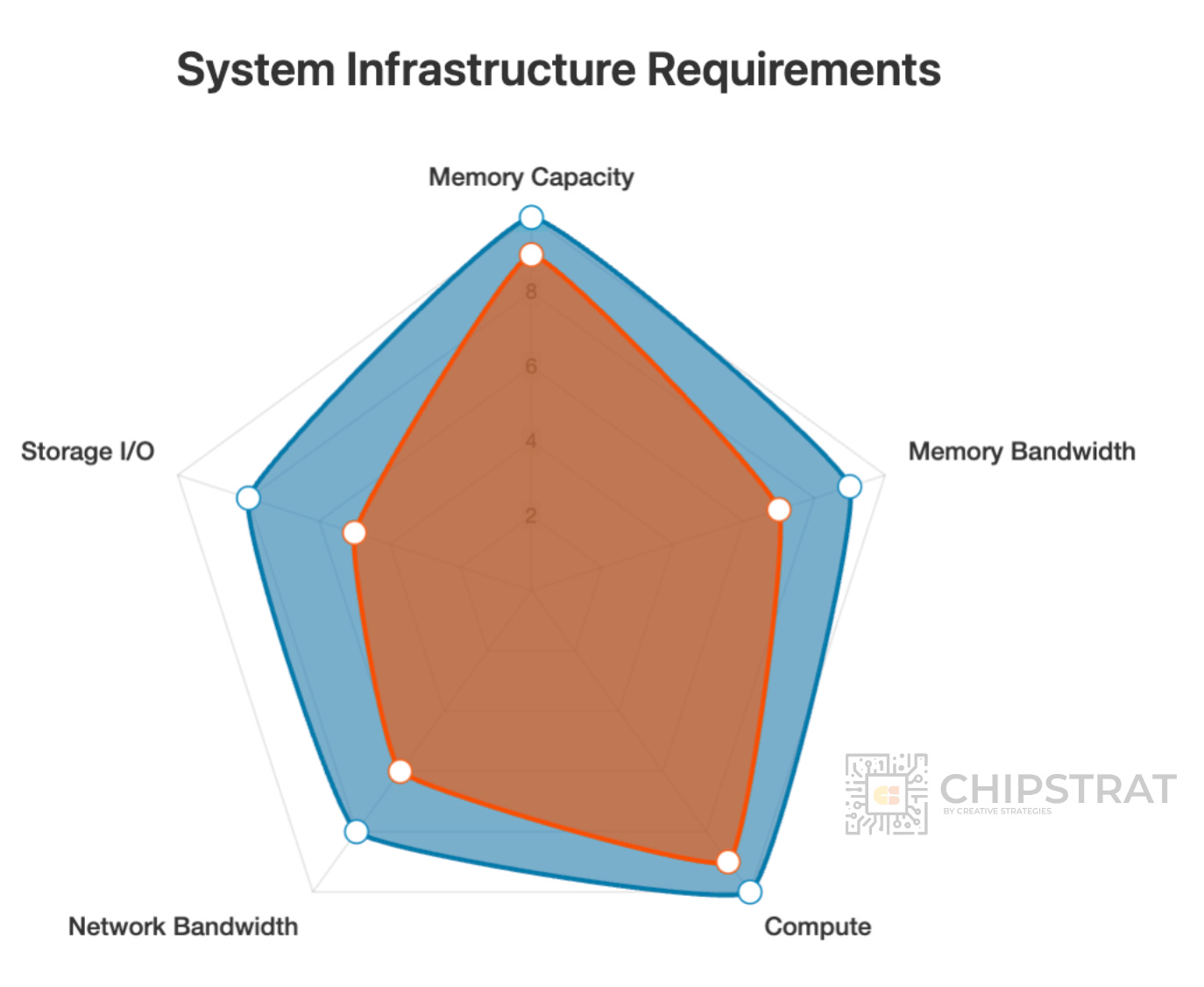
Consider a reasoning model powering an agent like OpenAI’s Deep Research. It requires massive context windows and the most capable model available, but ultra-fast response time isn’t necessary.
And as you might guess, this puts a very different demand on the system:
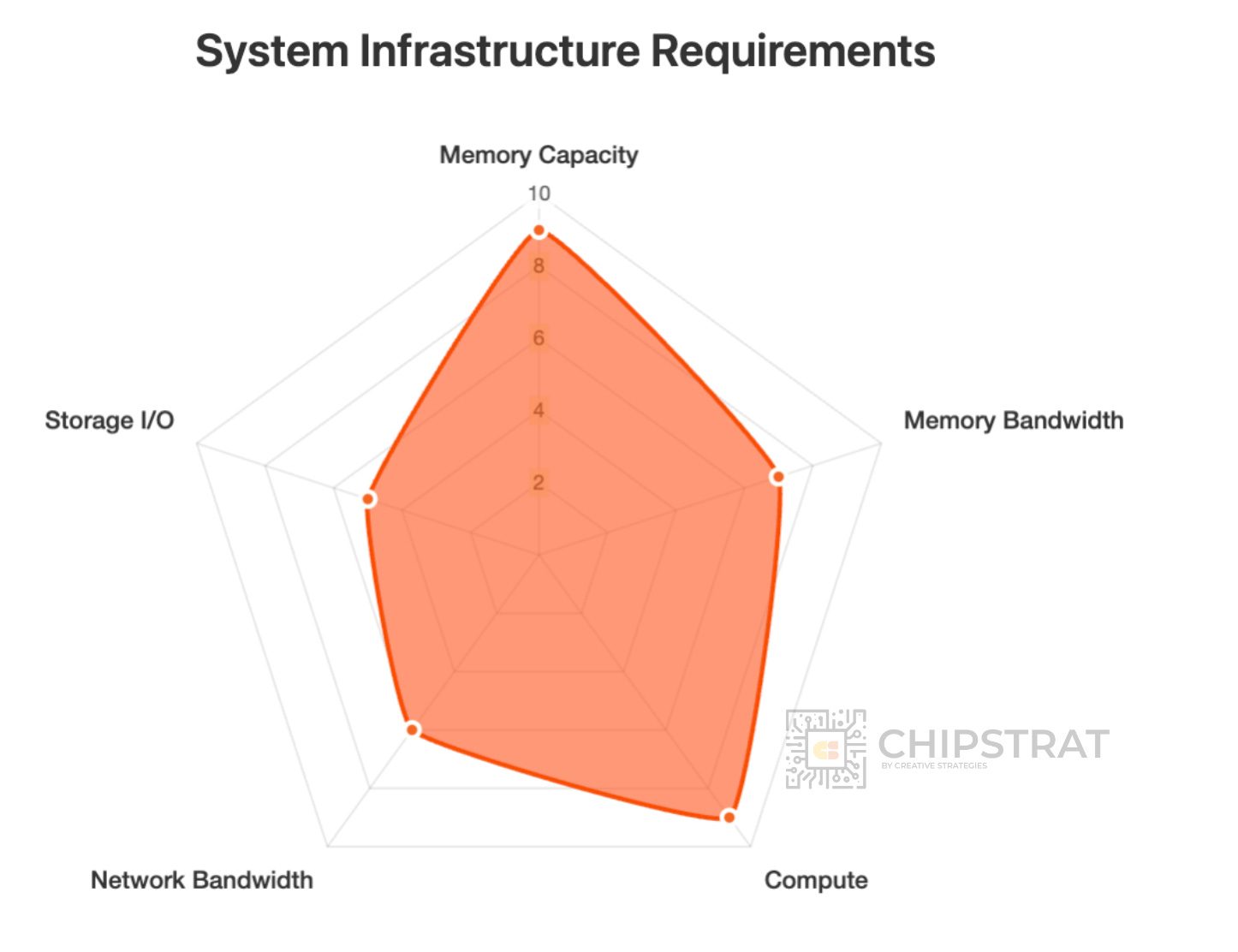
The shape of this infra is very different than the earlier workloads!
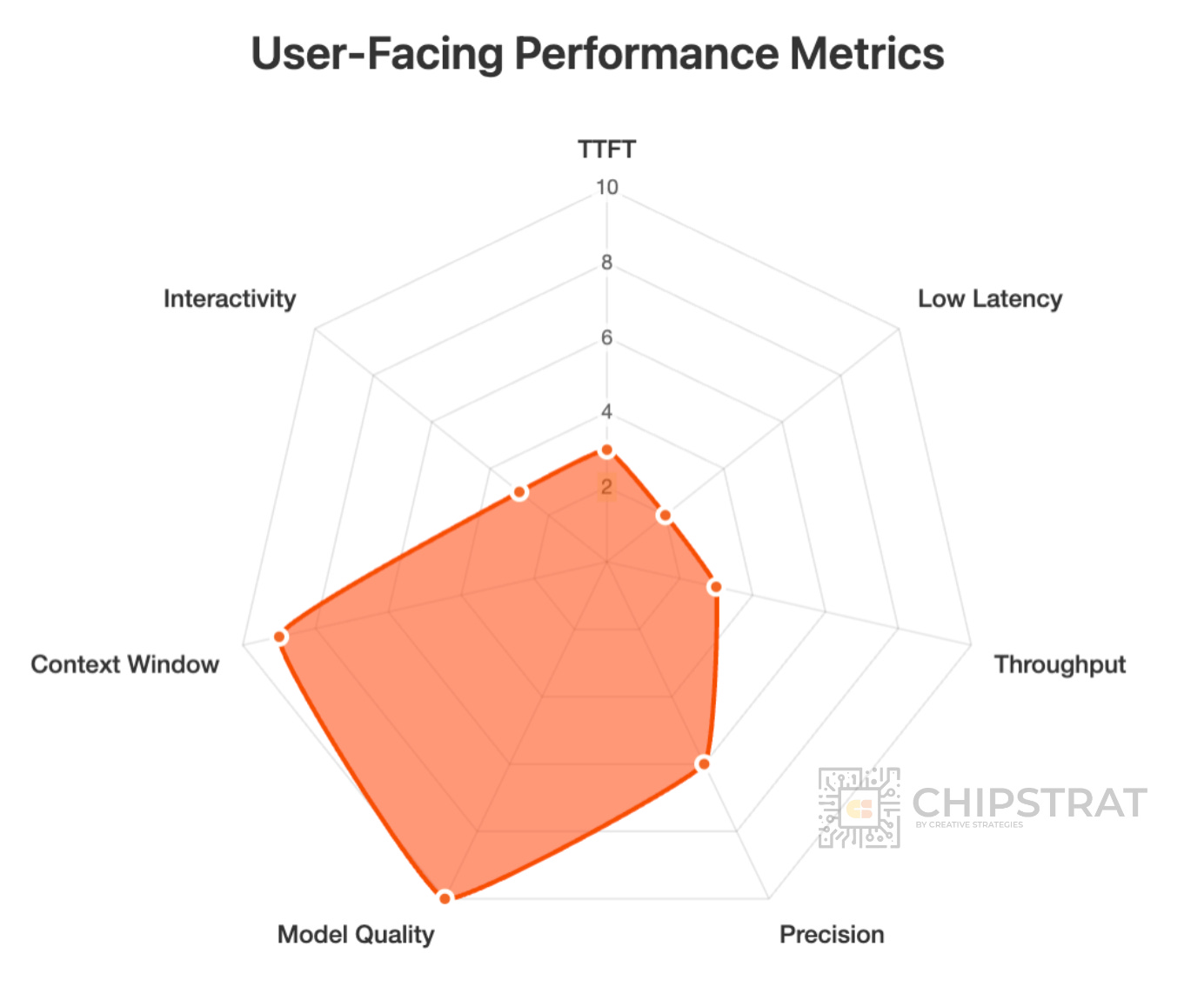
And what about video generation with Sora 2? That’s all the rage right now.
Text-to-video diffusion models are extremely compute-intensive