

Thinking Bots + Nvidia’s Robotics Play
Vision Language Action (VLA) Models, Nvidia’s Robotics, Semiconductor Industry Implications, Competition (Google, AMD, Intel, QCOM, more)

Why We’re Covering Robotics
At Chipstrat, we typically focus on what’s happening right now: earnings calls, product launches, and near-term roadmaps from major players. These signals help us understand the next 12 to 18 months.
But to truly see where the industry is going, we need to look further ahead:

Startups and research labs offer the best clues in the 2–5 year horizon. They explore new technical and market problems and test solutions that might scale as the technology matures and the economics align.
Beyond that, at the 5–10+ year mark, academic research is the key. Academia often works on foundational ideas that feel speculative today but can reshape entire industries when they break through.
An illustrative example is Ayar Labs. What started as a university collaboration on silicon photonics grew into a startup most investors ignored. Yet Ayar stayed the course, focusing on the physics-driven bottlenecks of chip-to-chip bandwidth and energy efficiency.
Fast forward to today and AI workloads have made copper interconnects unsustainable. And “suddenly” CPO is all the rage. Of course, the idea was always there for anyone watching the research a decade ago. But it took time (a decade!) for the market to demand a solution.
Robotics is following a similar path. The progress we see today started with early academic breakthroughs and scrappy prototypes. Now, general-purpose, embodied intelligence is moving from the lab to startups. At the same time, labor shortages and rising costs are creating demand for automation, sparking early interest in humanoid robots for industrial use. We can soon expect an impact on the semiconductor and AI industries, the economy, and the stock market.
When the world says it happened “suddenly,” you’ll know it was years in the making 🤓
Robots, Part 3
In Parts 1 and 2 of our robot series (here and here), we explored how robots see, from early ConvNets to the rise of vision transformers (ViTs).
Seeing is a critical first step, but vision alone isn’t enough. A robot that can’t act on what it sees is just an expensive set of mobile cameras, right?
So today we’ll jump from studying perception to understanding action. We’ll break down how robots take actions in the real world and explain why this is far more challenging than it sounds.
You might be thinking: shouldn’t robots also think? Yes. Exactly. In this piece, we’ll also cover how vision-language-action (VLA) models unify perception, reasoning, and action into one end-to-end system. VLAs enable robots to interpret goals, adapt, and act in unpredictable environments, even when encountering new objects or instructions.
We’ll conclude our deep dive into robotics by examining what these advances mean for the next several years and how Nvidia is positioning itself to lead.
💡 Bonus for paid subscribers: At the end of this article, we’ll connect these ideas to Nvidia’s full-stack robotics strategy and explain why it could drive the next big wave of physical AI. We’ll look at the impact on semiconductors, robotics, and AI hardware, and assess the competitive landscape with AMD, Google, Intel, Qualcomm, and more. Use this to think critically about what robotics might mean for your investment portfolio.
Taking Action
Symbolic Reasoning
Early robots took pre-programmed actions; imagine an industrial arm programmed to pick and place parts. Naturally, these bots couldn’t adapt to any change in the environment, like a slightly misaligned object or an unexpected obstacle.
They couldn’t perceive a problem, nor reason about it. They just blindly did what they were told.
Symbolic AI offered the first step toward true reasoning. Starting in the 1950s and 60s, symbolic AI represented the world explicitly using symbols and logic rules.
Here’s a crash course:
Early Reasoning with STRIPS
If you’re curious how this era worked, this next section is for you. Otherwise feel free to skip.
How did this symbolic reasoning, or more simply, planning work?
A landmark 1971 paper from the Stanford Research Institute laid out a symbolic AI approach for chaining logical steps into concrete actions to achieve specific goals:

With STRIPS, you define a “world model,” which is essentially explaining in code a map of the environment. For example, imagine a floor plan that describes a world made up of rooms, walls, and objects:

A programmer can turn that floor plan into a formal world model by describing all the objects and their relationships. For example, describing doors and rooms, and how the doors connect rooms:

It might look intimidating, but it’s straightforward. Door1 connects rooms 1 and 5, so Connects(Door1, Room1, Room5).
