

SerDes Matters!
What Is SerDes, Why It Matters, Which Companies Have SerDes Chops

We recently discussed that it makes sense to right-size an AI cluster to fit a particular family of workloads. Specifically, the user requirements of workloads can result in similarly shaped infrastructure requirements:
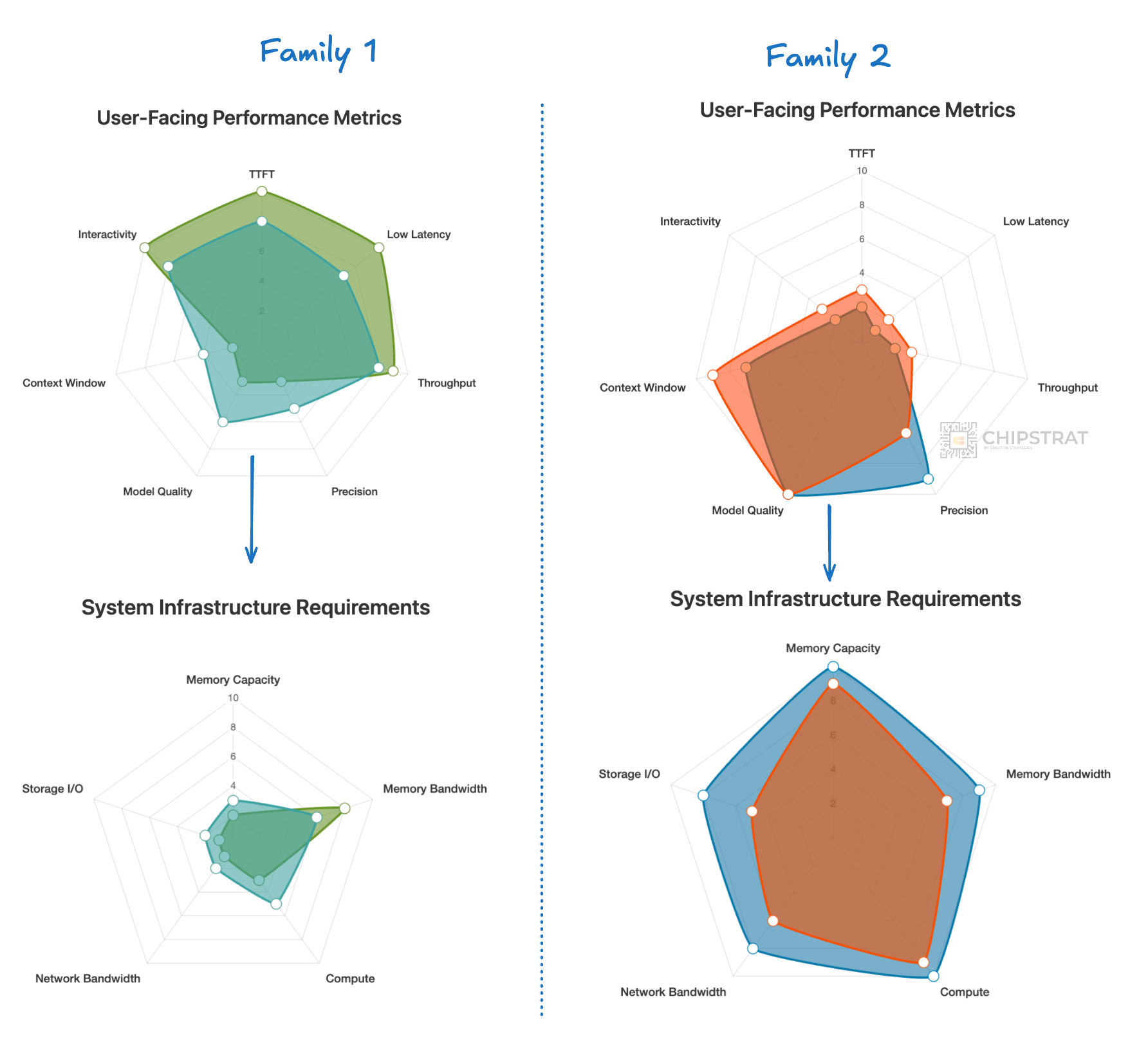
We already see this “right-sizing” of AI infra with disaggregating LLM inference across different Nvidia hardware; prefill on Rubin CPX and decode on traditional Rubin.
This line of thinking can lead to XPUs; if a particular hyperscaler is quite convinced they’ll need to run a particular type of workload at scale indefinitely, why not trade-off some of the flexibility of GPUs for a more finely tuned AI accelerator?
For example, won’t OpenAI continue to run fast-thinking (GPT-4o style) LLMs indefinitely?
For workloads that might continue to evolve significantly, stick with GPU-based clusters. But for stable workloads at the massive scale of hyperscalers, a custom AI cluster with XPUs can make sense. It’s been three years since ChatGPT launched already…
But customizing the datacenter to a particular workloads is more than just picking a particular already-baked chip. Just like Nvidia systems are GPUs + networking + software (+ memory, + CPUs, + storage), XPU-based systems also include networking, memory, and more. Marvell calls these additional components XPU attach.
