

When Frontier AI Goes From Cloud to Desk in Five Years
Implications of running yesterday's frontier models on today's local supercomputers. Rhymes with Minicomputers in Mainframe Era. Nvidia, AMD, Intel, Dell, TSMC, Micron.

2026 CES looked familiar. First came new cloud systems (e.g. Vera Rubin, MI500) built to run the largest frontier models. Then came new laptop chips (e.g. Ryzen AI Max+) pitched as capable of running small models locally. Maybe it feels a bit old after seeing this pattern three years in a row… but now we have enough data to look back and see if any trends emerge. And they do indeed!
Let’s go back in time to 2024. That year, laptop chip makers were excited to discuss how they could run 7B SLMs on the NPU. GPT-2 era models had finally trickled down from GPU clusters to local machines, roughly five years after their cloud debut:
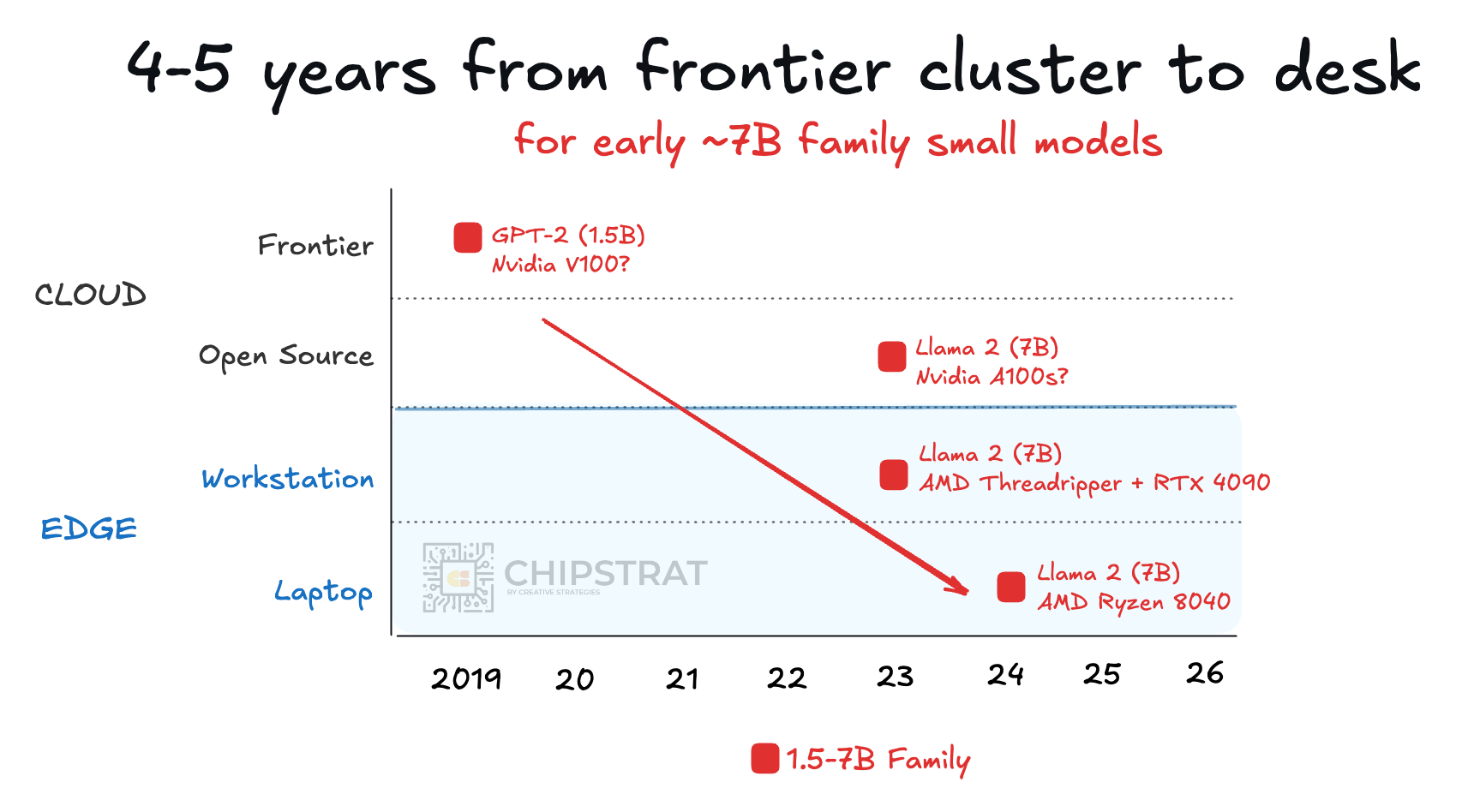
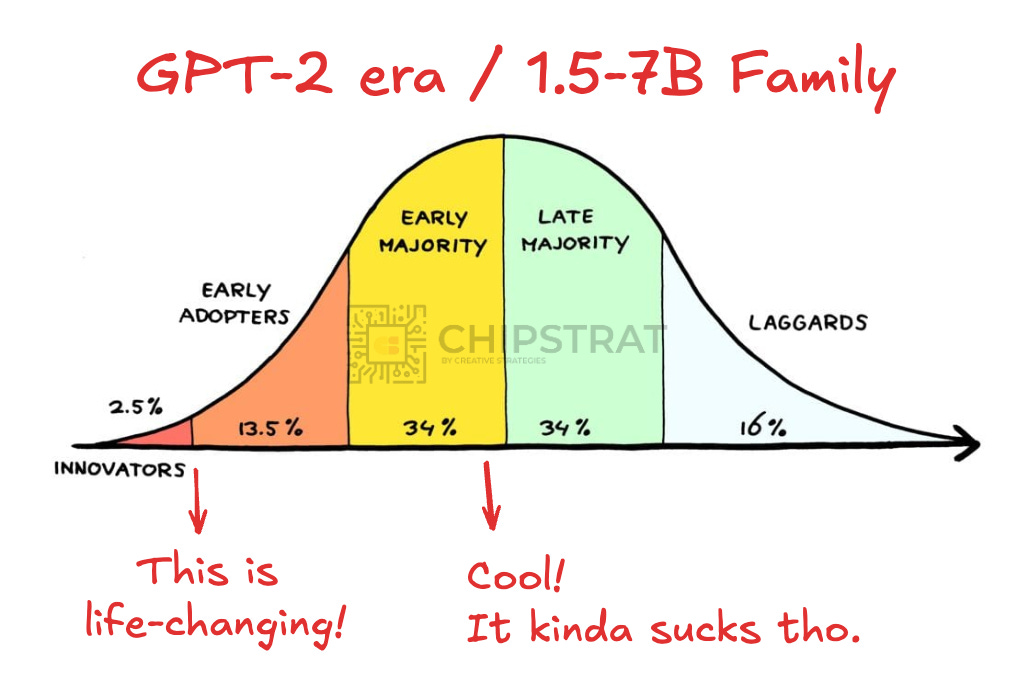
Of course, GPT-2 era small models weren’t terribly useful. Even newer models, when distilled down to 7B, were mostly just OK:
Now fast forward to 2025’s announcements, where useful models finally arrived at the edge, driven by distilled reasoning models and the ability to run up to roughly 70B parameters locally.