and demand state-of-the-art models. But like Deep Research, users expect a short wait while the video is generated. It’s a reasonable tradeoff for quality.
And hey, the shape of these workloads look very similar!
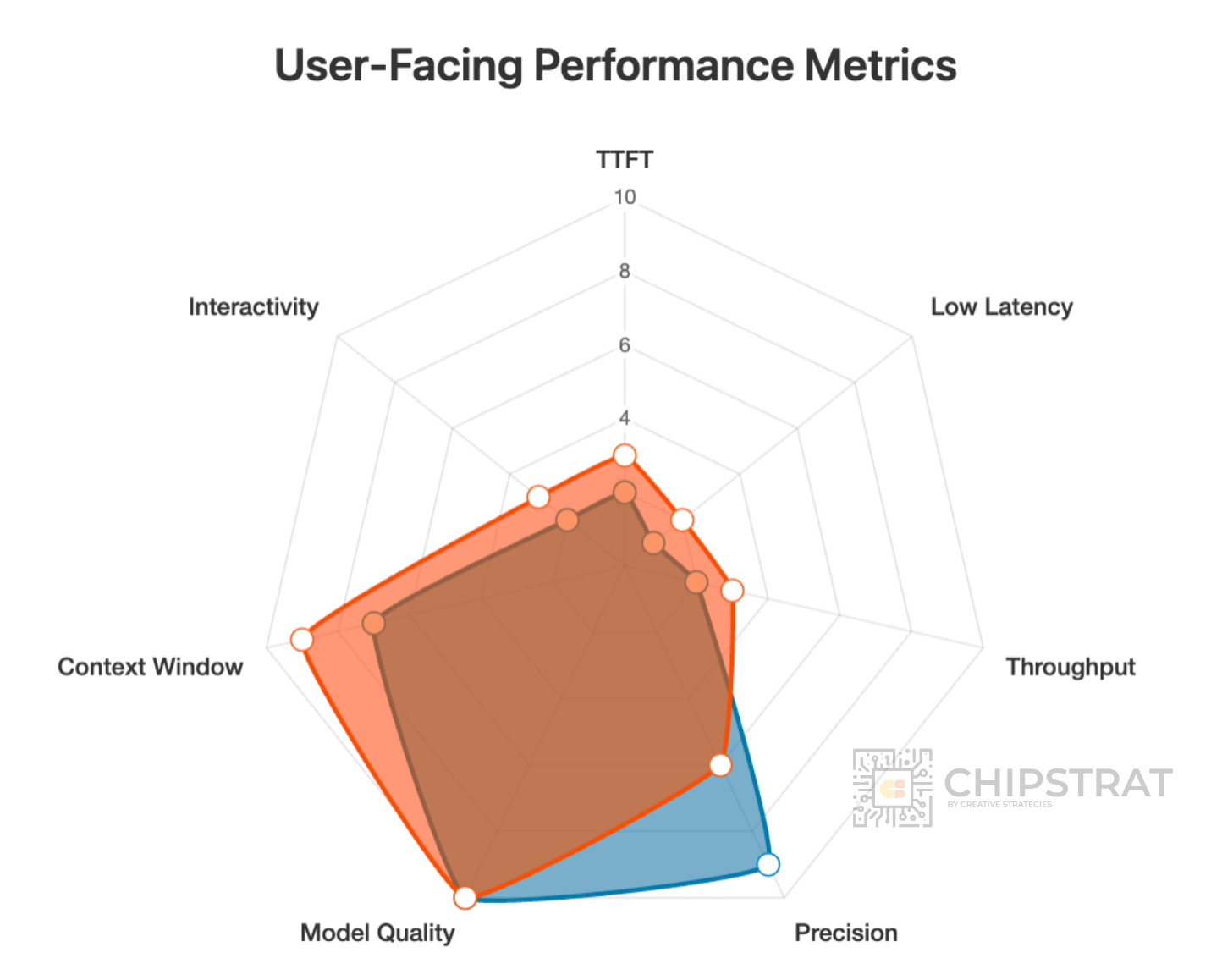
As you’d expect, the system demands and similarly shaped too.
So here’s some important takeaways.
