

GPU Networking Basics Part 3: Scale-Out
InfiniBand, UEC, Spectrum-X, Surprising Misconceptions

AI networking is heating up, and Chipstrat is here to make sense of it. If you’re new to the series, start with Part 1 and Part 2. In Part 3 we go deeper on scale-out networking for AI and why it matters for training at cluster scale.


We will explain why low latency and low jitter govern iteration time in distributed training. We will show where traditional Ethernet falls short and why InfiniBand became the default fabric for HPC-style, lockstep workloads.
We will also clear up common misconceptions. (No worries, I had these coming into this article too!) For example, Mellanox did not invent InfiniBand. InfiniBand is not proprietary, but rather an open standard born from an industry consortium. Mellanox, and later Nvidia, have long supported Ethernet for scale-out via RoCE and its evolution. Along the way we will define what “open” actually means in networking. And more!
We will then contrast InfiniBand with modern Ethernet-for-AI stacks such as Nvidia Spectrum-X and the Ultra Ethernet Consortium’s 1.0 spec.
Then behind the paywall we’ll examine Nvidia’s monster networking business. We will compare Nvidia’s mix across InfiniBand, NVLink, and Spectrum-X with Broadcom and Arista to show why networking is an important piece of Nvidia’s expanding TAM.
But first, context. I’ll walk through a simple example to make it clear why AI networking is a different beast than networking of the past.
If you already know the basics, feel free to skip ahead! Many readers have said they value starting in the shallow end before diving deep, so we’ll ease in there first.
AI Networking is Different
So what are the networking needs of an AI workload?
BTW: when I say AI training here, I mean LLMs and transformer variants driving the Generative AI boom.
LLM Training 🤝 Networking
At its core, LLM training is a distributed computing workload, with thousands of machines working together on a single problem.
The idea of distributed computing isn’t new. Anyone remember Folding@Home, which harnessed volunteer PCs to run protein simulations?
Vijay Pande: So in 2000 we had the idea of how we could actually use lots and lots of computers to solve our problems—instead of waiting for a million days on one computer to get the problem done in 10 days on 100,000 computers. But then you reach a sort of fork in the road where you decide whether you just want to talk about how you do it or if you actually want to do it. That’s when we decided to come up with Folding at Home, to take the idea and turn it into reality. Over the summer of 2000 we wrote the software for the very first version, and in October 2000 we publicly released it. We were lucky to get a lot of people interested at the time; back then a lot meant about 5,000 or 10,000 people. Over the years, almost eight years later, it has grown to be almost 250,000 processors actively computing and over 2 million that have contributed some work.
Today’s AI clusters are similarly expansive. Training a frontier model can involve hundreds of thousands of GPUs working in unison; each GPU handles part of the computation, then exchanges results with its peers. The moment those results need to be shared is when networking shines… or is the bottleneck!
I’m a visual learner, so let me draw a picture to emphasize the insane amount of networking that happens during LLM training. I’ll keep it simple because I can only spend *so* long on these lol. But you can extrapolate from a few interconnected machines to hundreds of thousands.
Gradient Descent & Networking
Imagine training a large language model (LLM) on four GPUs, each holding the full set of model weights in memory. Simplifications, but still pedagogically useful.
At a high level, recall that AI training is conceptually a few steps repeated over and over.
Forward pass – Each GPU processes a slice of the training examples, predicting the next token given prior context. “Four score ___” might predict “and”
Backward pass – Each GPU computes gradients, which are signals showing how the weights should change to reduce error. The prediction was “and”, which was correct. No need to tweak this.
Gradient aggregation (all-reduce) – After each GPU figures out its own tweaks (gradients), they all compare notes and average them. This way, every GPU ends up with the same instructions for how the model should change. This requires a lot of back-and-forth communication between GPUs!
Weight update – Using those shared instructions, each GPU updates its weights. Because all GPUs apply the same update, the model stays consistent everywhere. Without this synchronization, each GPU would drift and end up training a separate model.
For a deeper dive, 3Blue1Brown has an excellent gradient descent explainer.
Here’s a zany graphic I made to whet your appetite. All-reduce is the heart of distributed training. Every GPU must finish computing, contribute its gradients, and then wait for the aggregated result before moving forward.