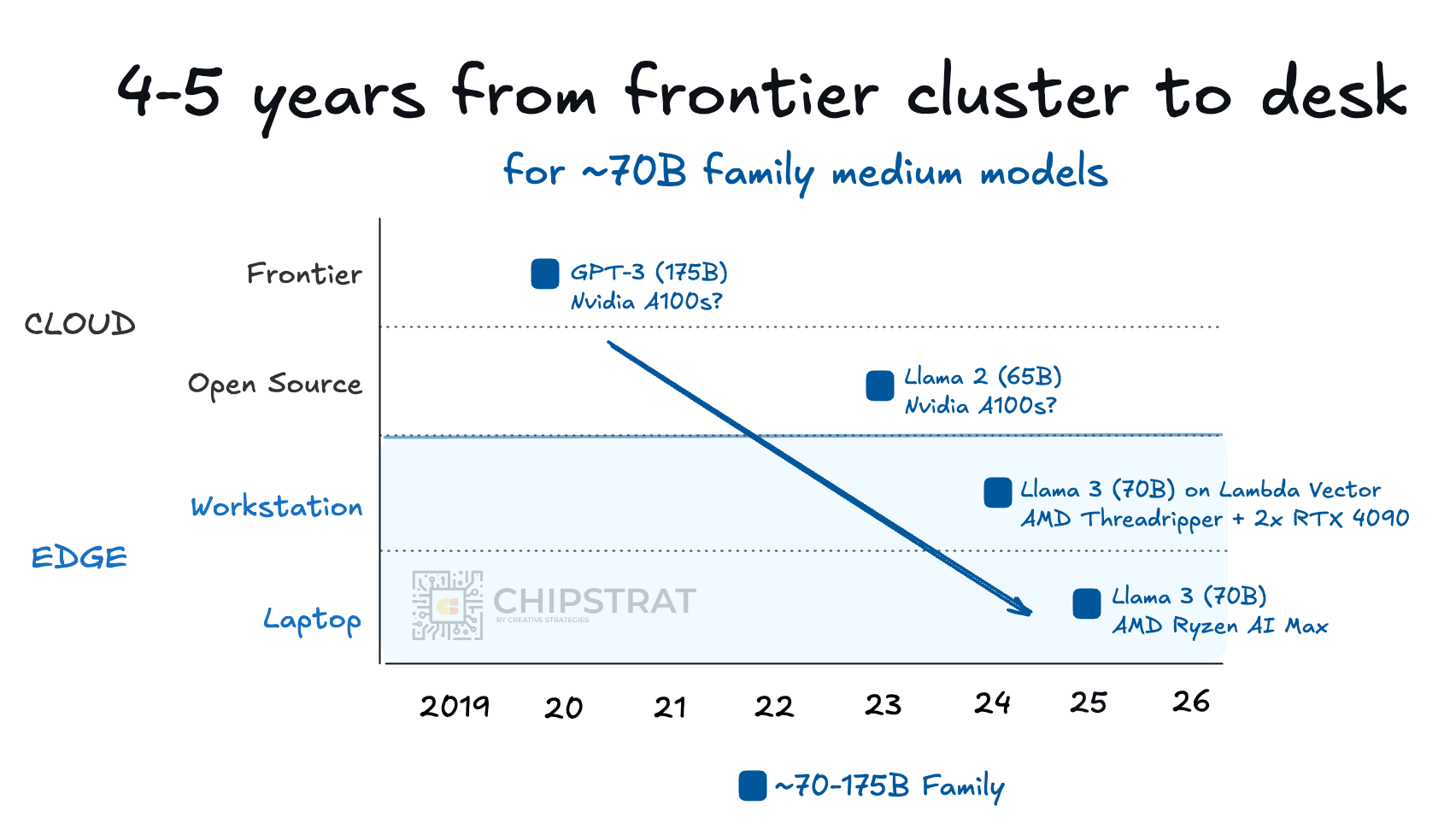
A person could now reasonably run good “fast thinking” and “slow thinking” models, even at the edge.