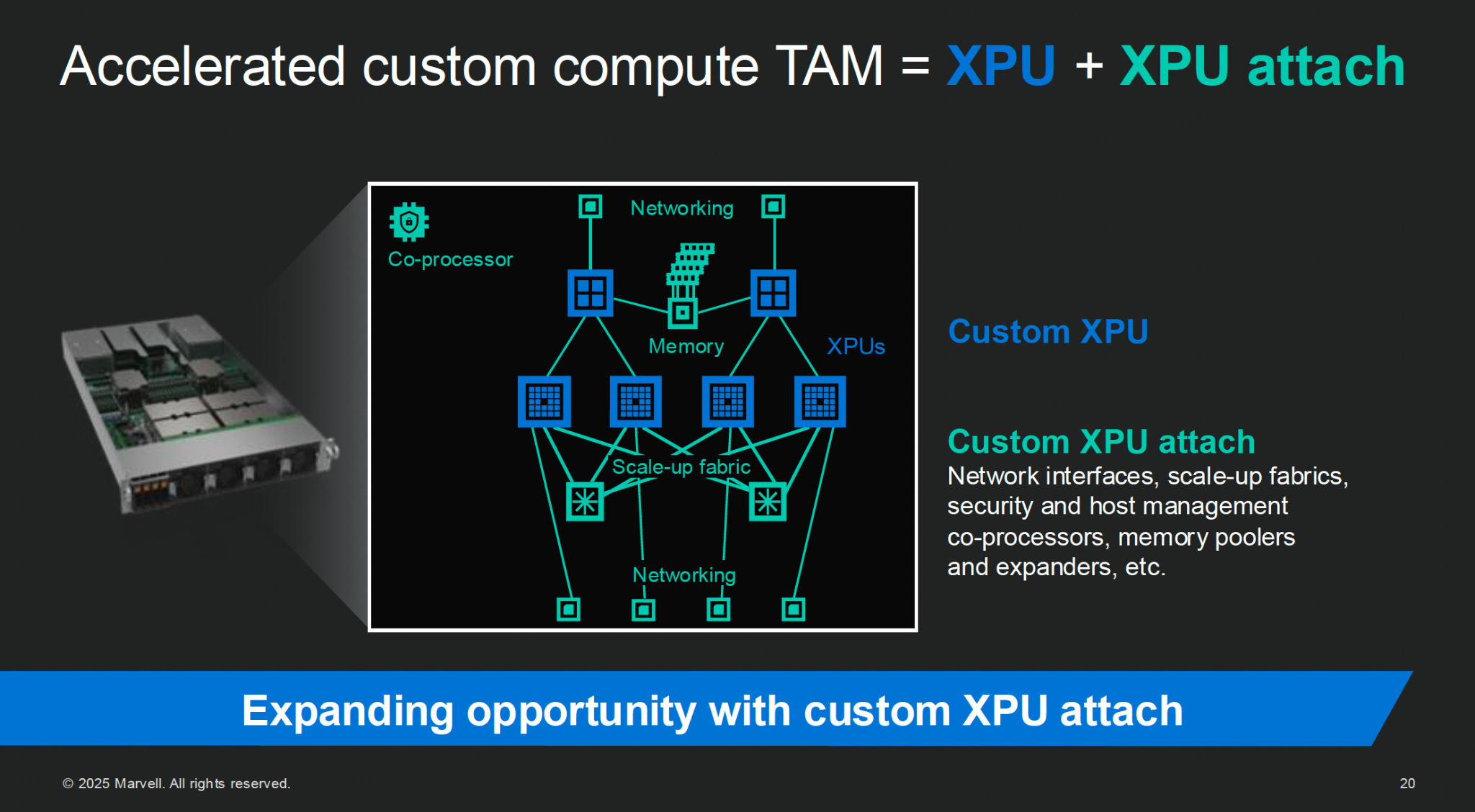
And with a custom accelerator partner you can turn all sorts of knobs deep within the XPU and XPU attach to tune the resulting AI datacenter to meet your workload’s needs.
Marvell’s Sandeep Bharathi: Now, Matt talked about XPU and XPU attach. What is important to see in an XPU attach, there may be certain IPs that are not necessary, for example, CPU. But what it means that for each of these, the power and performance per watt requirements are different, which means you need to optimize different SerDes or different Die-to-Dies (D2Ds) for each one of these to meet the needs of the workloads.
So customization to achieve the highest performance per watt is a Marvell specialty.
So IP building blocks like SerDes or D2D can be optimized to help the system get the needed system-level performance per Watt.