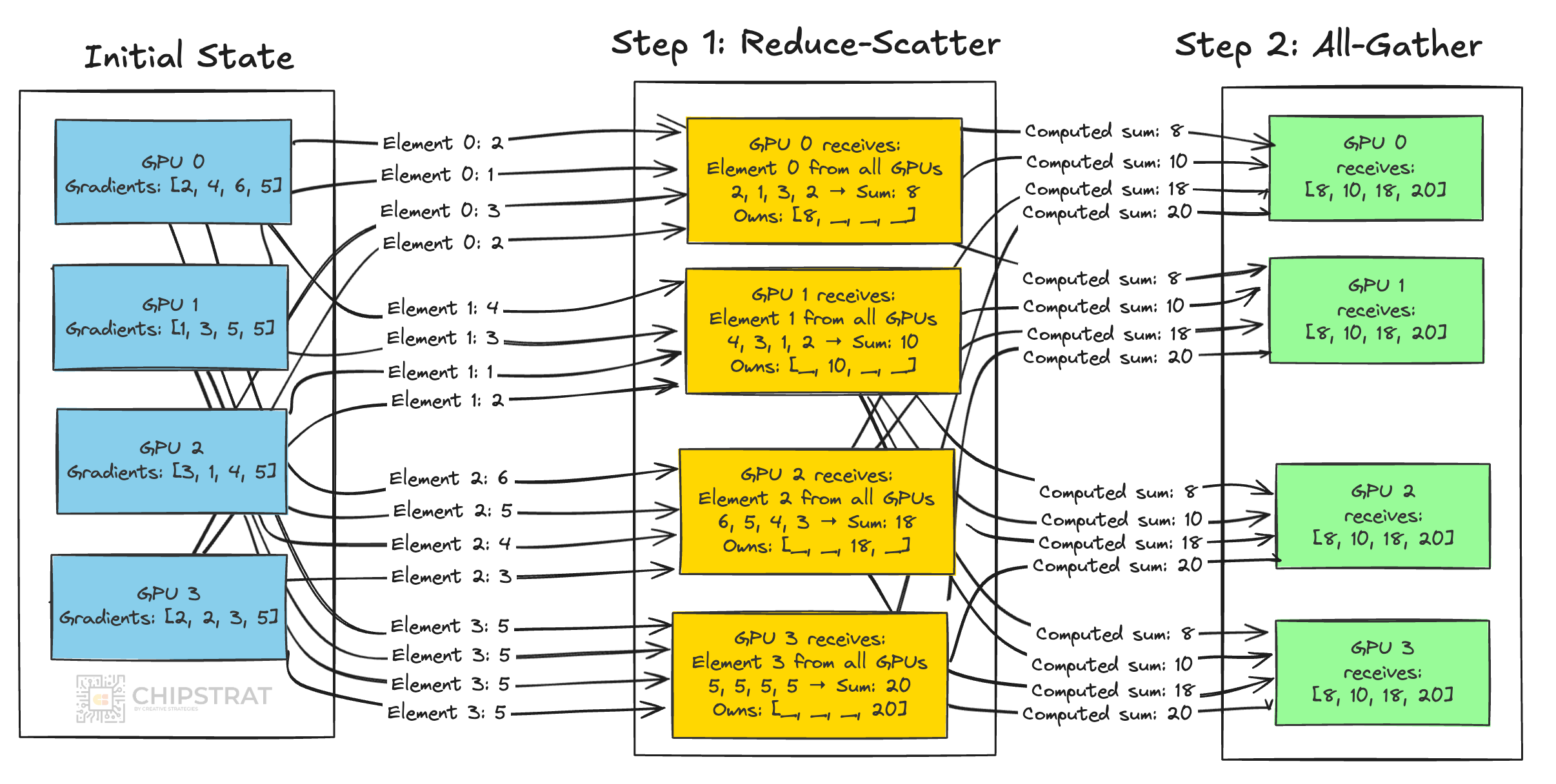
If one GPU is late, all others stall.
Imagine all the yellow GPUs in Step 1 below receiving each input at a different time; they’d have to idle until every input is received.
That’s why latency and jitter are so important in AI networking.
Latency is the one-way time for data to travel across the network, including transmission, switching, and queuing delays. With only four GPUs in this example, it’s hard to imagine delays… but at scale, with thousands of GPUs linked through one or two layers of switches, congestion happens and delays add up. AI training needs the lowest latency possible.
Jitter is the variability in latency. Think of it as the spread of arrival times in the GPUs above. Even if average latency is very low, this variability creates uncertainty about when results will arrive. AI training needs very low jitter.
Suppose a cluster of 10,000 GPUs completes an all-reduce in 40-45 microseconds, except a single straggler at 60. Not good! Every GPU has to wait those extra 20 microseconds. 9,999 GPUs waiting an extra 20 microseconds adds up to 0.2 seconds! For such massive clusters, that can be significant dollars of depreciating GPUs idling due to poor networking performance. ☠️
Deterministic, low-jitter communication is therefore essential to keep GPUs quickly advancing in lockstep.
Well, then. Can traditional networking technology fit the bill here and deliver deterministic, low-jitter communication for AI training?
Of course the answer is no 😎 Hence Infiniband, hence re-engineering Ethernet to work for AI a la Spectrum-X…. I’ll explain below.
I’m assuming most folks reading these aren’t networking gurus, so let’s take a quick pedagogical tour of common networking use cases to see why traditional Ethernet isn’t designed for this.
General-Purpose Enterprise Networks
We’ll start simple.
As you read these examples, keep in mind the core question: can this networking technology support large AI training runs with low latency and low jitter?
Most traditional networking systems were built long before distributed AI training became relevant, so their designs reflect very different use cases. It’s not as simple as repurposing an enterprise switch for an AI datacenter.
First up, enterprise.
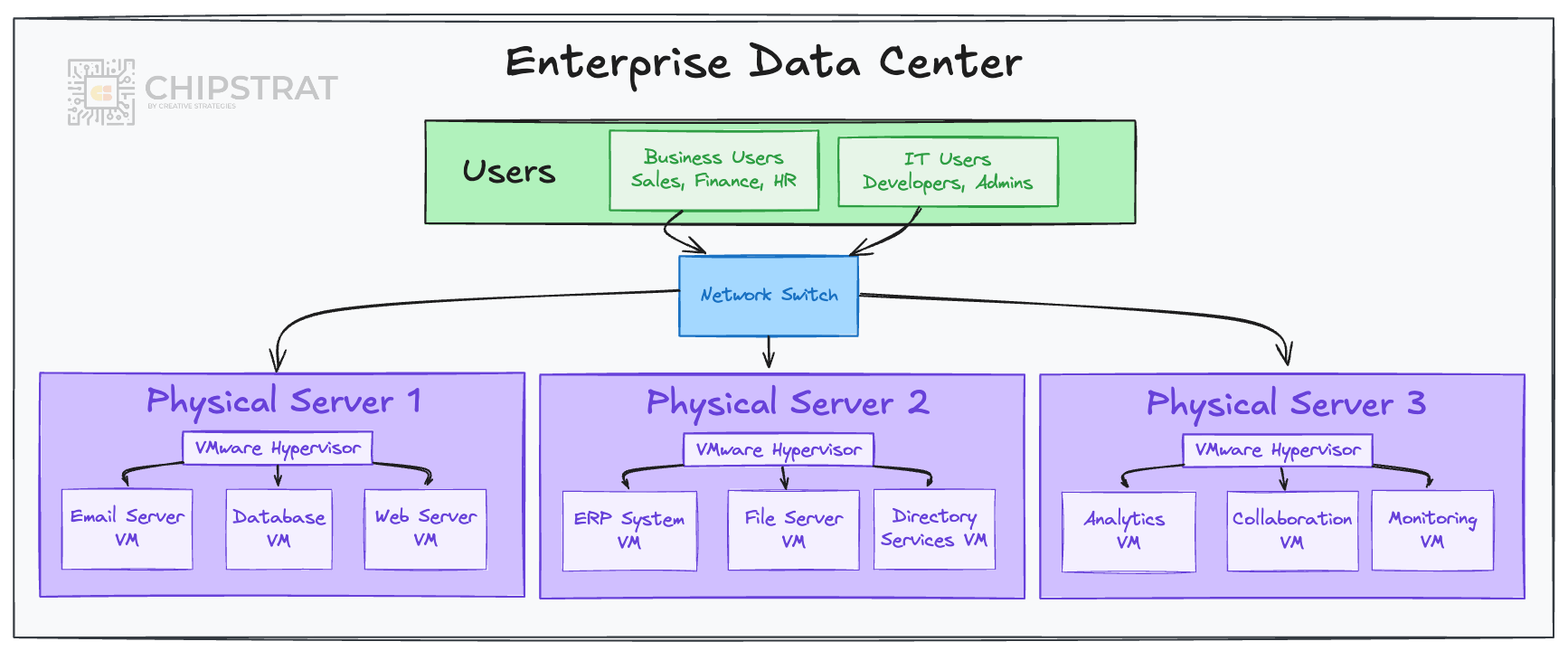
Enterprise networks run many business applications at once: think email servers, databases, ERP, CRMs, analytics, etc. These workloads typically run on powerful high-core servers hosting multiple virtual machines (VMs), with each VM running it’s own task.