Now that you’ve described the world, you can specify actions the system can take, called operators. Each operator describes when it can be used (“preconditions”) and the effects it has on the world model:

With a well-defined world model and a set of operators, the planner can intelligently solve the problem. It starts from a given goal and keeps running until it finds a sequence of actions that leads to success:
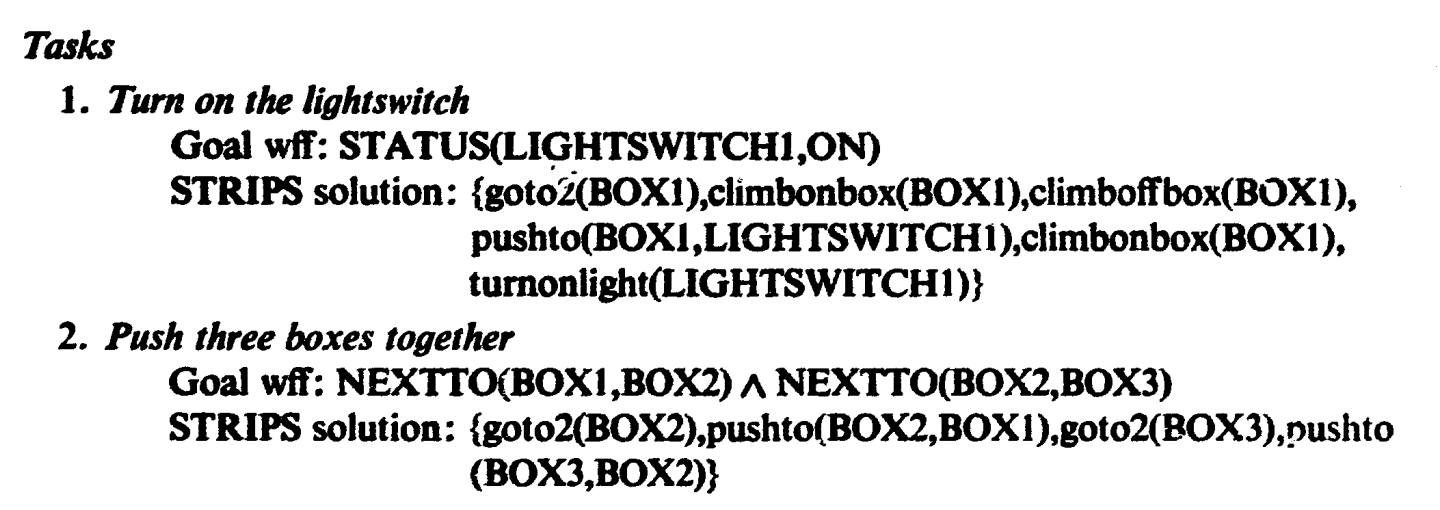
See how the planner searched for a sequence of operators that transforms the world from its current state to a desired goal state. Pretty cool!
And it was coded in LISP and ran on a PDP-10 mainframe!
As this paper illustrates, Symbolic AI was a major step forward. It showed that robots could reason through a sequence of actions instead of just following fixed scripts. These early systems felt intelligent.
But they had big limitation. Every object and rule had to be carefully hand-coded, and the world model was static. Symbolic AI worked well in tidy lab environments but fell apart in the messy real world.
This is where perception and dynamic world models come in. What if robots could truly see and understand their surroundings through sensors, update their world model on the fly, and adapt their plans accordingly?
This ability to perceive, think, and act in a changing environment is what makes robotics truly useful. My Roomba, for example, has to figure out what to do when one of my many children gets in its way. Just kidding — it’s usually me.
The team at SRI took this idea further.
Shakey, The First Robot to See, Think, and Act
An early breakthrough in closing the loop between sensing, thinking, and acting was Shakey the Robot. Shakey used a camera to map its environment into symbolic representations, such as “there’s a wall here” or “a door there.” It then reasoned about how to navigate or move objects and executed those plans.