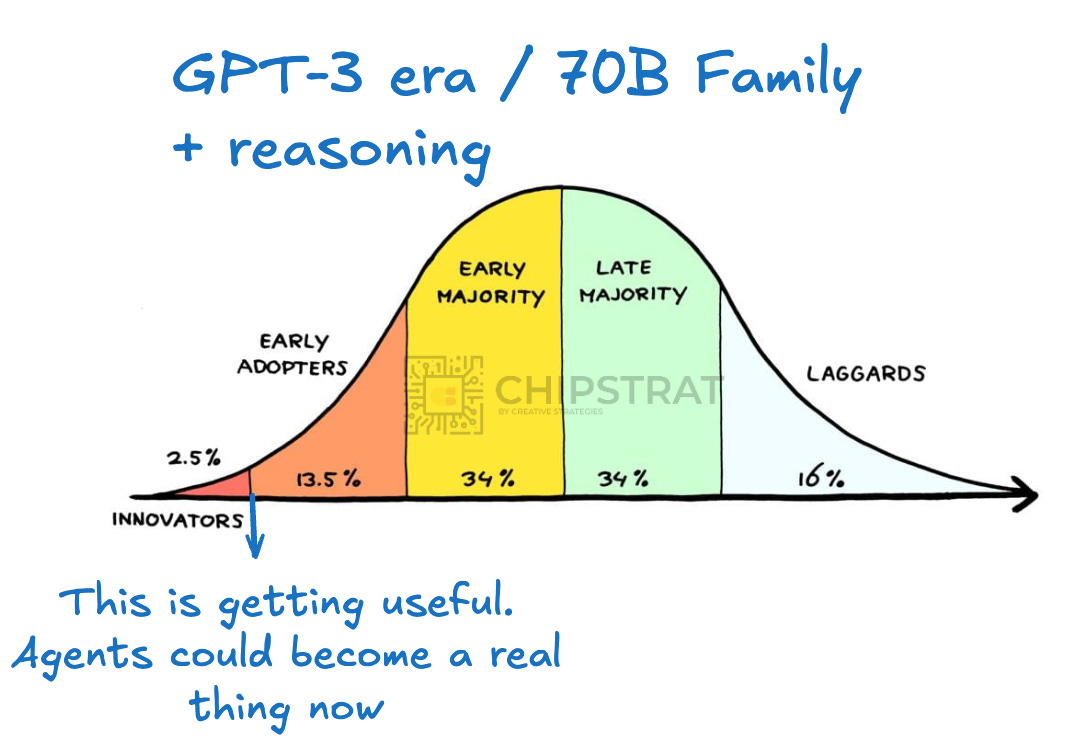
But at the time, many assumed this was the ceiling. This is all the bigger we can go at the edge. Running these models on laptops still felt slow too.
Now it’s 2026. And what did we see at CES for local AI? Check out this two minute video:
That dude just did some super interesting local AI stuff. On a Macbook no less. But not exactly!