The workloads often communicate with each other inside the data center, creating east–west traffic such as an analytics tool pulling from a database.
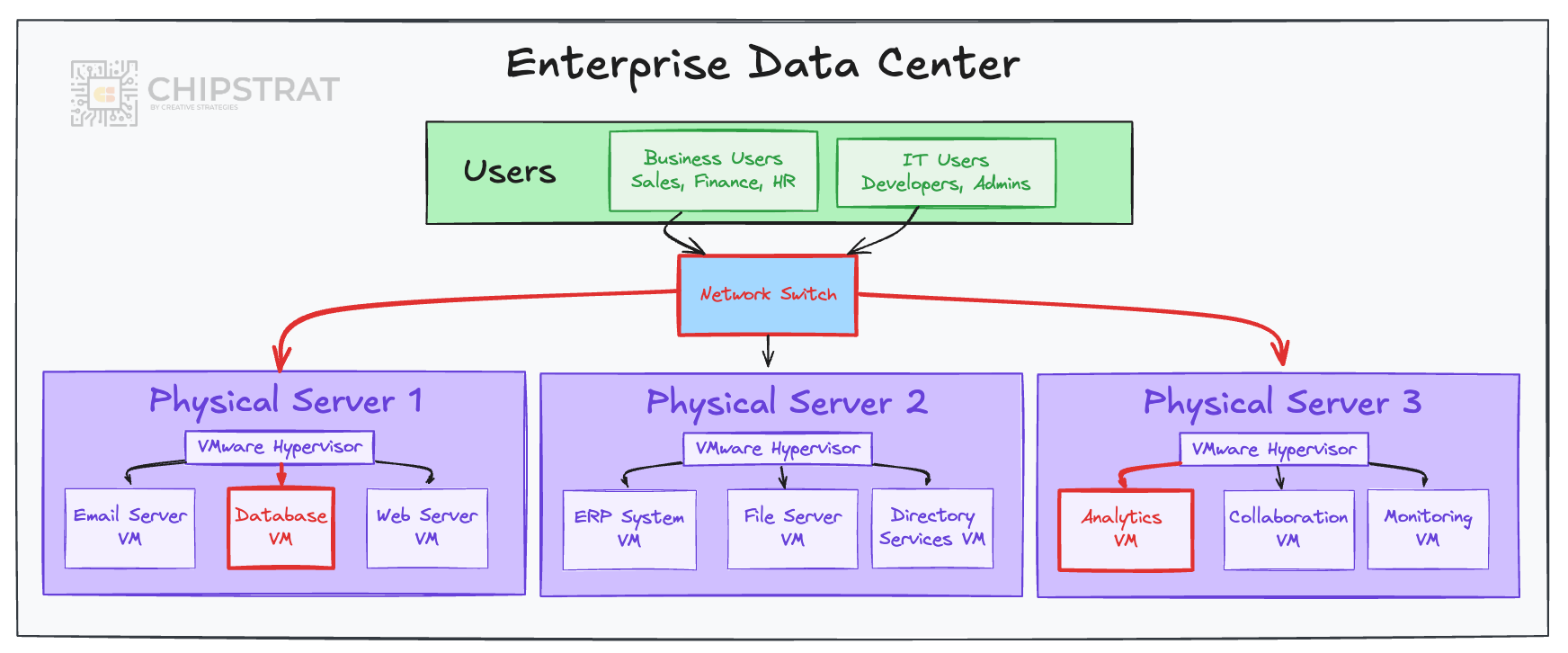
Ethernet is the default fabric here.
And the system is designed for enterprise requirements. So the switches are designed to provide security features (e.g., isolating HR systems from developers) and traffic management (e.g., keeping video calls smooth during large file transfers).
Many such networks use Broadcom’s Trident family of chips. For example, see this video with some nice monitoring features for enterprise IT folks that can be used with switches based on Broadcom’s Trident 4 chips. The video is a bit dated, but still educationally relevant.
Would enterprise networks hold up for AI training? Nope. They don’t deliver ultra-low latency or jitter, and that’s by design!
Enterprise switches emphasize features and flexibility rather than determinism. Average latency is acceptable, and jitter is tolerated because workloads are independent. A delayed packet in a database query or email transfer doesn’t stall other applications.