First, GPUs are a great place for all of these workloads to land, because they are flexible enough to support all of these workloads.
BUT! Notice how there are sort of two families of workloads here, and they result in different infra demands:
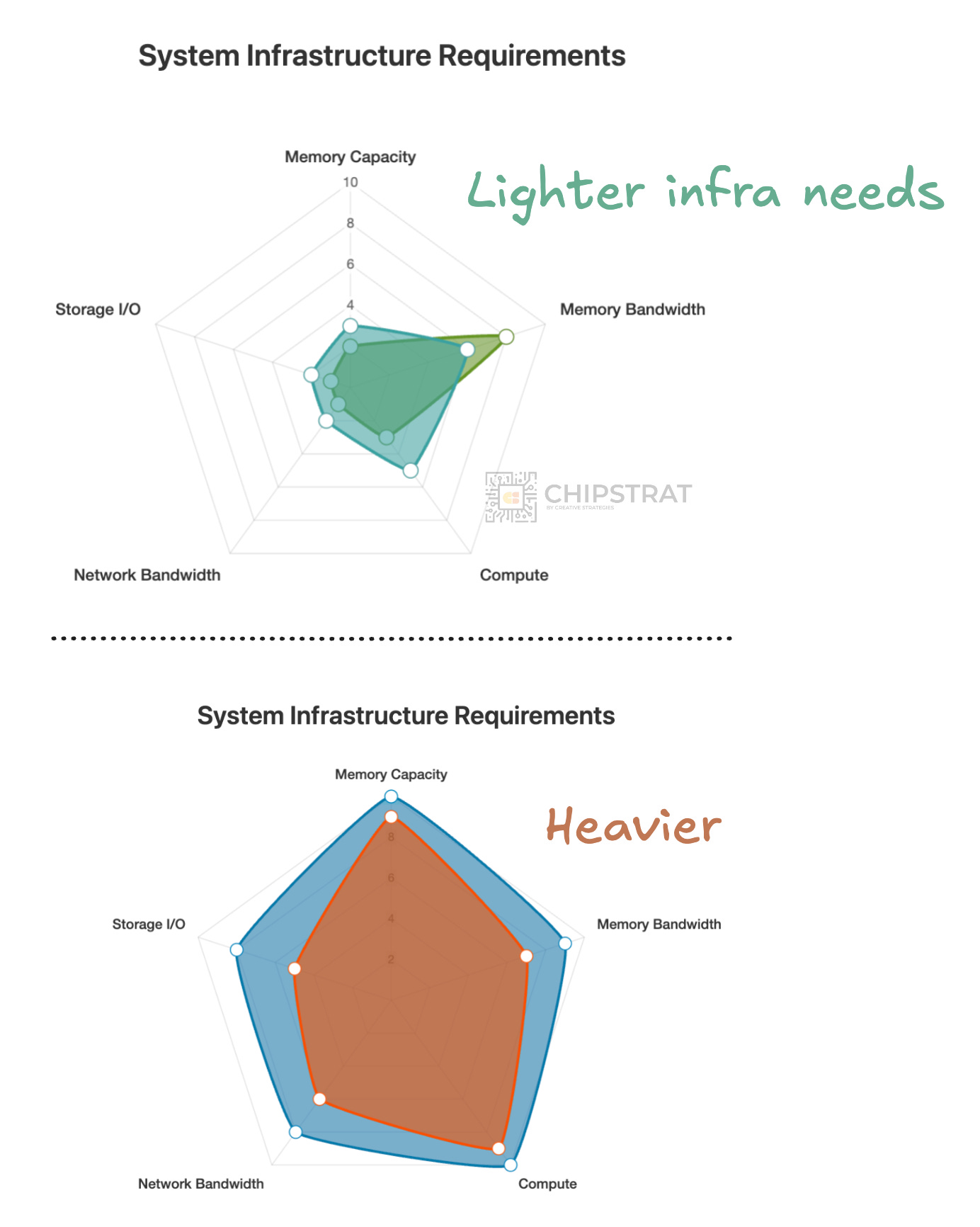
So yes, GPUs can definitely run all of these workloads, especially state-of-the-art (SOTA) GPUs.