But….. what the heck is SerDes? Why is it important?
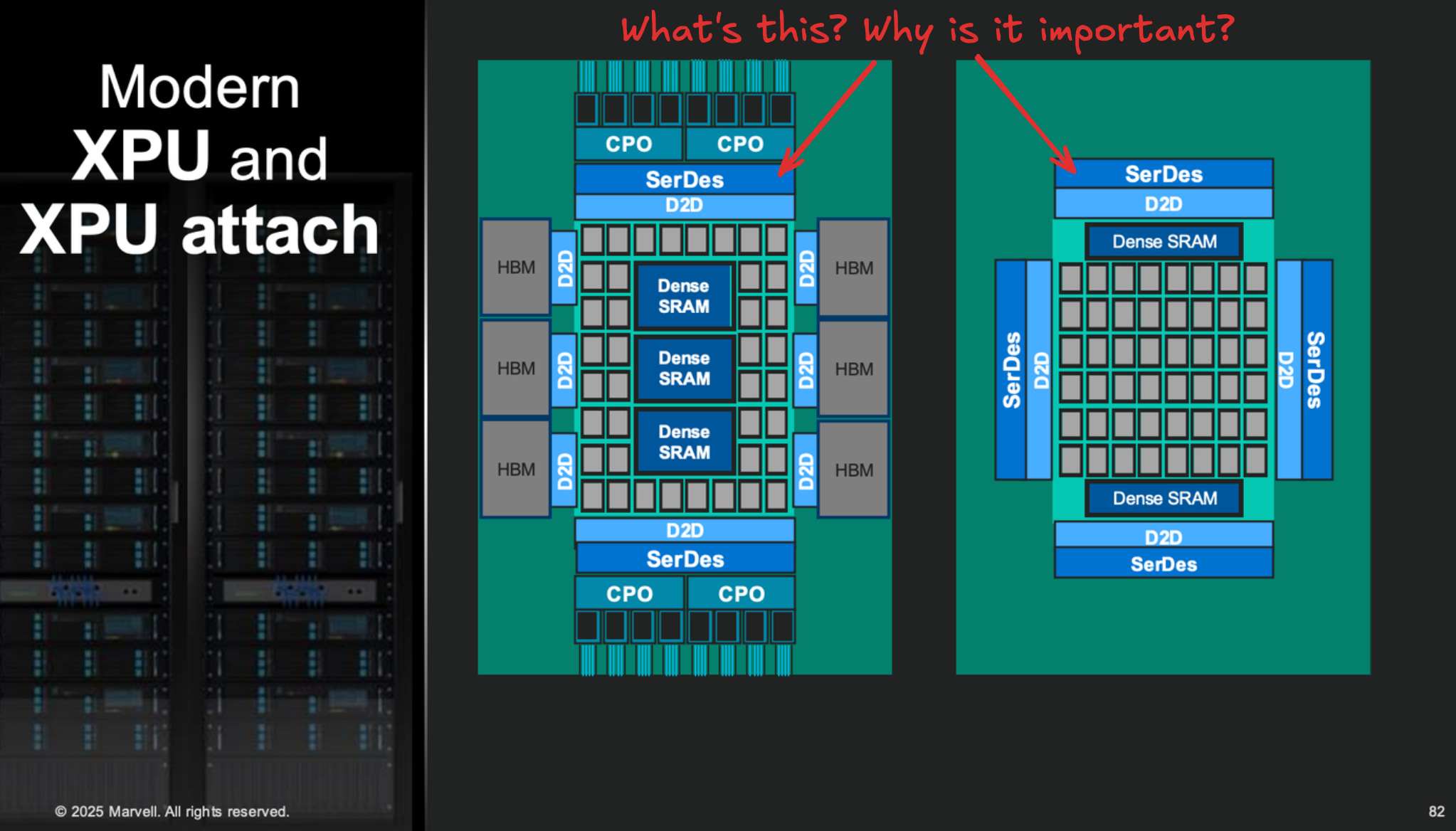
So let’s spend today working through related questions.
what is SerDes?
why is it so important for XPUs?
what trade-offs can be made within SerDes to optimize for a workload?
Why is SerDes design hard?
Which companies have SerDes chops?
What Is SerDes?
Let’s start by zooming way out. If we look at that Marvell diagram, one can start to guess where SerDes comes into play. It looks like it’s part of sending and receiving signals from off-package chips:
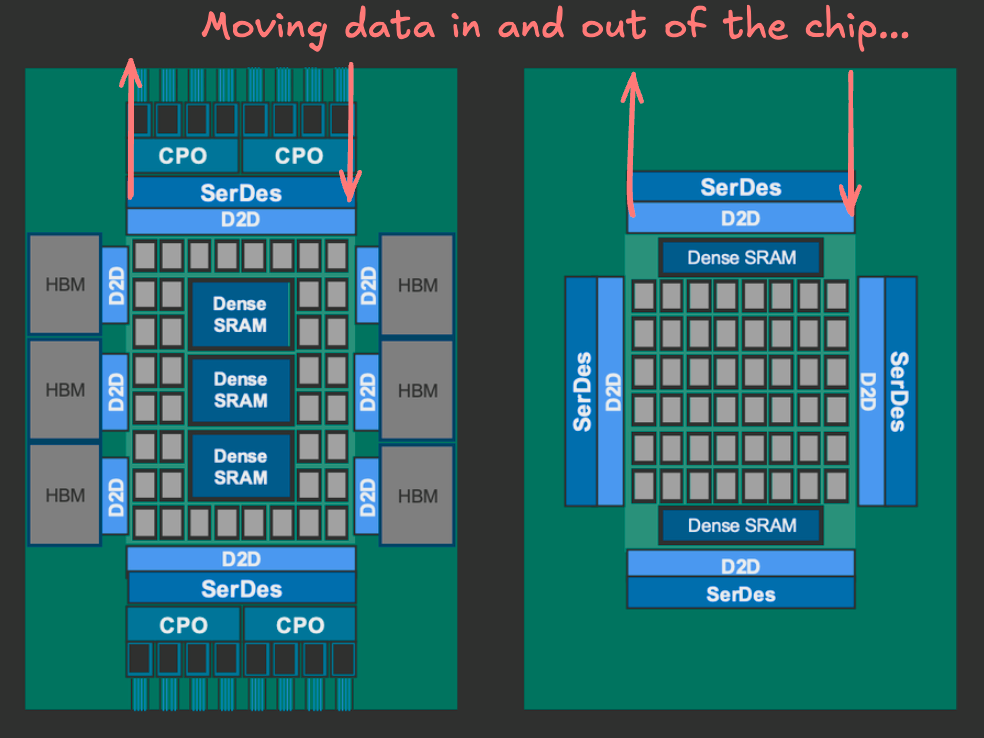
Hmm. How does data move from one chip to another?
Parallel Communication
Back in the day, parallel buses were the standard for chip-to-chip communication.
Remember seeing cables like this 68-pin SCSI cable?