These networks were not built for the lockstep, low-jitter communication that large-scale AI training demands.
Hyperscale Cloud Networks
Getting closer…
Hyperscaler datacenters are built to scale a single service to millions or billions of users; think Gmail, YouTube, Netflix, or Amazon e-commerce. Thousands of servers run narrow roles such as frontends, caches, or database shards, together forming what looks a lot like a massive distributed system.
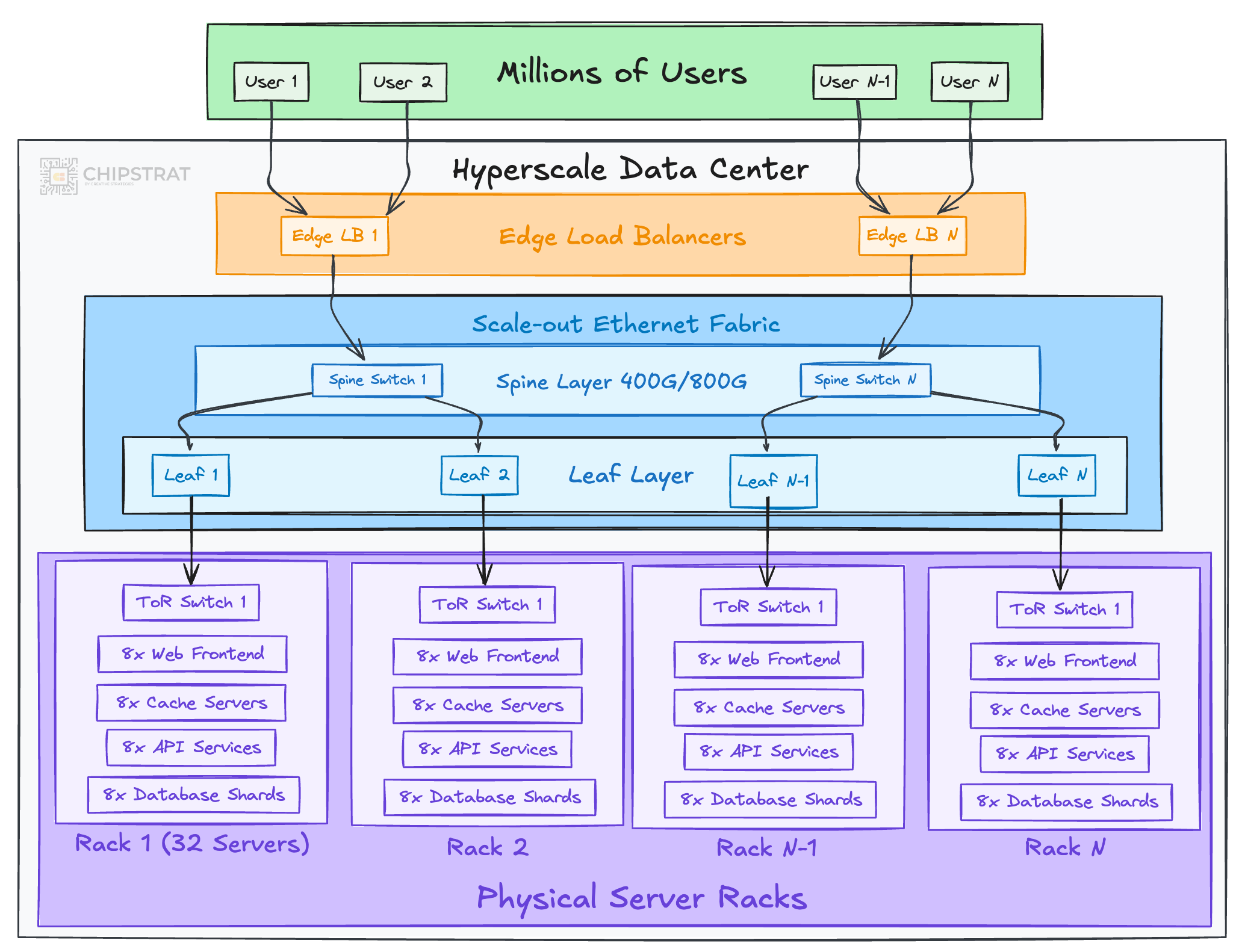
Ethernet remains the default fabric.
At this scale, cost and power efficiency dominate. Switches are designed for high radix (number of ports) and high bandwidth to move enormous volumes of traffic while consuming as little power per bit as possible.
Broadcom’s Tomahawk family is an example workhorse here. Here’s a video of a previous generation of Broadcom’s Tomahawk 4 chip that positions Tomahawk vs Trident vs Jericho (watch from ~1:50 to ~2:50).
How would these hold up for AI training?
Hyperscale networks target low average latency to keep services responsive, but determinism isn’t required.
Variability (jitter) is tolerable. A slow query can be retried, and replicas ensure resilience.
In that sense, hyperscale fabrics are a step closer to AI training than enterprise networks, since they already orchestrate large distributed systems. But they still fall short of what LLM training demands, where thousands of GPUs must remain in strict synchrony at every iteration.
Supercomputers (High Performance Computing)
You may have recently heard an increased use the term supercomputer. For example, an “AI supercomputer for Denmark” or “an AI supercomputer on your desk”.
Of course the idea of a supercomputers, or high performance computing (HPC) clusters, has been around for a long time. For example, when I think “supercomputer”, I think of Cray.

With the panels off, it looked like this:

Lots of connections between printed circuit boards there… that’s a form of networking!
Say, that photo reminds me of today’s modern AI supercomputers:

BTW, Elon’s photo shows why AI networking is hot.
Purple cables mean CRDO 0.00%↑. You can imagine how many Credo Active Electrical Cables (AECs) were used to connect hundreds of thousands of GPUs!
Colossus also has lots of Nvidia Spectrum-X switches and Nvidia SuperNICs. Nvidia networking TAM expansion!
Anyway, back to supercomputers.