But might it make sense to have two inference clusters here?
A cost-optimized cluster for fast, lightweight workloads
A SOTA cluster for deep reasoning and generative video
For instance, lighter jobs could run on already depreciated Hopper systems, while heavier ones move to Blackwell.
Now imagine you’re a hyperscaler serving billions of inferences a day. Wouldn’t it make sense to tune your datacenter architecture to the exact workload mix you face?
After all, even as models evolve, their infrastructure “shape” might stay similar.
AI Infra Diversity
If you’re on the AI infrastructure planning team, you’re dealing with an expanding mix of workloads and you need to assemble platforms from all the usual components we discussed: GPU, CPU, memory, networking (scale-up and scale-out), and more.
You’ve got options to choose from to build a “right size” cluster.
The simplest and often best path is a mostly turnkey system from a single merchant silicon provider, like Nvidia:
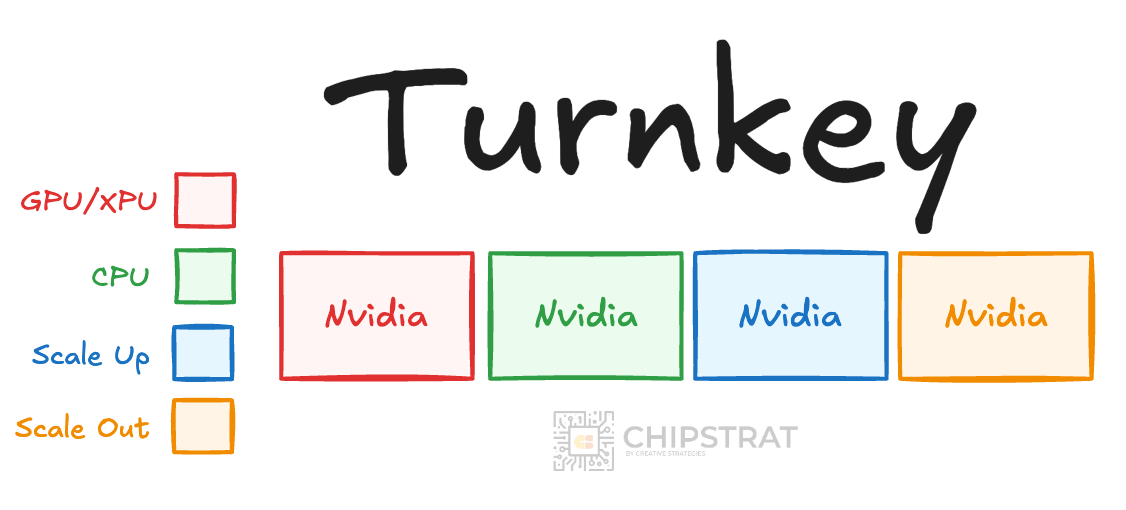
Or you can mix vendors. For example, pairing a rack-scale Nvidia platform with tightly integrated Intel CPUs, as in their recent partnership announcement.
But if you want to really customize the compute hardware to meet your needs you can work with a custom silicon vendor. Google has long done this with Broadcom for the TPU or Marvell with AWS Trainium.
So there are many options for AI infra designers. There’s a spectrum of combinations, with increasing vendor diversity.

And they all have their pros and cons across the multi-variate optimization problem: cost, supply chain diversity, speed to market, fit for the workload, and so on.

Optimizing the Infra
But won’t everyone just want the absolute best performance? Does anything else actually matter?
Well… of course performance is king… but as we saw earlier, some Cadillac systems could be overkill for the workloads when a Honda would do.
Overkill?
Something that’s often overlooked is “good enough” performance. Some workloads don’t need crazy low latency. Others don’t need crazy long context length.
Let me illustrate.