Nvidia’s DGX Spark and especially DGX Station keep the trend alive by pulling GPT-4 class capability onto the desk:
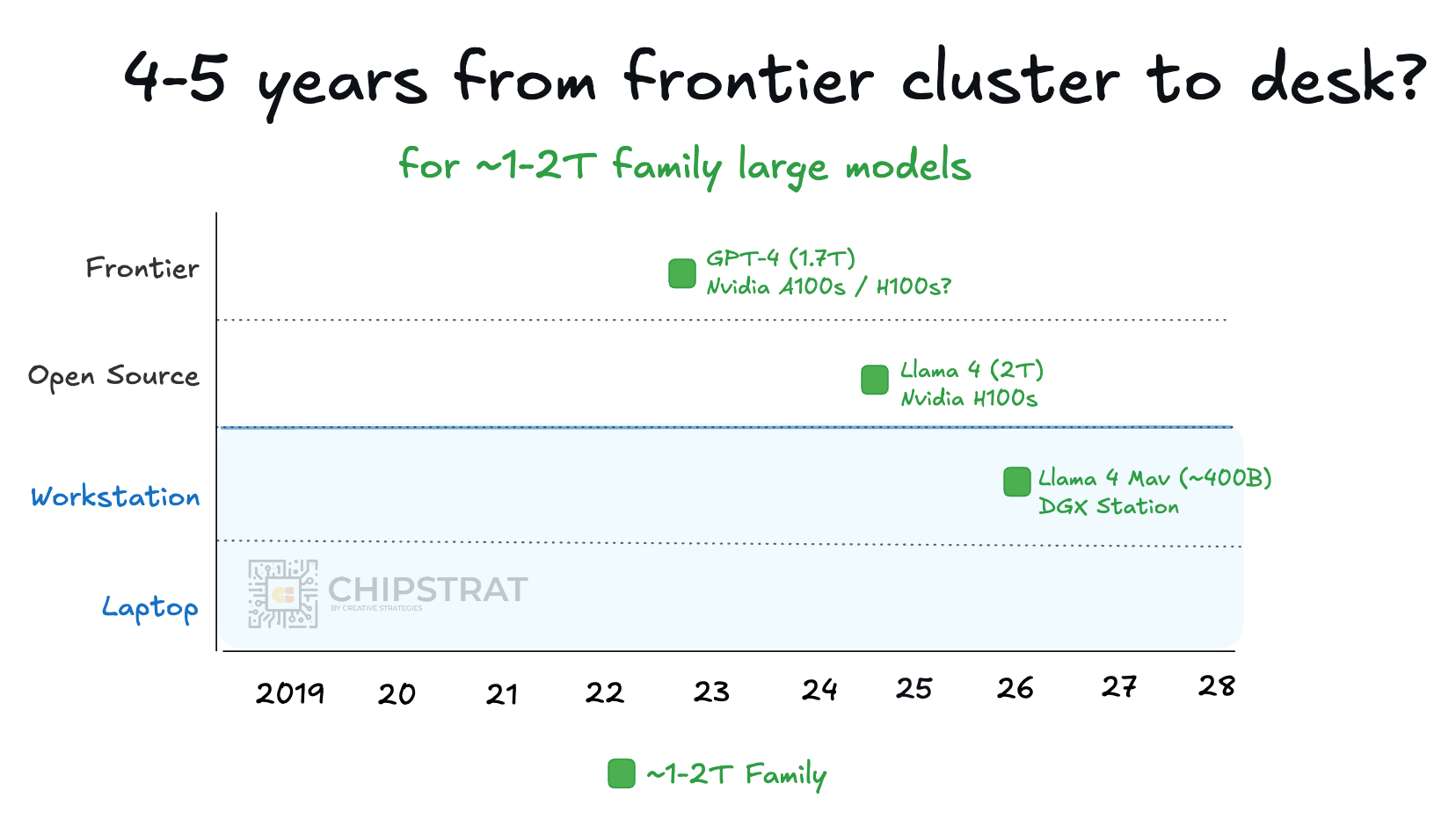
The catch is cost. DGX Station uses GB300 and includes HBM (e.g. 288GB HBME3e GPU memory and 496GB of LPDDR5X CPU memory) so we should assume an AI server-grade price tag, plausibly $30-100K?

At that level, it is less a “workstation” than an on-prem AI server that happens to sit near the team. That’s still interesting to noodle on.