They are composed of many processors that can each operate on a lot of data simultaneously (SIMD) and are useful for scientific simulations like nuclear simulations and weather forecasting. Wikipedia has a nice history of the “Top 500” list of supercomputers which has lots of relevant context.
Unlike enterprise or hyperscale environments, HPC jobs are single workloads that span thousands of servers at once. A simulation might run across tens of thousands of CPU or GPU nodes, each contributing a piece of the computation.
Sound familiar? This looks like the structure of an AI training run!
HPC workloads, like AI workloads, require constant communication between nodes to keep the entire job synchronized. To support this, HPC networks are engineered for ultra-low latency and near-zero jitter. If one node lags behind, the entire simulation stalls. Exactly the same challenge LLM training faces!
In fact….. technologies like InfiniBand were purpose-built for this HPC environment.
InfiniBand for AI workloads
From the beginning, InfiniBand targeted distributed computing where thousands of processors had to run in lockstep.
Its design reads like a checklist for AI. (We won’t get way into the weeds of each of these today… future post. But a quick overview).
Remote Direct Memory Access (RDMA): Allows GPUs (and CPUs) to read/write each other’s memory directly, bypassing the CPU and system memory, cutting out buffer copies and context switches.
Lossless forwarding: InfiniBand is designed so packets don’t get dropped (it’s lossless). It uses credit-based flow control to avoid packet drops, which prevents jitter and expensive retransmissions.
Cut-through switching: InfiniBand switches forward packets as soon as the header arrives rather than waiting for the full frame, minimizing per-hop latency.
OS bypass and transport offload: InfiniBand NICs offload transport functions (e.g., reliable delivery, congestion control) from the CPU, and applications can bypass the OS kernel to post work directly to the NIC. This reduces software overhead and latency.
And that’s why InfiniBand is great for AI training. It was built for low latency and low jitter distributed computing workloads.
As you know, Nvidia didn’t invent InfiniBand.
Oh nice, you listened to Acquired’s Nvidia episodes, very good! Yes, Mellanox was one of the greatest acquisitions of all time wasn’t it?
But did you know that…. Mellanox did not invent InfiniBand!

Yeah! I honestly assumed Mellanox invented Infiniband. Because InfiniBand is proprietary.
Oh yeah, by the way, I recently learned… Infiniband is not proprietary.

But you can only buy InfiniBand switches and cables from Nvidia, right? So it’s proprietary?
Ok, there’s a lot to unpack. Single vendor doesn’t mean proprietary. We’ll get into it.
I learned a ton about InfiniBand while researching this article. And surprisingly, there were a lot of misconceptions I myself held! So if you thought these too, you’re in good company.
Open Vs Closed
In Aspects of the InfiniBand Architecture, an invited paper for the 2001 IEEE International Conference on Cluster Computing, Gregory F. Pfister of IBM (yes, IBM!) wrote:
The InfiniBand Architecture (IBA) is a new industry-standard architecture for server I/O and inter-server communication. It was developed by the InfiniBand Trade Association (IBTA) to provide the levels of reliability, availability, performance, and scalability necessary for present and future server systems, levels significantly better than can be achieved with bus-oriented I/O structures.
Industry-standard? Developed by a trade association?
I guess Mellanox didn’t invent InfiniBand!
Let’s keep going.
The IBTA is a group of 180 or more companies founded in August 1999 to develop IBA. Membership is also open to Universities, research laboratories, and others. The IBTA is lead by a Steering Committee whose members come from Dell, Compaq, HP, IBM, Intel, Microsoft, and Sun, cochaired by IBM and Intel. Sponsor companies are 3Com, Cisco Systems, Fujitsu-Siemens, Hitachi, Adaptec, Lucent Technologies, NEC, and Nortel Networks.
Lots of other companies were at the table!
Approximately 100 individuals from the IBTA member companies worked for approximately 14 months to define and describe IBA… it should provide as much scope as possible for new invention and vendor differentiation.
Clearly, InfiniBand’s origins were anything but proprietary. It was born as an open standard hammered out in committee by the giants of late-90s computing and networking.
How did this trade association get started? According to a 2006 article in NetworkWorld:
Some of my readers may remember efforts during the 1990s by Compaq, HP and IBM to deliver a high-speed serial connection technology called Future I/O. Some may also recall a competing technology – Next Generation I/O (NGIO) – from a group consisting of Intel, Microsoft, and Sun.
Eventually the two camps merged their efforts to work on what all commonly saw as the next generation of technology for connecting servers and storage.
Originally, that combined effort was called System I/O, but that name didn’t last long. We now know it as InfiniBand.
Two competing open-standards initiatives collapsed into one, which we now know as InfiniBand.
In fact, the collaborative, open foundations of InfiniBand echo what we’re seeing today with the Ultra Ethernet Consortium (UEC). From UEC’s 2023 launch:
Announced today, Ultra Ethernet Consortium (UEC) is bringing together leading companies for industry-wide cooperation to build a complete Ethernet-based communication stack architecture for high-performance networking. Artificial Intelligence (AI) and High-Performance Computing (HPC) workloads are rapidly evolving and require best-in-class functionality, performance, interoperability and total cost of ownership, without sacrificing developer and end-user friendliness. The Ultra Ethernet solution stack will capitalize on Ethernet’s ubiquity and flexibility for handling a wide variety of workloads while being scalable and cost-effective.
Ultra Ethernet Consortium is founded by companies with long-standing history and experience in high-performance solutions. Each member is contributing significantly to the broader ecosystem of high-performance in an egalitarian manner. The founding members include AMD, Arista, Broadcom, Cisco, Eviden (an Atos Business), HPE, Intel, Meta and Microsoft, who collectively have decades of networking, AI, cloud and high-performance computing-at-scale deployments.
Both look strikingly similar! Major computing and networking players uniting to design a high-performance fabric for distributed workloads.