These worked fine, for a while. But here’s an interesting point. The 68 wires here carry 68 simultaneous signals. Yet only 16 of those are data lines; the rest handle parity, control, power, and ground. See bits D0-D15:
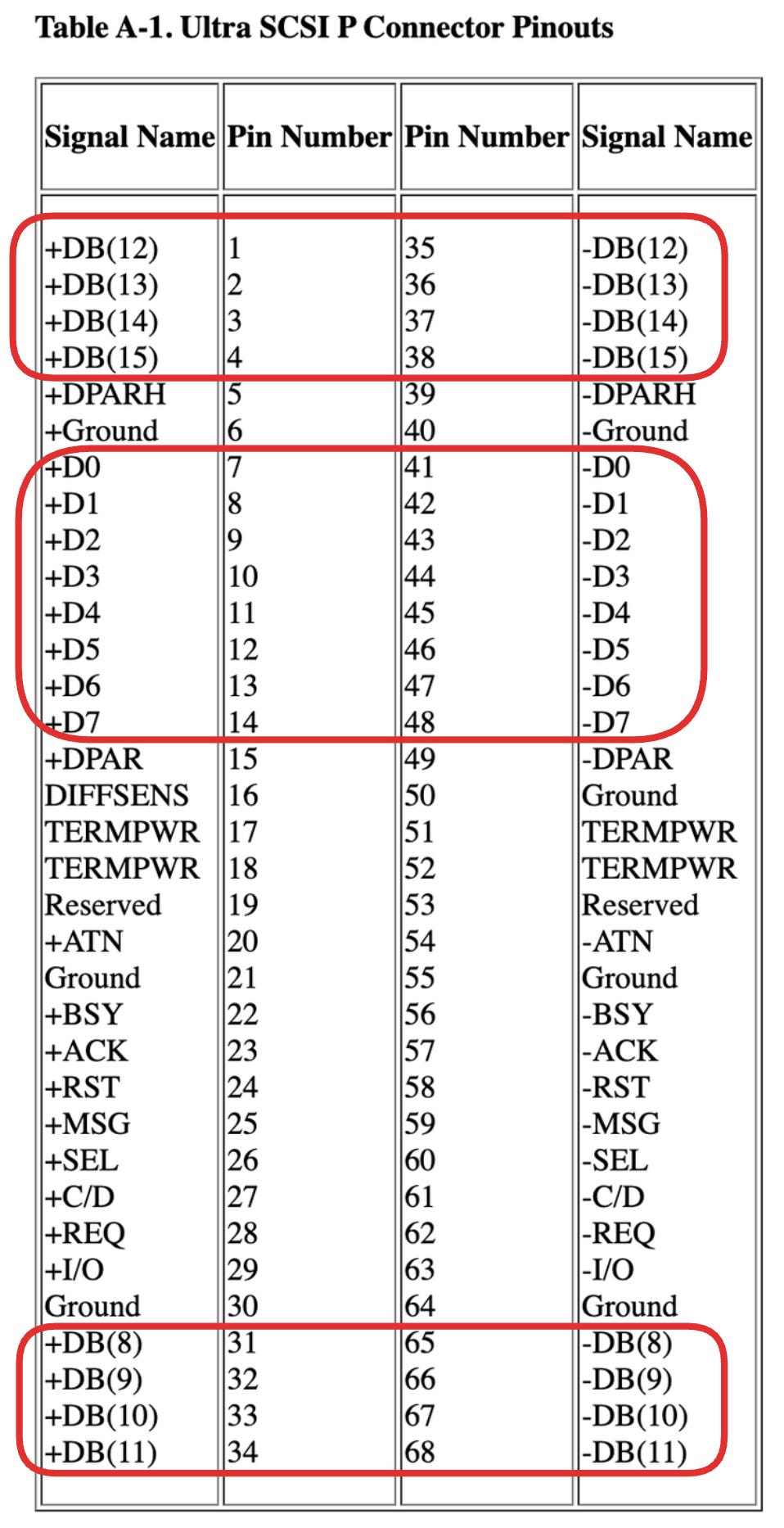
That’s a lot of overhead to send just 16 bits of information in parallel.
And what if these peripherals, like a hard drive, end up needing more bandwidth to send more data per unit of time? Well, the simple thing would be to add more wires (width scaling) or increase the frequency at which you’re sending information (frequency scaling).
Width scaling quickly hits practical limits though. If it took 68 pins to move 16 bits, a 64-bit bus would require hundreds of pins. This results in bulky connectors and dense routing. All those wires and pins ultimately leads to crosstalk and added cost.
OK then. Frequency scaling it is! Just run the same number of wires faster.
That works, but eventually runs into physical limits. Every wire has slightly different length and impedance, causing signals to arrive at slightly different times. This is a problem known as skew.
At something like 100 MHz, skew isn’t a big deal if you sample the signals at the right time:

But at gigahertz frequencies, each signal is on the order of hundreds of picoseconds. And even a few millimeters of extra trace or wire length can delay a signal by tens of picoseconds, which ends up being a non-negligble fraction of the bit period. This causes bits from one end of the bus to arrive misaligned at the other:
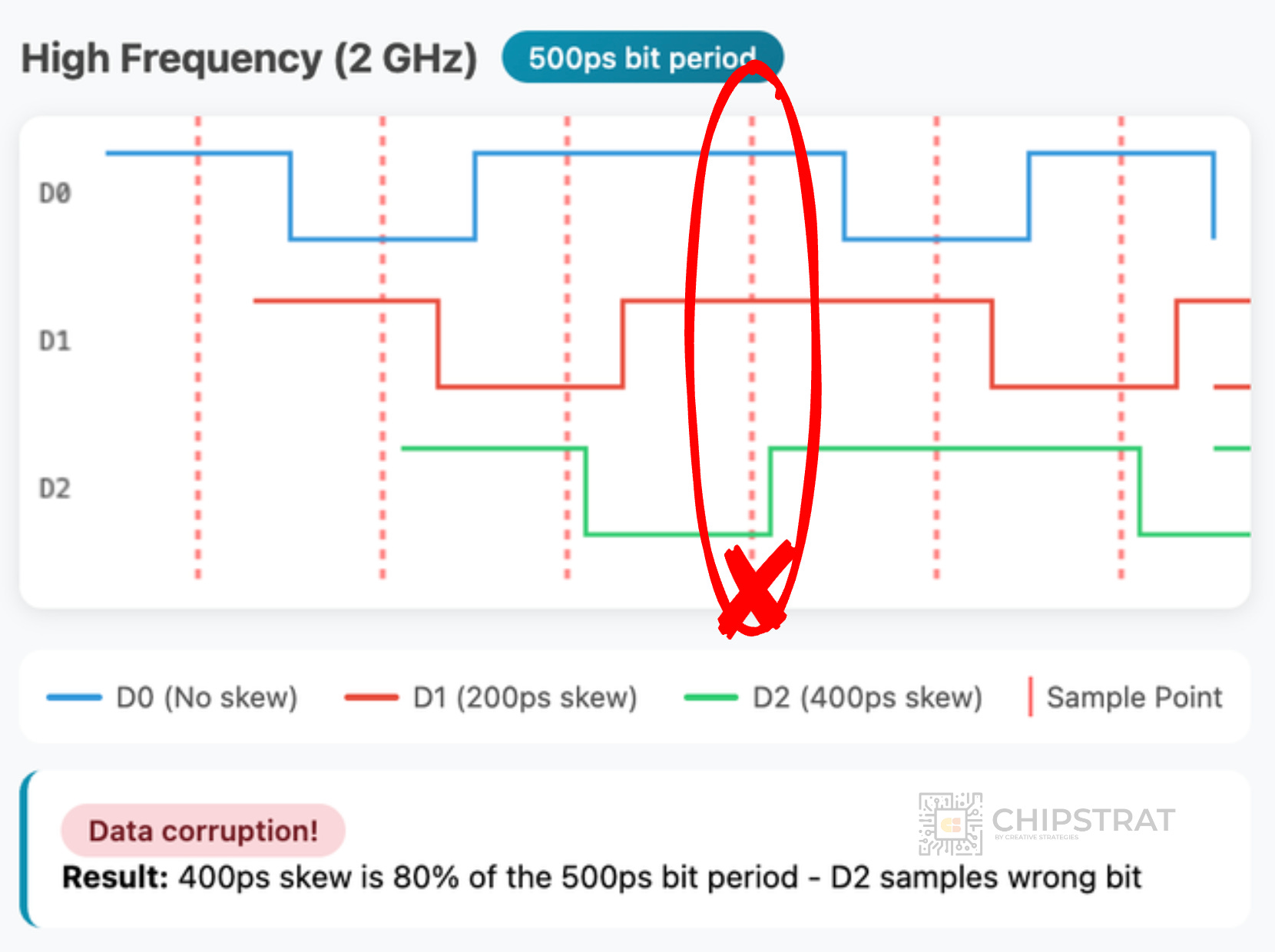
At higher frequencies, crosstalk worsens. Adjacent wires start to interfere through capacitance and inductance, distorting signals and reducing the margin—the small timing and voltage window where bits can still be read reliably.
A shrinking margin means less room for error. As that safe zone narrows, even minor noise or delay can flip a 1 into a 0. Once skew and crosstalk consume most of the bit period, parallel frequency scaling breaks down.
What to do? Instead of sending all these bits on their own independent wires in parallel, what if you grouped them and sent them down fewer wires serially? Fewer wires mean less crosstalk right? And as a bonus, simpler routing too…
Serial Communication
But wait, I thought faster worsens skew?
Yep. Faster signals worsen skew, but serial communication overcame that through differential signaling, where each bit is transmitted as two complementary voltages on a tightly coupled pair of wires. The receiver measures the voltage difference, canceling common noise and minimizing electromagnetic interference.
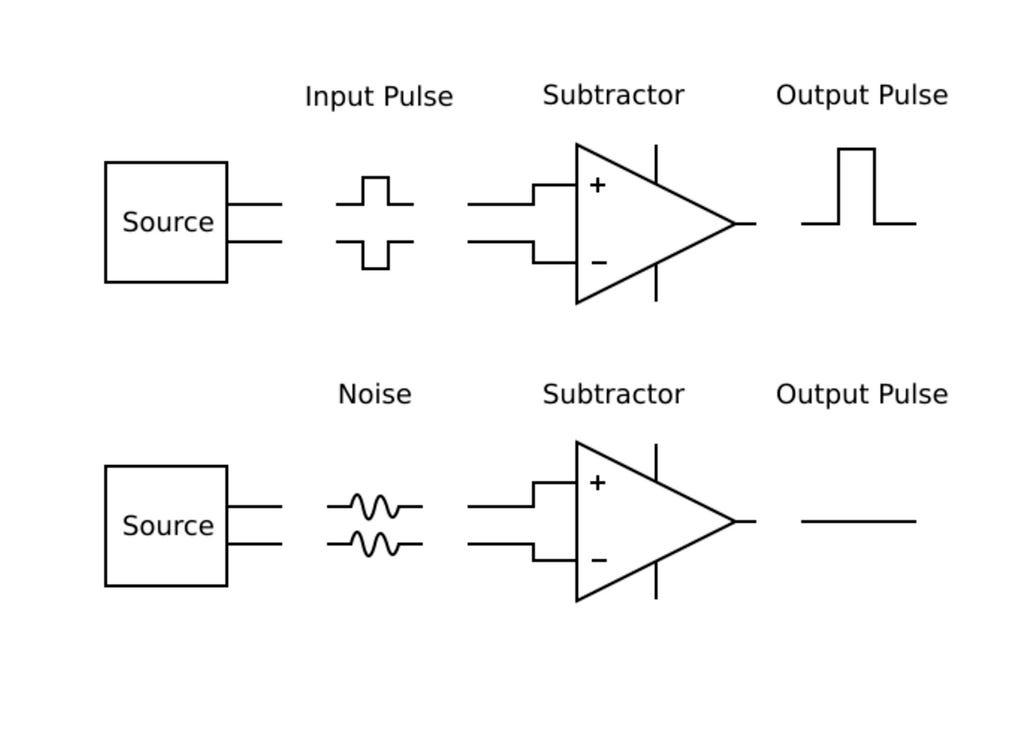
Differential pairs also enable clock recovery. The receiver extracts timing directly from the bitstream rather than relying on a global clock. Thus, each serial lane self-clocks, helping eliminate skew between wires.