The more interesting question is when GPT-4 family inference becomes practical on something closer to DGX Spark pricing:
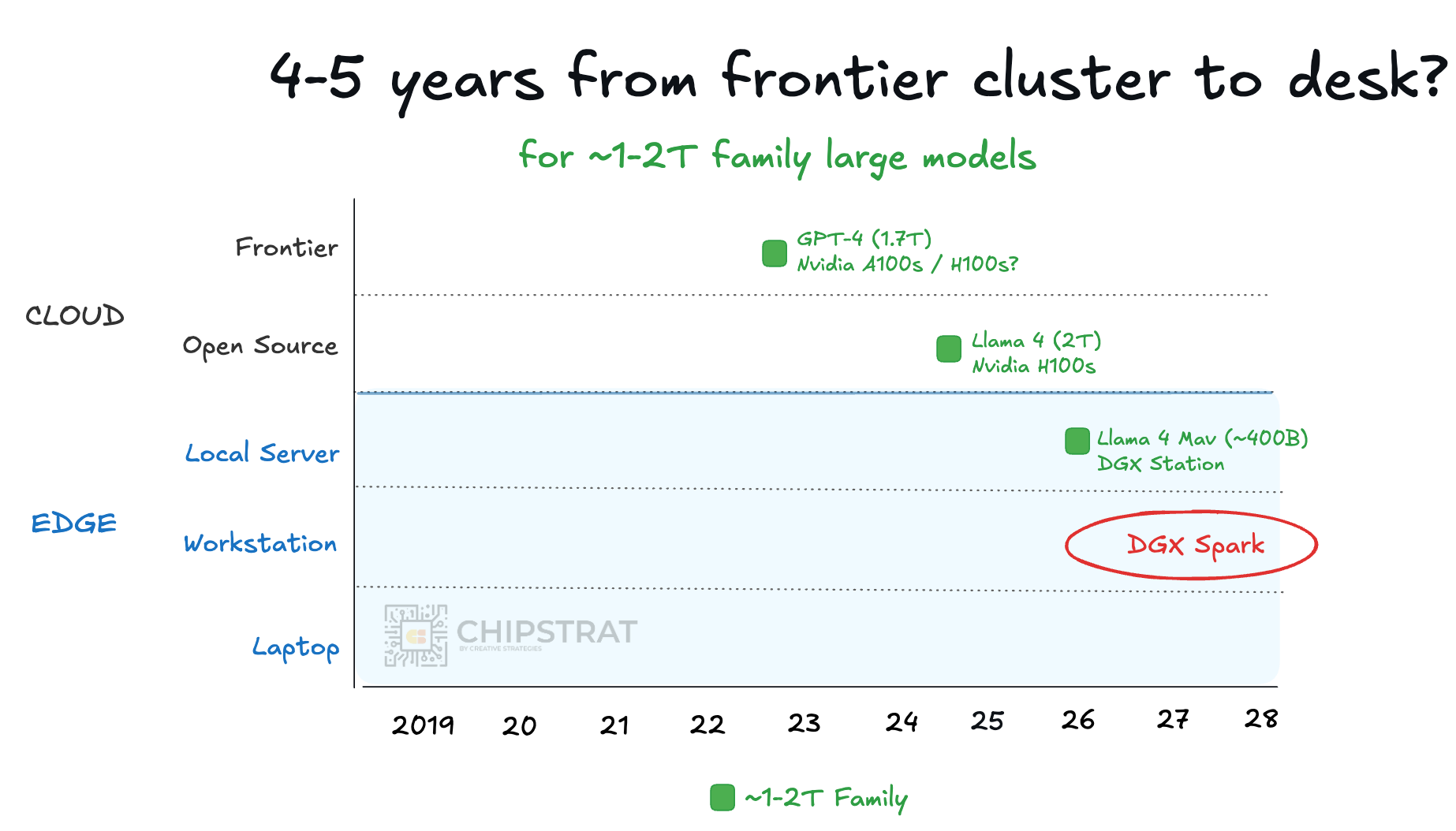
If GPT-4 family models can move on-premises into hardware that ranges from say $4,000 to $100,000, that raises interesting questions:
What enables huge models to step down from cloud to edge? And do those techniques scale to GPT-5 class models?
Do GPT-4 family models make it to the laptop? Do they need to?
Where do tokens per dollar actually matter? If you can run more capable models at the edge, does talking about dollars per token make sense?
Will this meaningfully impact AI adoption?
And, of course, what does this trend of 5-year-old frontier models at the edge, even if only high-end local servers, mean for companies like NVDA 0.00%↑ AMD 0.00%↑ INTC 0.00%↑ TSM 0.00%↑ and DELL 0.00%↑ ?
No one’s really connecting these dots yet, so I worked through it in detail below.