That’s why framing InfiniBand as “closed” and UEC as “open” isn’t quite right. Both began as open specifications drafted by industry consortia, published for anyone to implement.
Anyone could, in theory, take the InfiniBand spec and build IB switches and NICs to compete with Nvidia.
The spec is available. That’s as open as it gets.
Granted, it might not be the best business decision to build an InfiniBand startup, but it’s 100% possible.
I think this is where people get confused: Nvidia is the only vendor shipping IB at scale today, but that’s a market outcome, not a spec restriction.
To be precise, “open” in the context of AI networking implementations refers to the specification process and implementability, not the number of shipping vendors.
So what is a closed spec?
If a company writes a confidential product requirements document (PRD) for internal use only, that’s closed. If someone leaves and brings that PRD to a competitor, that’s theft of proprietary IP, even if the new design differs. That’s closed.
Obviously Ultra Ethernet has an open spec. The UEC 1.0 spec can be read for free here. Any company can read that PRD and build a solution accordingly. Astera Labs is doing just that.
But, guess what! InfiniBand has an open spec too. Granted, it’ll cost $5K to $10K to first become an Infiband Trade Association member to read it, so it’s not free, but that doesn’t make it “closed”.
In fact, the University of Wisconsin library has the InfiniBand 1.0 spec available to patrons as a two-volume book, and I’m guessing you can check it out via interlibrary loan. Shoot, I just looked it up via interlibrary loan and there’s a copy sitting up the road from me on a shelf at Iowa State University.
So yes, access may require a library card or trade group dues, but the spec itself is not closed. It’s not the proprietary property of a single company.
My earlier notion that InfiniBand was “closed” was wrong!
Would you look at that! Just look at that. You just gotta look at it this way. That’s all you can do anymore…
InfiniBand Roots
Anyway, back to InfiniBand. The original InfiniBand consortium ended up introducing many technologies that are incredibly important for today’s AI training workloads.
So how did it end up being associated with Mellanox?
An archived 2004 blog post by Dr. Ted Kim offers a firsthand account. Ted was coauthor of the InfiniBand 1.0 spec while at Sun Microsystems.
Ted recalls how the dot-com bust and Intel’s pivot to PCI Express triggered an InfiniBand fallout:
For a while, InfiniBand was hot. Interest grew. Lots of startups sprang up. Everyone touted their IB roadmap. Then the bubble burst. It wasn't just IB -- it was the implosion of the dot com boom, stock market adjustment, cautious corporate IT spending, the recession, 9/11, etc. The net effect was that no one was in the mood to adopt or invest in such a far-reaching technology jump. So, a lot of renewed skepticism emerged.
Then the other shoe dropped. Intel decided to discontinue IB chip development, though they continued to promote the technology. Why did they do this? I can only speculate. Their intial development was based on 1x links, which seemed to miss the mark (4x became the most popular size). Intel was not immune to R&D; fiscal pressures also and so needed to shift resources to help with PCI-Express development. Further, they may have also have reacted to less favorable market conditions for IB acceptance. In any case, the loss of Intel's product made many feel that the IB market would not have sufficient volume. This led to a raft of vendors delaying or retrenching their IB roadmaps. Microsoft left the IBTA for the RDMAC (more on that later). Startups merged and failed. A stark reality set in. Folks at SIGCOMM 2003 asked me: "Isn't InfiniBand dead?"
So it seems InfiniBand almost died! Ted continues,
Fast forward to today. After much gloom and doom, IB seems to be making a come back in select markets…
Mellanox was one of those startups that persevered and keep on working on Infiniband for HPC even during the dark days after the dot-com crash.
By the way, if you’re looking for a networking guru, it seems Ted wrapped up work with SambaNova recently and is open to work per his LinkedIn.
InfiniBand became the gold standard for HPC workloads, as demonstrated by it’s use by most of the world’s largest supercomputers on TOP500 supercomputers list over the past decade.
Ethernet for HPC/AI
And as you might guess, until recently, very few supercomputers used Ethernet for HPC networking.
Yet given the ubiquity of Ethernet, since the earliest days of Infiniband, folks have been asking “why not just use Ethernet”?
From that 2001 IBM paper,
A question that is regularly asked about InfiniBand Architecture in general is “Why do we need yet another network architecture? Why not use Ethernet and IP?”
As we’ve discussed, Ethernet wasn’t designed for high performance distributed computing workloads.
That is, until RoCE (RDMA over Converged Ethernet) was born. Lovely, an acronym (RDMA) within an acronym (RoCE), lol.

RoCE effectively brought InfiniBand verbs into the Ethernet world. These verbs are the basic operations exposed to software for RDMA, i.e. read (pull data directly from a peer’s memory), write (place data directly into a peer’s memory), and send/receive (message-style communication). They allow GPUs to move data between each other’s memory without CPU involvement.
And, get ready for it:
Mellanox helped write the RoCE spec and the InfiniBand Trade Association championed it!

Wait. I thought the narrative was:
Mellanox sold out to Nvidia
Nvidia only cares about “proprietary” Infiniband/NVLink
Nvidia forces customers to buy InfiniBand/NVLink via bundling (but don’t use that b word!)
Instead, it seems that Nvidia’s networking folks with Mellanox roots have long been supporters of Ethernet for distributed computing.
From a 2009 HPCWire article titled An Ethernet Protocol for InfiniBand:
It’s inevitable that lossless Ethernet will work its way into the datacenter… But since the technology behind lossless Ethernet is coming to resemble InfiniBand, vendors like Voltaire and Mellanox are using the convergence as an opportunity to enter the Ethernet arena. “We’re not naive enough to think the entire world is going to convert to InfiniBand,” says Mellanox marketing VP John Monson…
“We believe than that there is already an RDMA transport mechanism that’s been proven and used heavily in the industry,” declares Monson. “It’s called InfiniBand.”
According to him, you might as well use similar functionality inside an Ethernet wrapper if your goal is 10 GigE with lossless communication. Mellanox is calling its prototype RDMAoE implementation Low Latency Ethernet (LLE), but for all intents and purposes it’s InfiniBand over Ethernet…
The InfiniBand veterans took what they learned and applied it to Ethernet, showing how those lessons could make Ethernet better suited for HPC (and AI).
“Essentially what you’re able to do now is run close to InfiniBand-like latency over 10 Gigabit Ethernet,” says Brian Sparks, IBTA marketing working group co-chair and director of marketing communications at Mellanox . “But you don’t have the InfiniBand barrier and the learning curve that goes with that.”
RoCE isn’t quite InfiniBand-strength, though. QDR IB nets 32 Gbps and sub-microsecond latencies, while RoCE is currently limited to 10 Gig and latencies closer to single-digit microseconds. For most apps, though, 10 Gig is plenty of bandwidth…
For customers that prefer Ethernet, with RoCE they could start to get features and performance more akin to InfiniBand. Not as performant, but headed in the right direction.
One might wonder why the IBTA and its InfiniBand-loving members decided to push an Ethernet protocol at all. If RoCE is successful, there’s bound to be some cannibalization of the InfiniBand market. But that’s the wrong way to think about it. First, there are no InfiniBand vendors anymore, at least not in the strict sense. All these companies — Mellanox, Voltaire and QLogic — offer Ethernet products of one sort or another. The market decided some time ago that IB technology would only spread so far. RoCE is another way for these vendors to reach customers they couldn’t attract before. The calculation is that there’s enough daylight between RoCE and InfiniBand to support the viability of both technologies.
That line still holds: “RoCE is another way for these vendors to reach customers they couldn’t attract before.” I’d stand by it even 15 years later, now in the context of LLM training and inference. The largest customers prioritize performance above all. Others look for a balance of performance and cost. And some enterprises prefer to stay with what they already know.
And there’s proof the ITBA has been also championing Ethernet for HPC/AI for over a decade for those who prefer Ethernet, per a 2015 article from the ITBA:
The InfiniBand® Trade Association (IBTA) today announced the launch of the RoCE Initiative to further the advancement of RDMA over Converged Ethernet (RoCE) technology and promote RoCE awareness…. “The RoCE Initiative expands our potential audience and will enable us to deliver solution information and resources to those requiring the highest performing Ethernet networks”…. The RoCE Initiative draws together members of the IBTA dedicated to demonstrating the performance and efficiency advantages of the technology and the value of a competitive multi-vendor ecosystem. ”
A decade ago they already had a vision for a multi-vendor ecyosystem… and it’s coming to fruition with Ethernet for AI networking from others beyond Nvidia.
The foundations of this ecosystem were started with a version two of RoCE with even more features for HPC/AI workloads called RoCEv2.

The new Ethernet-for-AI stacks like Nvidia’s Spectrum-X and the Ultra Ethernet Consortium’s UEC 1.0 spec build directly on RoCEv2 while preserving RDMA semantics and addressing its shortcomings. We’ll unpack these innovations in detail in future articles.
Nvidia’s Ethernet for AI
So Infiniband today is a open-standard spec with a single vendor supplier.
But guess what, Nvidia sells Ethernet for AI/HPC as well called Spectrum-X. Well played.
Here’s a short video, and you should be able to grok some of it now!
As this video shows, couples Nvidia’s Spectrum-X includes switches and DPUs/ SuperNICs tuned together as a “full-stack fabric” for GPU clusters.
I’ll save the deeper dive on Spectrum-X and its companion Spectrum-XGS for another post. (At this point, I think we’ll have a long-running series on GPU networking. I won’t write about networking every post of course, but I’ll keep weaving it in so we can gradually build a complete picture of how AI networks work.)
Nvidia’s Silicon Strength
I went down a rabbit hole on scale-out and stumbled on an underappreciated strength of Nvidia’s silicon strategy.
Nvidia designs seven different chips.
One is the GPU, one is an Arm-based CPU, and the other five are networking chips.
Would you look at that!

That networking depth matters. It’s why Broadcom can credibly build custom AI ASICs for hyperscalers, as it already has the networking expertise to stitch accelerators together.
Nvidia’s counterpoint, of course, is whether custom ASIC vendors can keep pace not just with the rapid cadence of AI accelerators but also with the equally fast evolution of networking. Can Broadcom + hyperscaler internal chip team keep up?
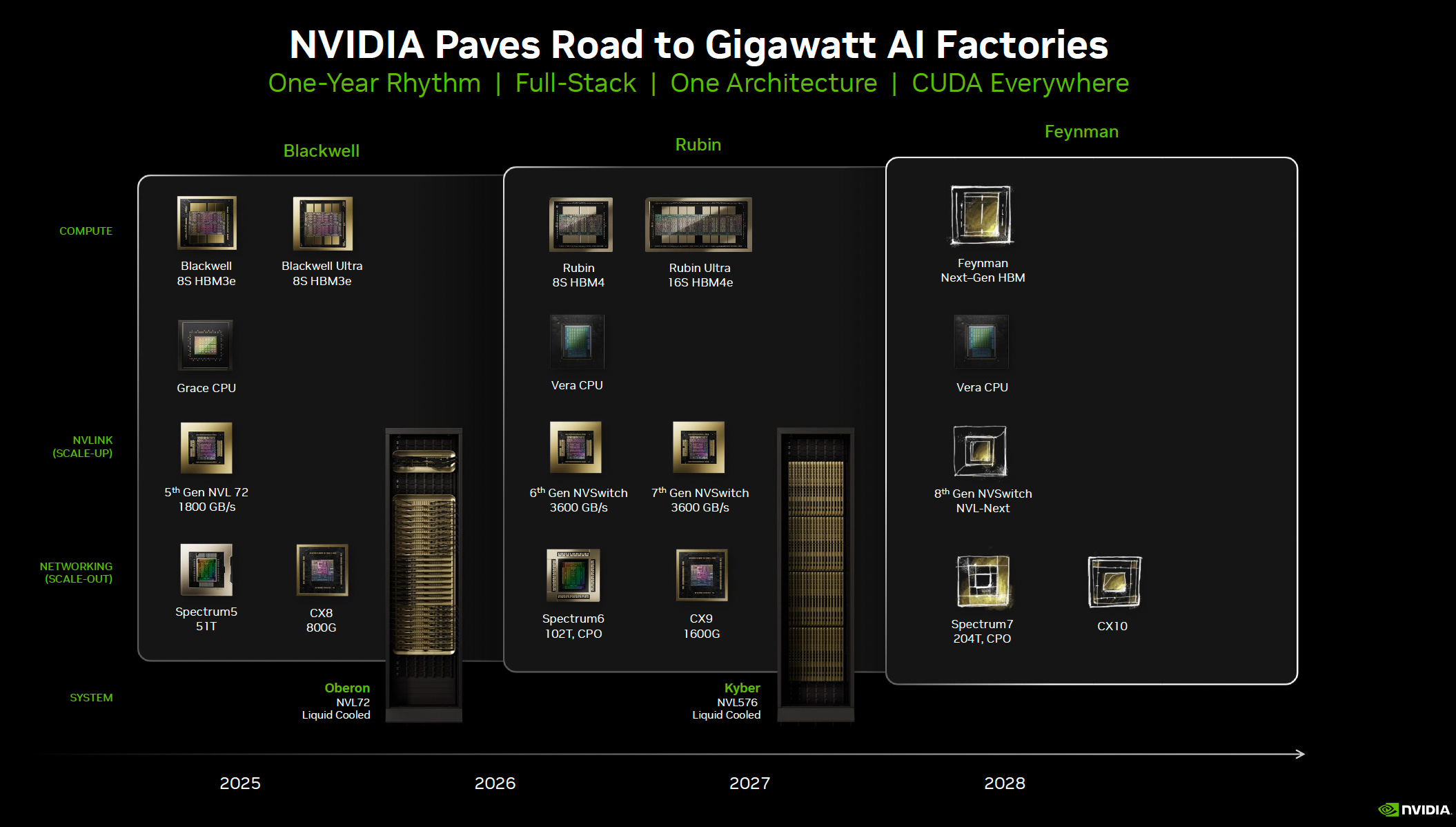
AMD, by contrast, has GPUs and CPUs but depends on the broader ecosystem—UEC and UALink—for competitive scale-up and scale-out solutions. Their bet is that networking specialists can innovate quickly enough and in lockstep with AMD to keep pace at the systems level.
Nvidia’s Networking Businesses
I still think Nvidia’s networking engineering depth is underappreciated.
And so is the business strength that comes with it.
Part of the problem is disclosure. Nvidia’s networking revenue is still buried inside the data center line item, though it has started breaking it out in select earnings slides.
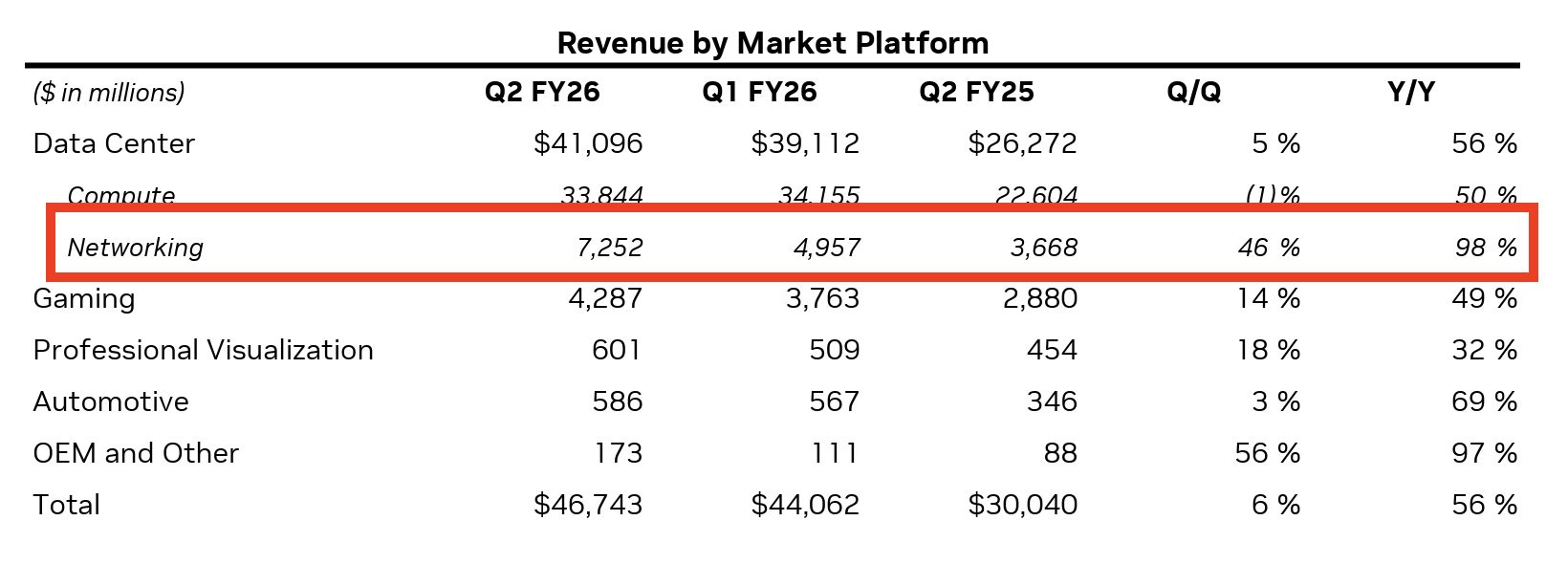
As this graphic makes obvious, Nvidia’s networking growth numbers are staggering.
For paid subscribers we’ll dig deep into this business unit, including how it compares to the AI networking pieces of other companies like Broadcom and Arista.