For the first time, a robot could see, think, and act in a closed loop. This marked an important conceptual step toward true autonomy, where robots became agents rather than just programmable machines. The term “agent” here comes from “agency,” the ability to make decisions and act on them.
Shakey’s legacy includes foundational algorithms like A* search, which is still widely used in robotic pathfinding today:

A nice A* explainer for those who like to know how stuff works:
By the way, did you recognize those names (Nilsson, Raphael) from the STRIPS paper? Being first to a nascent field means you get to be the first to think deeply about the problems and invent some foundational things. Like the GOAT Claude Shannon:
Lastly, if you’re paying close attention, Shakey was invented a few years before STRIPS.
From Doing to Learning
The AI field eventually realized that hand-coding every detail about the world wouldn’t scale.
Instead of describing the world in painful detail, why not build robots that could learn and adapt — like a child?
This led researchers to machine learning. Rather than telling robots exactly what to do, they began letting them learn behaviors directly from data and interaction. Just as we saw computer vision move away from rigid, hand-crafted features toward deep, data-driven learning, robotics followed the same path.
This shift gave rise to supervised learning approaches and reinforcement learning (RL). Supervised learning helped robots improve perception tasks like recognizing objects and RL was key in teaching them how to act.
With RL, robots learn to maximize a reward signal — for example, getting a +1 for a successful grasp and 0 for a miss. This is how they learn to take actions that achieve goals rather than just passively observe.
Q-learning introduced the idea of learning the “quality” (Q-value) of taking an action in a certain state.
Later, Q-networks used neural networks to approximate these Q-values directly from raw inputs like pixels.
This is similar to how vision systems began using deep networks to automatically learn complex patterns directly from raw data, rather than relying on hand-crafted features designed by engineers.
A perfect example of all this in action is DeepMind’s Atari agent. It learned to play Breakout end-to-end, purely from pixels, by maximizing its score:
Check out the key insight about 44 seconds in.
Basically, the AI agent tries different joystick directions, watches what happens, and if the score goes up, it learns that move was good. The key point is that the AI is learning control policies end to end, without explicit programming.
Notice how this ties back to everything we’ve been discussing in this series. To succeed, the Atari agent first had to see the game screen (perception), then figure out which actions to take (thinking and planning), and finally execute those actions to hit the ball and break the bricks (acting).
Flashback
By the way, if “Q-network” and “A*” sound familiar, you might be thinking of Q* and the whole Sam Altman firing episode. Remember articles from Reuters like this
Ahead of OpenAI CEO Sam Altman’s four days in exile, several staff researchers wrote a letter to the board of directors warning of a powerful artificial intelligence discovery that they said could threaten humanity, two people familiar with the matter told Reuters.
After being contacted by Reuters, OpenAI, which declined to comment, acknowledged in an internal message to staffers a project called Q* and a letter to the board before the weekend's events, one of the people said. An OpenAI spokesperson said that the message, sent by long-time executive Mira Murati, alerted staff to certain media stories without commenting on their accuracy.
Some at OpenAI believe Q* (pronounced Q-Star) could be a breakthrough in the startup's search for what's known as artificial general intelligence (AGI), one of the people told Reuters. OpenAI defines AGI as autonomous systems that surpass humans in most economically valuable tasks.
and this:
ChatGPT maker OpenAI is working on a novel approach to its artificial intelligence models in a project code-named “Strawberry,” according to a person familiar with the matter and internal documentation reviewed by Reuters.
The Strawberry project was formerly known as Q*.
So, now that you know a tiny bit about A* and Q-networks, you can appreciate that the name Q* suggests combining both. it suggests combining these two ideas: using learned value functions (Q-values) together with explicit, structured planning (like A*) to make decisions that are both adaptive and efficient.
In other words, Q* hints at a system that can both learn from experience and plan ahead, just like how we want robots (and future AI agents) to perceive, think, and act.
Anyway, back to robots taking action and learning.