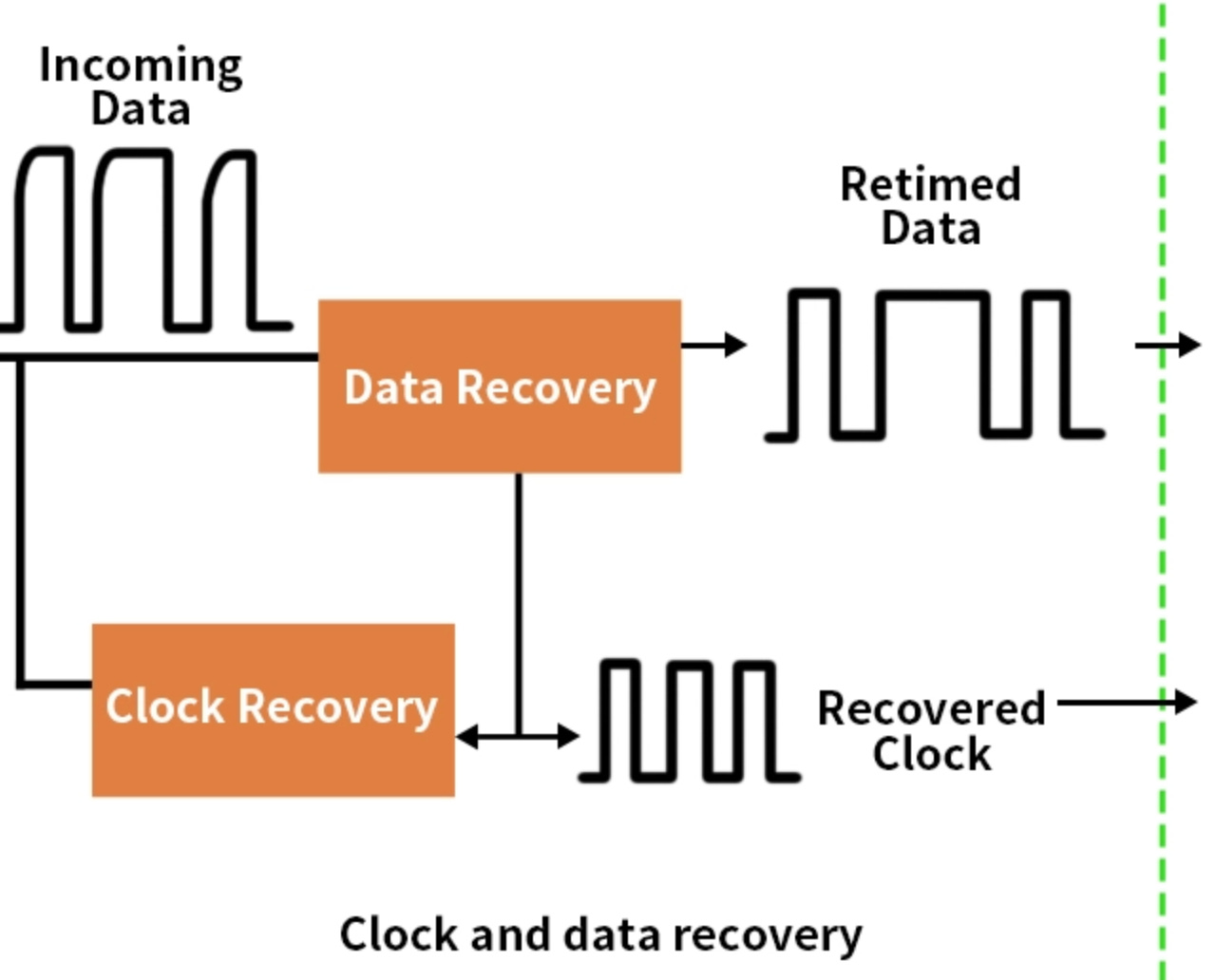
So, the solution to “how to get more bandwidth from this parallel cable” is to stop sending 64 bits at once and instead send them serially over fewer wires but at much higher speed.
By the way, by the early 2000s, parallel buses topped out around low hundreds of MHz, while serial ATA and PCI Express (PCIe) replaced them with multi-gigabit lanes:
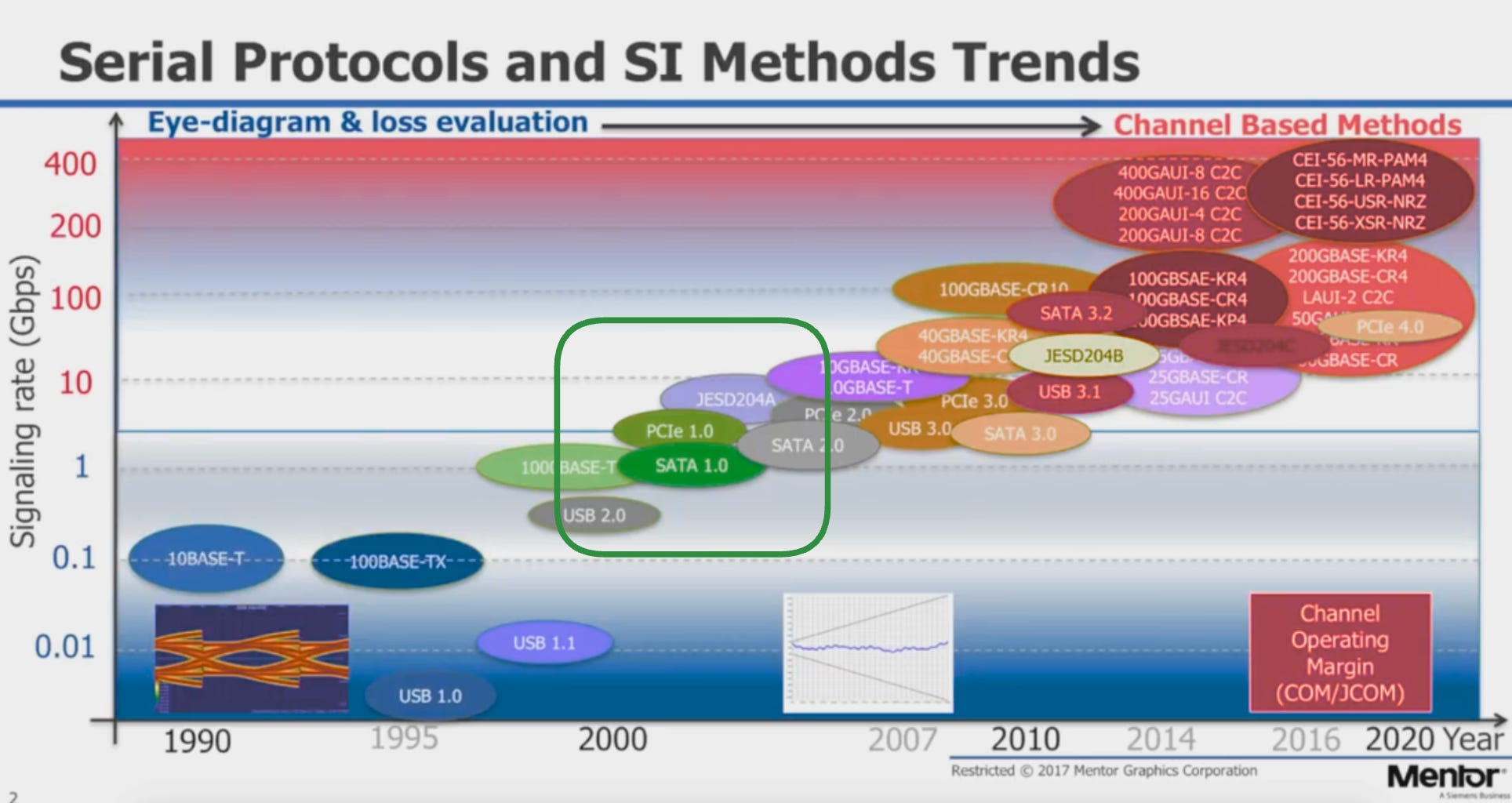
So the industry shifted to faster serial lanes which required increasingly smarter transceivers.
These transceiver circuits serialize, transmit, receive, and deserialize data.
Finally, SerDes!
SerDes
SerDes stands for Serializer/Deserializer.