Imagine you’ve got a specific use case and you’ve defined a “good enough” performance in terms of tokens/sec; like maybe so long as performance is generally above 100 tokens/sec you’re happy.
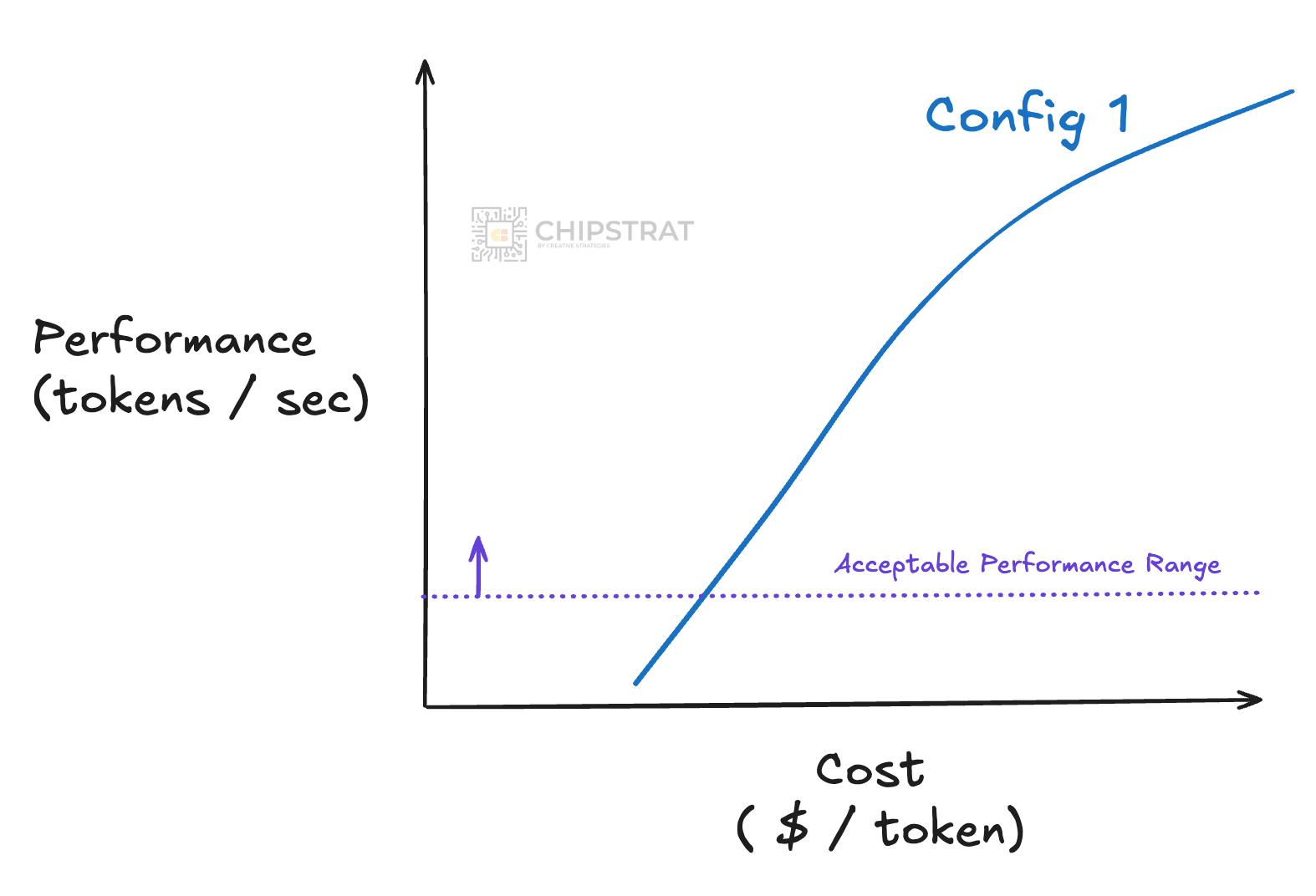
Now let’s say you take a look at the absolute best AI datacenter on the market, with all the top-shelf components. It might be expensive, but it can scale to crazy performance — 1000s of tokens/sec.
Now imagine you look at a different system configuration. Maybe not all top-tier components. Maybe it’s simply the previous generation of compute. Or it’s a lower cost compute option. Or maybe it’s still a computational beast but your workload isn’t super memory intensive so it uses cost-efficient GDDR instead of expensive HBM.
Note that this second config is cheaper, but can’t reach the same performance levels.