Learning in Simulation
So with RL, robotic arms learned to pick up objects by maximizing reward functions. But real-world trial and error is slow, costly, and can damage hardware. To speed things up, researchers turned to high-fidelity simulators. Tools like MuJoCo (Multi-Joint dynamics with Contact) let robots run millions of practice runs virtually, far faster than in the real world and without any wear and tear. Sort of like Neo practicing against Morpheus in the dojo scene of The Matrix.

However, policies trained purely in simulation often fail in reality because of the reality gap. These are the differences in physics, textures, lighting, and sensor noise that cause a robot to stumble when deployed outside the lab.

To bridge this gap, researchers invented domain randomization. Instead of creating one perfect simulated environment, they varied everything: colors, lighting, surface friction, object shapes, and more. In essence, they generated vast amounts of realistic synthetic data.
By exposing robots to countless randomized situations, the learned policies became less sensitive to any one condition and more able to generalize. The payoff is that when transferred to the real world, these robots often worked surprisingly well right out of the box!
Synthetic data and randomization is important for autonomous driving. A nice explainer from the Nvidia archives:
A great example of the power of training on synthetic data is OpenAI’s Rubik’s Cube robotic hand from 2018. Trained entirely in simulation with heavy domain randomization, it could manipulate the cube in the real world without any further fine-tuning. In the demonstration, you could even put a rubber glove on the hand, and it still worked! Check out this impressive video:
As OpenAI said in the video,
Instead of trying to write very specific algorithms to operate such a hand, we took a different approach. We created thousands of different simulated environments and trained the robot to solve the task in all of them, hoping it would then succeed in the real world. This process is like giving the network thousands of years of practice in simulation. Every time the algorithm gets good at a task, we make the task harder. That’s crucial because you need exposure to complex situations to eventually handle real-world challenges.
For example, you can put a rubber glove on the robotic hand, and it can still perform the task. This ability to generalize to new environments feels like a core piece of intelligence. It really changes the way we think about training general-purpose robots — moving away from obsessing over specific algorithms and instead focusing on creating complex enough worlds where they can learn.
In case you missed it, OpenAI didn’t start out trying to create ChatGPT. In Ben Thompson’s interview with Sam Altman, Sam shared that OpenAI began as a pure research lab, with no business model and no clear plan beyond exploring AI. Their earliest work focused on reinforcement learning agents that played video games, not language models.
Sam Altman: One thing that I think has been lost to the dustbin of history is the incredible degree to which when we started OpenAI, it was a research lab with no idea, no even sketch of an idea.
Ben Thompson: Transformers didn’t even exist.
SA: They didn’t even exist. We were like making systems like RL agents to play video games.
BT: Right, I was going to bring up the video game point. Exactly, that was like your first release.
SA: So we had no business model or idea of a business model and then in fact at that point we didn’t even really appreciate how expensive the computers were going to need to get, and so we thought maybe we could just be a research lab. But the degree to which those early years felt like an academic research lab lost in the wilderness trying to figure out what to do and then just knocking down each problem as it came in front of us, not just the research problems, but the like, “What should our structure be?”, “How are we going to make money?”, “How much money do we need?”, “How do we build compute?”, we’ve had to do a lot of things.
This isn’t just a fun historical aside (although it is!) But understanding OpenAI’s roots helps explain its strengths and weaknesses today. The company has a culture rooted in research and exploration, but also tension among early hires who joined a research lab and later found themselves in a consumer tech company.
At the end of the day, all these stories, from robotic arms to Rubik’s Cube hands to video-game agents, point to the same key idea: to build truly useful robotics we need to close the loop. We must create systems that can perceive the world, think and plan, and act effectively.
This same principle extends far beyond robotic arms on lab tables. We see it come to life in dynamic robots operating in the real world, like autonomous vehicles.
Dynamic Robots like Autonomous Vehicles
I wanted to pit stop (pun intended) here for a minute given all the hype around robotaxis. Feel free to skip.
As you might expect by now, early self-driving efforts relied on rigid, rule-based systems too. An awesome example that I came across is the Prometheus project from 1986.
The Prometheus Project: Pioneering Autonomous Action
Prometheus was a massive 5-ton Mercedes van equipped with four cameras and 60 “transputers,” which were early parallel processors.
Perception and decision-making powered by cameras and parallel computing. Sound familiar?!
In 1995, it drove from Munich to Copenhagen and back, a round trip of over 1,000 miles. Impressively, Prometheus managed nearly 100 miles in one stretch without human intervention, even reaching top speeds above 100 mph 😂 must have been on the Autobahn!
Built with symbolic AI, the system explicitly represented objects and vehicles using state estimates like location and velocity. Decisions such as lane changes and overtaking were based on programmed rules rather than learned from data. There was no large-scale data-driven learning or end-to-end neural networks; instead, the system depended on human-engineered models to guide perception and action.
Prometheus directly influenced the development of key driver assistance technologies, including adaptive cruise control, lane departure warning, and automatic emergency braking. More broadly, it laid the conceptual groundwork for later milestones in autonomous vehicles, from the DARPA Grand Challenge to today’s robotaxi efforts.
Here’s a fun video discussing that era:
Such early groundwork! The video mentions data fusion from multiple sensors, tracking other vehicles, estimating other vehicles relative to the ego vehicle. We did all of that when I was working on autonomous tractors, albeit decades later!
The Need to Generalize
Even though projects like Prometheus made significant progress, they were fundamentally narrow. Robots of that era performed specific tasks very well but failed when faced with something new. A robot trained to pick up a mug might completely fail when asked to handle a water bottle. A self-driving car tuned for California highways might struggle on a New England winter day. Each new object, surface, or situation often needs new data, more engineering, and maybe an entirely new model.
Obviously, this narrow rigidity is the opposite of human flexibility. We can walk into an unfamiliar kitchen and find a mug. Californian drivers can adapt to a New England winter day.
This ability to generalize is needed to unlock autonomous vehicles and humanoid robotics.
Robotics researchers saw that narrow, single-task robots would never match human flexibility. Inspired by language models that learn broad patterns from massive data, they began to imagine robots that could adapt and generalize.
This vision builds on everything we've discussed. Just as vision systems evolved from fixed features to transformers, robotics is moving from rigid programs to systems that learn and handle the unexpected.
So how can see messy real-world environments and handle new situations?
This is where Visual Language Action (VLA) models come in.
Visual Language Action (VLA) Models
VLAs help robots generalize more like humans! They combine visual perception, language understanding, and action into one unified system.
A great place to start is OpenVLA, an open-source 7B parameter model trained on nearly a million real-world robot demonstrations from a team spanning Stanford, UC Berkeley, Toyota Research Institute, Google DeepMind, Physical Intelligence, and MIT.
Instead of stitching together separate vision, planning, and control modules, OpenVLA takes a visual scene and a natural language prompt and turns them directly into a sequence of actions:
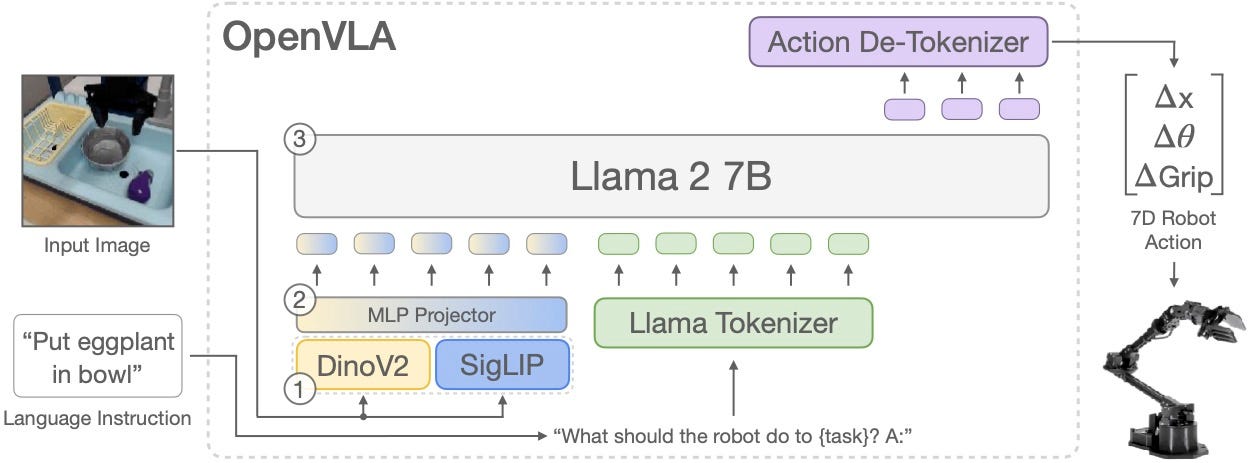
That makes prompts like these possible:

A big reason this is now possible is the rise of Vision Transformers (ViTs), which we covered in Part 2. ViTs moved us beyond rigid convolutional approaches toward flexible, data-driven visual understanding.
OpenVLA builds on this by using ViTs and even stronger vision encoders like DINOv2 from Meta AI and SigLIP from Google DeepMind. These models create visual features that feed into large language models, allowing robots to connect what they see with what they are told to do.
Without language models trained on the world’s knowledge, robots can’t handle new situations. By combining strong vision encoders with a language backbone like Llama 2, OpenVLA can understand both scenes and instructions, even with new objects or in unfamiliar settings!
Why does this matter? Because it moves robotics closer to true compositionality. As articulated nicely here,
Effective task representations should facilitate compositionality, such that after learning a variety of basic tasks, an agent can perform compound tasks consisting of multiple steps simply by composing the representations of the constituent steps together.
Just as a large language model can write a sentence it’s never explicitly seen before, a vision-language-action (VLA) model can sequence new physical behaviors by recombining learned motion primitives. It’s assembling skills to solve new tasks, much like a language model writes new sentences it has never seen before.
OpenVLA showed as much. It was tested on many generalization tasks, including new backgrounds, object shapes, positions, and instructions:
We test OpenVLA across a wide range of generalization tasks, such as visual (unseen backgrounds, distractor objects, colors/appearances of objects); motion (unseen object positions/orientations); physical (unseen object sizes/shapes); and semantic (unseen target objects, instructions, and concepts from the Internet) generalization.
While OpenVLA does not use explicit symbolic compositional mechanisms, it shows the ability to generalize across objects, scenes, and instructions with minimal data.