It’s the circuitry that converts between wide, slow parallel data inside a chip and narrow, high-speed serial data used to communicate off-chip.
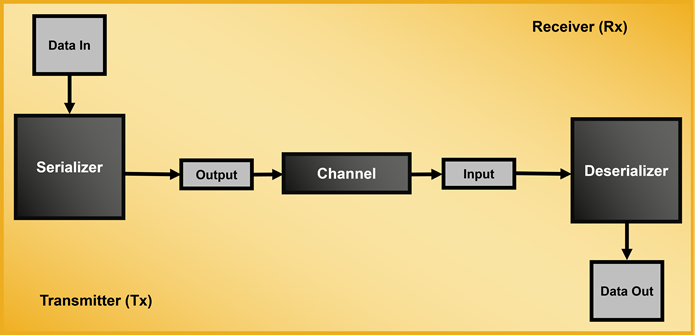
The SerDes block takes that wide internal bus, serializes it into a few differential pairs running at high speed, sends it across a package trace, PCB, or cable, and then deserializes it back into parallel form on the other side.
Every modern high-bandwidth interconnect like PCIe, Ethernet, Infinity Fabric, and NVLink rely on SerDes as the physical interface layer.
UALink? SerDes.
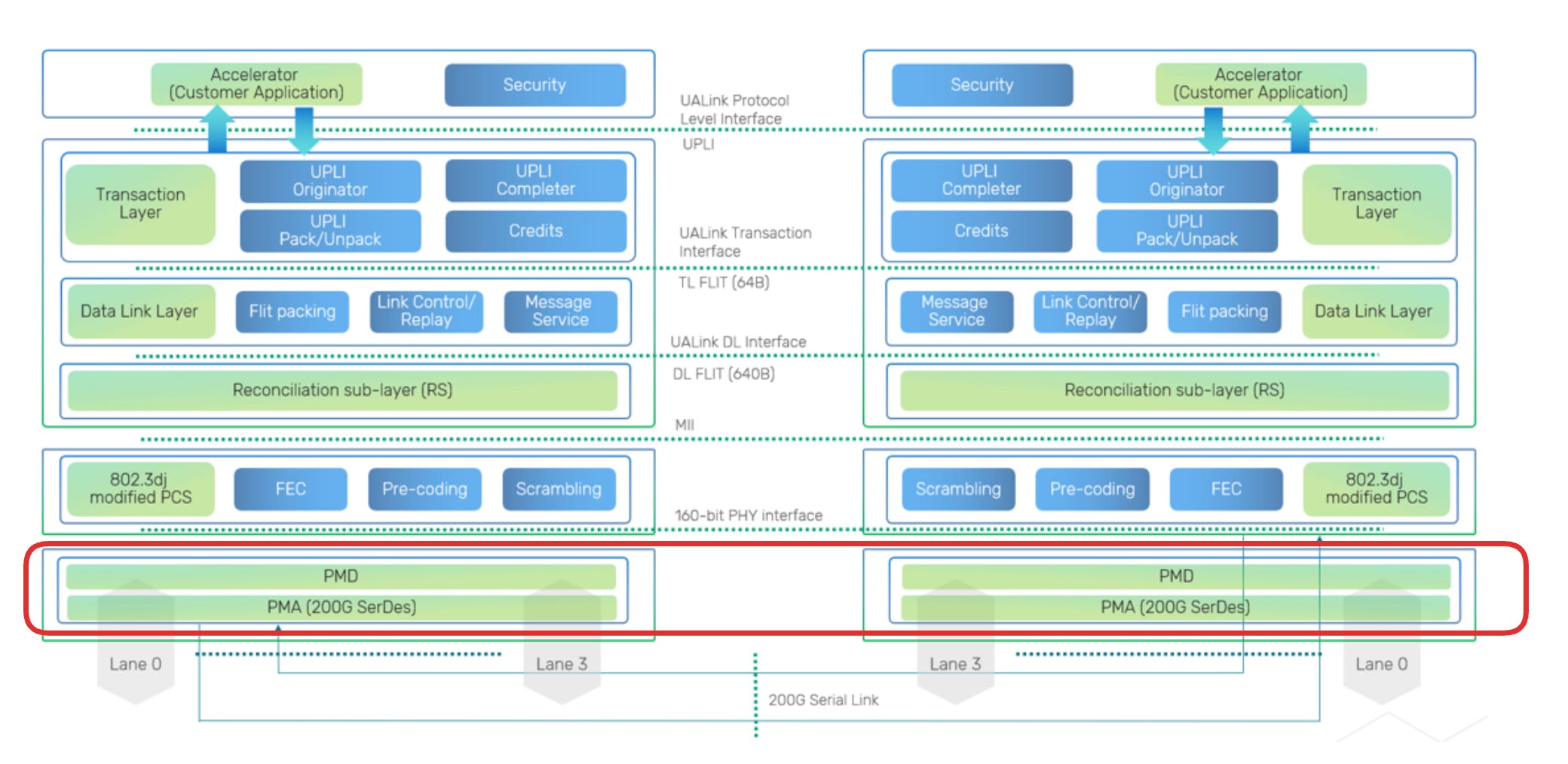
ESUN / SUE-T ? SerDes.