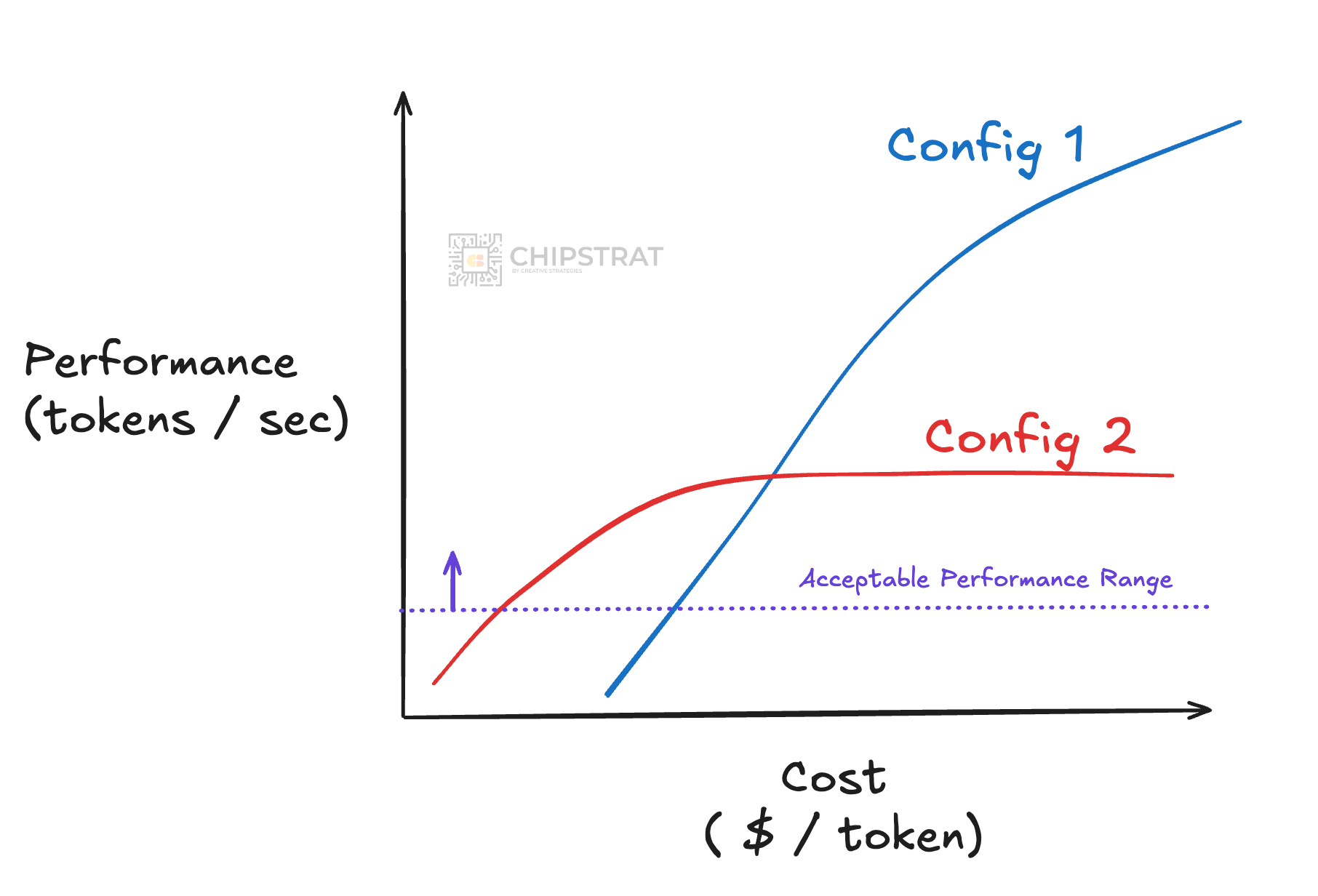
In this scenario, the second configuration can hit “acceptable performance” at a lower cost than the first configuration. In which case, this “less performant” AI cluster is just fine for your workload’s needs, as it can unlock “good enough” performance at a lower cost:
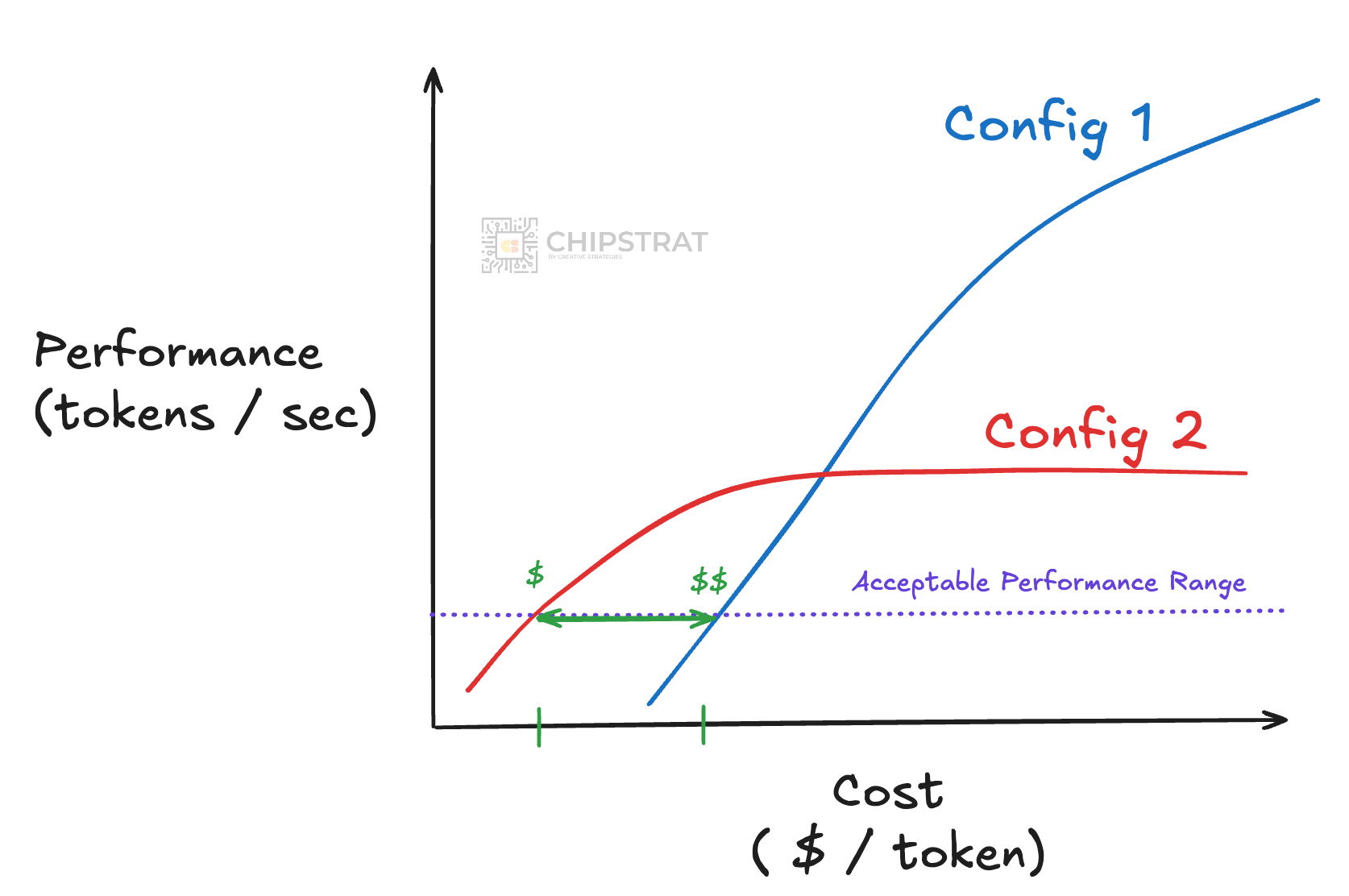
Now, note that this is an narrowly scoped example. In reality companies are balancing many different KPIs as we saw earlier – time-to-first token, throughput, tokens per Watt, etc. And a particular cluster might not run just a single workload, but a family of similarly shaped workloads.
That said, directionally, this is an example of hyperscalers tuning the system configuration to meet their specific needs.
And case in point is Nvidia’s Rubin CPX, which uses cheaper memory and cheaper packaging but fits the shape of the “prefill” portion of LLM inference quite nicely.
Sure, companies can run both prefill (compute-constrained workload) and decode (memory-constrained) on a single high-end Rubin platform…. Or they can orchestrate the workloads to run on “right size” hardware; run the prefill workload on a Rubin CPX with “good enough” memory performance using cheaper GDDR7, and save Rubin and it’s expensive HBM for the memory constrained decode workload which has a much higher requirement for “good enough” memory bandwidth.
So this shows even a single workload can be broken down into constituents that have a different shape, and each can be orchestrated to hardware that fits the shape.

I hear you. It’s time.
Marvell
OK. We’ve set the stage for the fact that
Different AI workloads impose distinct infrastructure demands.
AI datacenters are becoming more diverse in both configuration and vendor mix.
Given these, there’s now a full spectrum of datacenter designs to meet these diverse needs, from flexible turnkey merchant systems to deeply customized clusters tuned for specific workloads.
Broadcom and Marvell are the two big players helping hyperscalers design and build custom AI clusters with custom silicon tuned very specifically to the hyperscalers’ particular needs.
Curious what’s behind Marvell’s custom AI silicon story?
Behind the paywall we’ll discuss what it actually means when they talk about “XPUs” and “XPU attach”. We dissect AWS Trainium2 as an example, showing which blocks are the XPU and which are the attach.
Then we look at the business model behind those sockets, who Marvell’s customers are, why the pipeline’s accelerating, and how its full-service IP stack (SerDes, SRAM, HBM, packaging) gives it an edge over design-service shops like Alchip and GUC.