The “Move Coke can to Taylor Swift” example captures this perfectly:
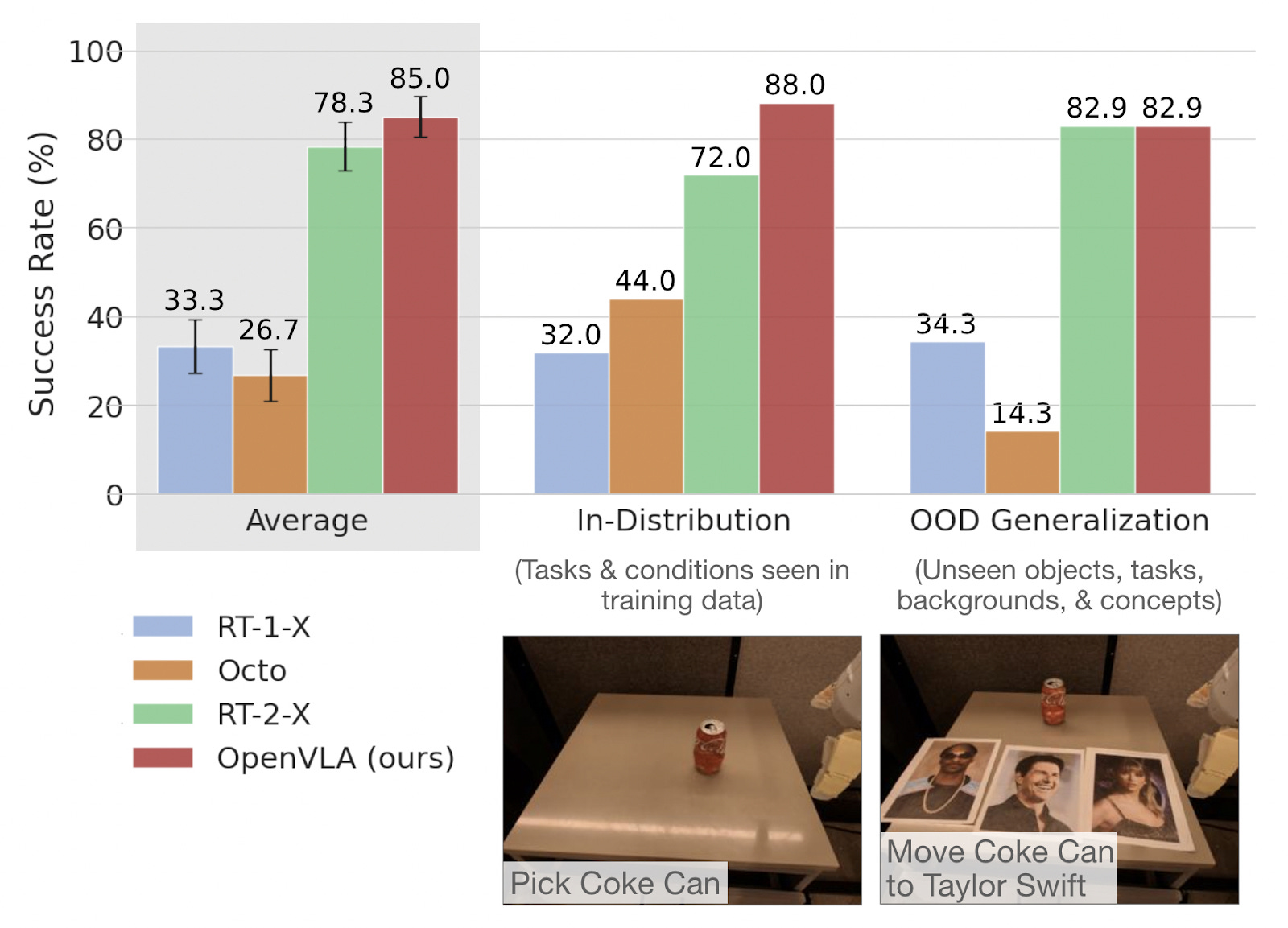
The model understands internet-scale concepts and recombines learned behaviors in new ways. See the promising out-of-distribution (OOD) generalization results in the top right.
OpenVLA also works across different robots, not just one setup! It supports multiple robot arms out of the box and can be quickly adapted to new hardware with minimal fine-tuning. The full model and training pipeline are open source and available on Hugging Face.
VLAs make generalist robotics possible. They combine large-scale robot demonstrations and internet-trained language models to create robots that see, think, and act in the real world. This finally closes the loop, turning robots from rigid tools into adaptive partners.
This is why humanoids are suddenly possible!
And why Nvidia is ready.
Nvidia’s Full-Stack Robotics Strategy
In the subscriber-only section, we’ll connect all these ideas to Nvidia’s full robotics stack and strategy and break down why it matters for semiconductors and the future of AI hardware.
We’ll cover:
The “three computers” architecture for training, simulation, and edge inference
Competition including Google, AMD, Intel, Qualcomm, and more
Omniverse and Cosmos for simulation and synthetic data
Isaac Sim and Isaac Lab for closing the simulation-to-reality gap and scaling robot policy learning
Project GR00T, foundation models and data pipelines for humanoid robots
Jetson AGX Thor, bringing data center-level AI performance directly to the edge.
How this strategy reshapes the semiconductor stack
The rise of distributed AI in robotics
We’ll unpack how Nvidia is building a vertically integrated platform to lead in physical AI, and why Jensen believes it might become “the largest industry of all”.