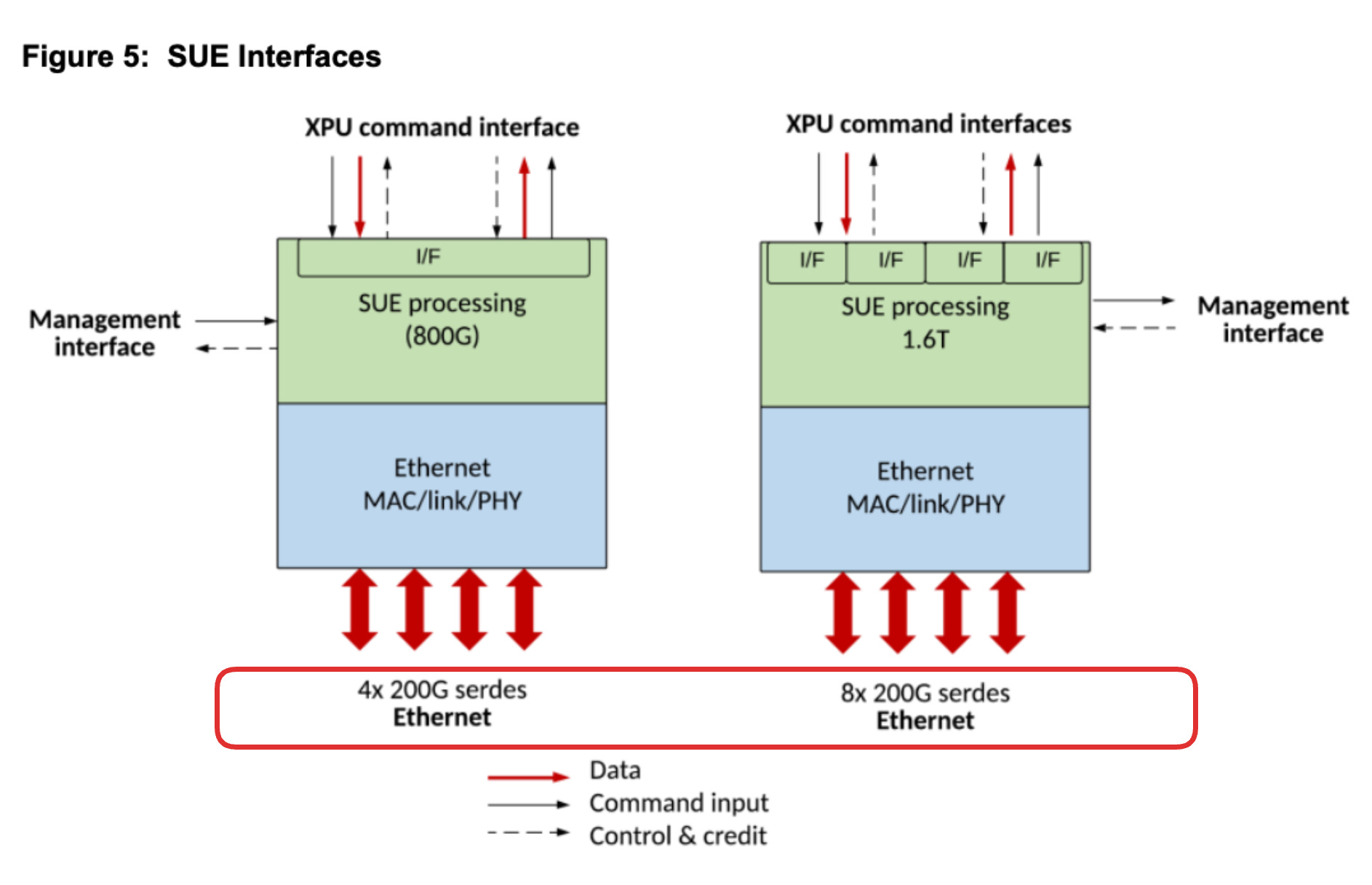
Behind paywall we’ll go deep into SerDes, including why it’s so difficult and which trade-offs can be made within SerDes to optimize for a particular AI workload.
I’ll also include some very enlightening conversation with a SerDes expert regarding the SerDes market. And even if you’re new, after reading this you should be able to better understand the conversation!