

GPU Networking Basics, Part 2
Front-End & Back-End, North-South & East-West Traffic, DeepSeek Example

We’re continuing with our very gentle introduction to GPU networking. Catch up with Part 1 if you missed it:

Front-End vs Back-End
Last time, we discussed GPU-to-GPU communication during the pretraining of a large language model. We focused on the fast, high-bandwidth connections to nearby neighbors (e.g., via NVLink) and the slightly slower, lower-bandwidth connections to further nodes via Infiniband or Ethernet and a network switch.
This GPU-to-GPU communication network is called the back-end network.

These all-important GPU interconnects often draw all the attention but are only one part of the broader networking system.
Consider how data reaches the GPUs during training. LLMs must ingest trillions of tokens from storage (SSDs) for the neural net to train on. This communication is done through a separate, Ethernet-based front-end network.
Many other workloads traverse the front-end network, too, such as cluster management software and developers remotely accessing the cluster for debugging.

The front-end network is deliberately separated from the back-end to prevent interference and congestion. Routine tasks like loading data or logging are kept off the high-speed GPU network, ensuring that non-critical traffic doesn’t disrupt the network on which expensive training runs depend.
Since front-end devices can be outside the data center, firewalls and access segmentation policies are often needed to isolate the back end from front-end-originated traffic. That’s acceptable because front-end traffic is typically latency-tolerant.
North-South vs East-West
Communication between GPUs and devices on the front-end network is called North-South traffic.

This North-South traffic occurs over Ethernet.
Why Ethernet? It’s cheap and ubiquitous. Front-end devices are already are built to run on standard Ethernet networks, and datacenter operators know and love Ethernet.
Can you guess what traffic within the back-end network is called?
Yep, East-West traffic.

East-West traffic is latency-optimized for GPU-to-GPU scale up and scale out communication. In the largest-scale training, this back-end network can even span multiple data centers! 🤯
As I said before, reality is much more complicated than my simplistic drawings 😅
But the simple understanding you’re gaining is the foundation for understanding the nuance and complications.
Checkpointing & Direct Storage
As an example of nuance, during LLM pretraining, model checkpointing is the practice of periodically saving a snapshot of the model’s parameters to persistent storage. These checkpoints allow training to resume from the last known good state in case of hardware failure and provide versioned artifacts.
If these large checkpointing writes of tens or hundreds of GB at a time are sent over the front-end Ethernet network, they risk colliding with other less essential traffic, causing congestion and unnecessary training stalls. To avoid this, AI training clusters can connect dedicated high-speed storage directly to the back-end network:
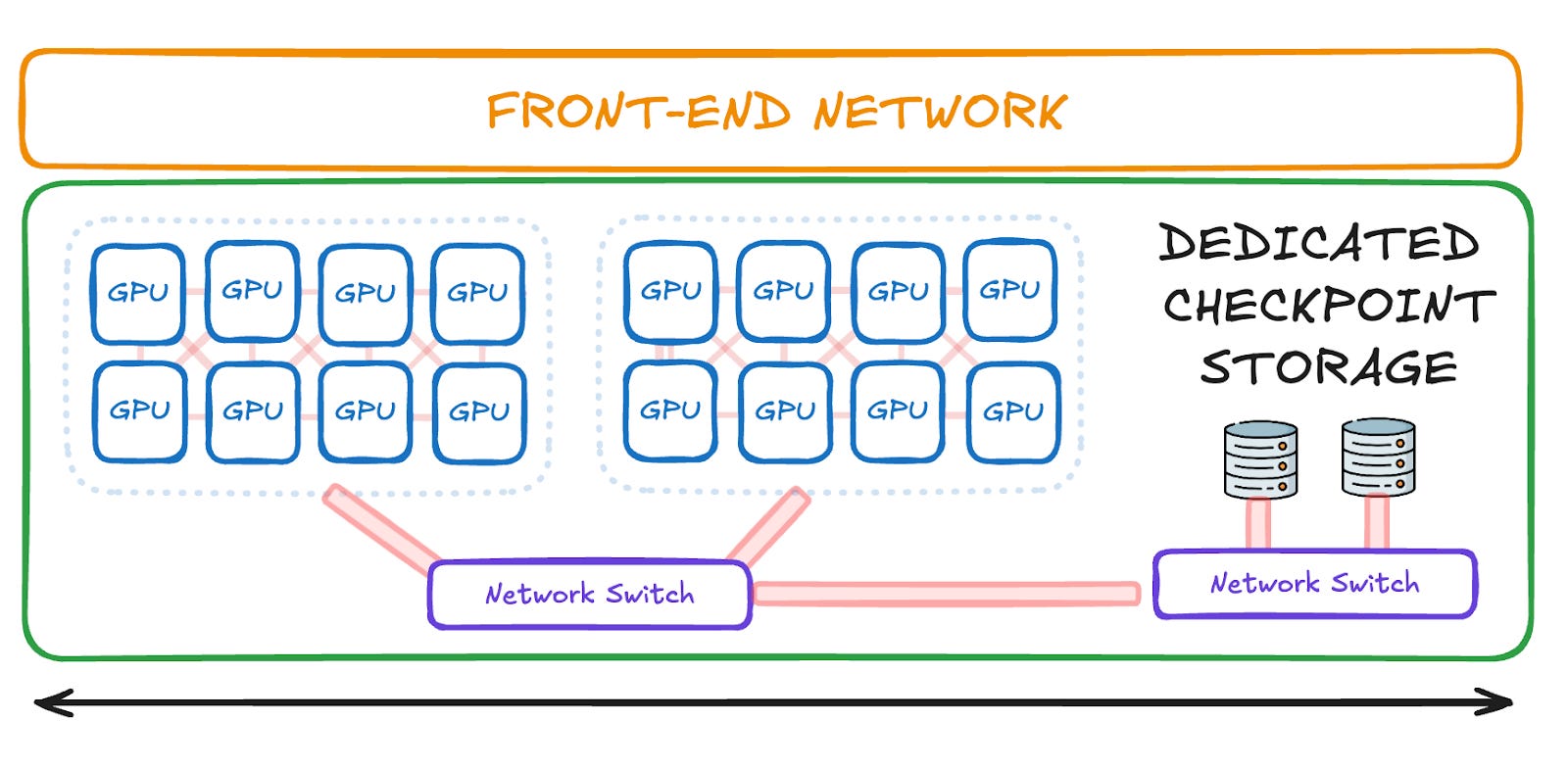
In this setup, checkpointing is additional East-West traffic, as it stays on the back-end network.
Mixture of Experts Training & Network Impact
Let’s look at a real example to cement our understanding.
Training large language models requires heavy East-West communication as workloads are distributed across tens or hundreds of thousands of GPUs. These GPUs frequently exchange gradient updates to keep the model learning consistently and converging toward accurate outputs.
One example of this multi-parallelism approach is DeepSeek’s V3 Mixture of Experts (MoE) model, which we previously discussed in detail here:

DeepSeek distributes the training workload using a combination of parallelism strategies, including data parallelism, pipeline parallelism, and expert parallelism.
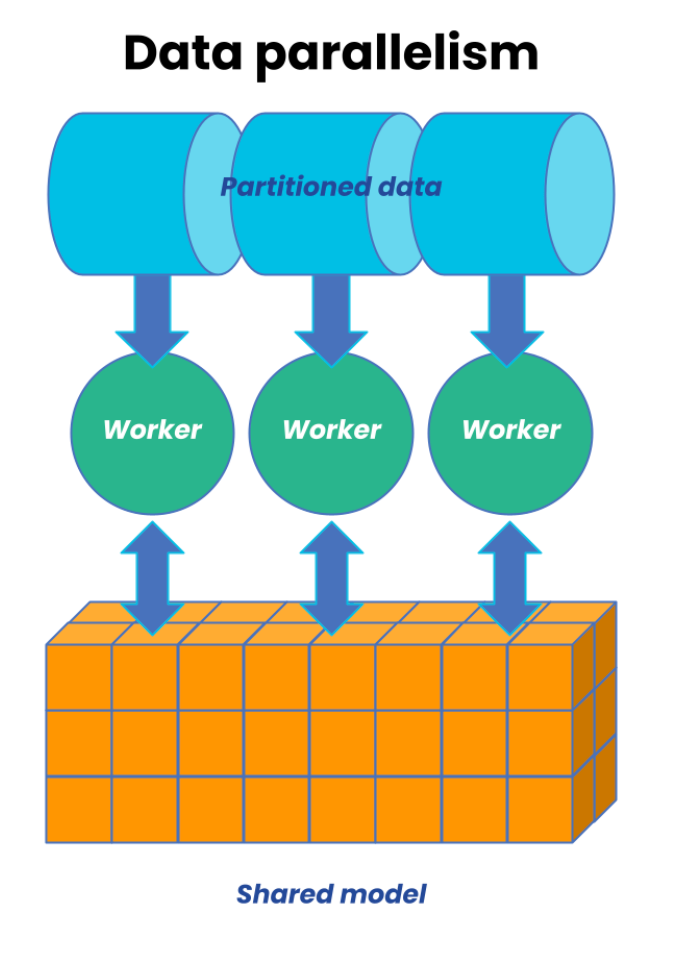
Data parallelism splits data across GPUs, each of which processes its shard (slice of data) independently before synchronizing updates to the shared model:
Pipeline parallelism splits the model across GPUs, with each GPU handling a segment of layers and passing intermediate results forward:

Expert parallelism splits the model into multiple experts (subsections of the network) distributed across GPUs, activating only a few experts per token to reduce compute:

What can we immediately take away from this?
Each of these strategies decomposes the problem such that any GPU is only tackling a subset of the network and training data. Thus, frequent GPU-to-GPU communication is required to stay synchronized and ensure consistent model updates.
Also — reality is complicated! The interaction of data, pipeline, and expert parallelism results in overlapping communication that must be carefully managed to avoid stalls.
Each strategy imposes its own pattern of east-west traffic. Let’s walk through how each layer adds to the pressure.
Data Parallelism: Global Syncs
With data parallelism, each GPU processes a different mini-batch of data and then shares its progress with every other GPU after every training step. Thus, these GPUs must perform an all-reduce to average gradients and synchronize weights—a collective operation that involves every GPU exchanging several GBs of data.
Because this occurs at every step and blocks forward progress, it is incredibly latency-sensitive.
You can imagine the network pressure this creates on the entire system after each training step, as data is simultaneously sent across the back-end network:

This pressure spawns innovation. Nvidia’s InfiniBand with SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) supports in-network reduction to minimize traffic volume and latency. The network switches themselves do the computation!
See this excellent two-minute explainer from Nvidia:
Having the switches do computation to reduce the network traffic is a prime example of Nvidia’s systems thinking — innovating at the AI datacenter level:

In summary, data parallelism is clearly a network-intensive training approach requiring a robust, low-latency, high-throughput fabric to scale efficiently.
Pipeline Parallelism: Chained Dependencies
Pipeline parallelism splits a model across GPUs by layers, with each GPU handling a different stage of the forward and backward pass. Activations move forward one stage at a time, while gradients flow in the opposite direction. This forms a sequence of strict dependencies where each GPU must wait for inputs from the previous stage before computing and then pass results to the next.
Any delay from network congestion can stall the pipeline. To minimize this, pipeline stages must be placed on physically close nodes to reduce hop count and avoid congested network paths. Thus, pipeline parallelism relies on topology-aware scheduling to maintain stable throughput.
Expert Parallelism: Uneven Traffic
Expert parallelism introduces a different communication pattern; it routes individual tokens to a small subset of experts. These experts are subnetworks located on different GPUs, and only a few are activated per input. A single token might be dispatched to Expert 3 and Expert 12, which could reside on GPUs in separate nodes.
This setup leads to irregular and bursty communication. Some GPUs receive large volumes of tokens, while others remain mostly idle. The resulting traffic is non-uniform and shifts with each batch.
Because the communication is non-deterministic, it also complicates system planning and debugging.
Much work is done in software to load-balance the workload across experts. DeepSeek shared their strategy and code:
As described in the DeepSeek-V3 paper, we adopt a redundant experts strategy that duplicates heavy-loaded experts. Then, we heuristically pack the duplicated experts to GPUs to ensure load balancing across different GPUs. Moreover, thanks to the group-limited expert routing used in DeepSeek-V3, we also attempt to place the experts of the same group to the same node to reduce inter-node data traffic, whenever possible.
Putting It All Together
Each of these parallelism strategies is demanding on its own. The backend network must support three distinct types of pressure:
Global collective ops (data parallel)
Synchronous chained flows (pipeline)
Sparse, bursty, cross-GPU dispatch (experts)
These networking tasks happen simultaneously; activations flow through pipelines, gradient all-reduce begins, and expert GPUs request tokens. The backend must absorb the chaos without slowing down.
Appreciating DeepSeek
Grasping the network challenges in MoE training lets us appreciate DeepSeek’s deliberate strategy to avoid congestion through careful system design.
From the V3 technical report:
Through the co-design of algorithms, frameworks, and hardware, we overcome the communication bottleneck in cross-node MoE training, achieving near-full computation-communication overlap. This significantly enhances our training efficiency and reduces the training costs, enabling us to further scale up the model size without additional overhead.
How did they do this? Remember the computation and communication innovations we unpacked last time? Again, from DeepSeek:
In order to facilitate efficient training of DeepSeek-V3, we implement meticulous engineering optimizations. Firstly, we design the DualPipe algorithm for efficient pipeline parallelism. Compared with existing PP methods, DualPipe has fewer pipeline bubbles. More importantly, it overlaps the computation and communication phases across forward and backward processes, thereby addressing the challenge of heavy communication overhead introduced by cross-node expert parallelism. Secondly, we develop efficient cross-node all-to-all communication kernels to fully utilize IB and NVLink bandwidths and conserve Streaming Multiprocessors (SMs) dedicated to communication. Finally, we meticulously optimize the memory footprint during training, thereby enabling us to train DeepSeek-V3 without using costly Tensor Parallelism (TP).
AI labs are surely working to overcome network congestion too; they don’t have the constrained bandwidth of H800s like DeepSeek, but nonetheless deal with complex parallelism and network pressure. But we’ll give props to DeepSeek since they share their insights with us.
And hey, although we’ve kept our GPU networking series very simple, it’s cool that we can skim modern research papers and better appreciate their innovations!
Beyond the paywall, we combine our insights with industry data to revisit the Infiniband vs Ethernet contest. Hey, SHARP makes Infiniband look strong, right? Can Nvidia stay on top?
And, if you want to keep going in this series:
