

The Multi-Silicon Era Is Here
Disagg is out of the bag. What it means for Nvidia, CPUs, XPUs, startups, and more.

QUICK HITS
Disaggregation is now official Nvidia doctrine. Not just a startup pitch.
Agentic AI is the killer app driving all of this. Vera CPU racks because CPUs were bottlenecking GPUs. LPUs for ultra-low latency coding agents.
Nvidia’s strategy hasn’t changed. The whole system must beat any mix-and-match alternative. Does InferenceX sufficiently measure Agentic AI Factory performance?
The unbundling of inference workloads is the unbundling of the datacenter. If Groq can slot in, so can Cerebras, Etched, MatX, AMD. Conceptually, anyway…
Without further ado, the most important slide from GTC 2026, demonstrating that Nvidia GPUs plus AI ASICs lead to a better and expanded Pareto frontier:
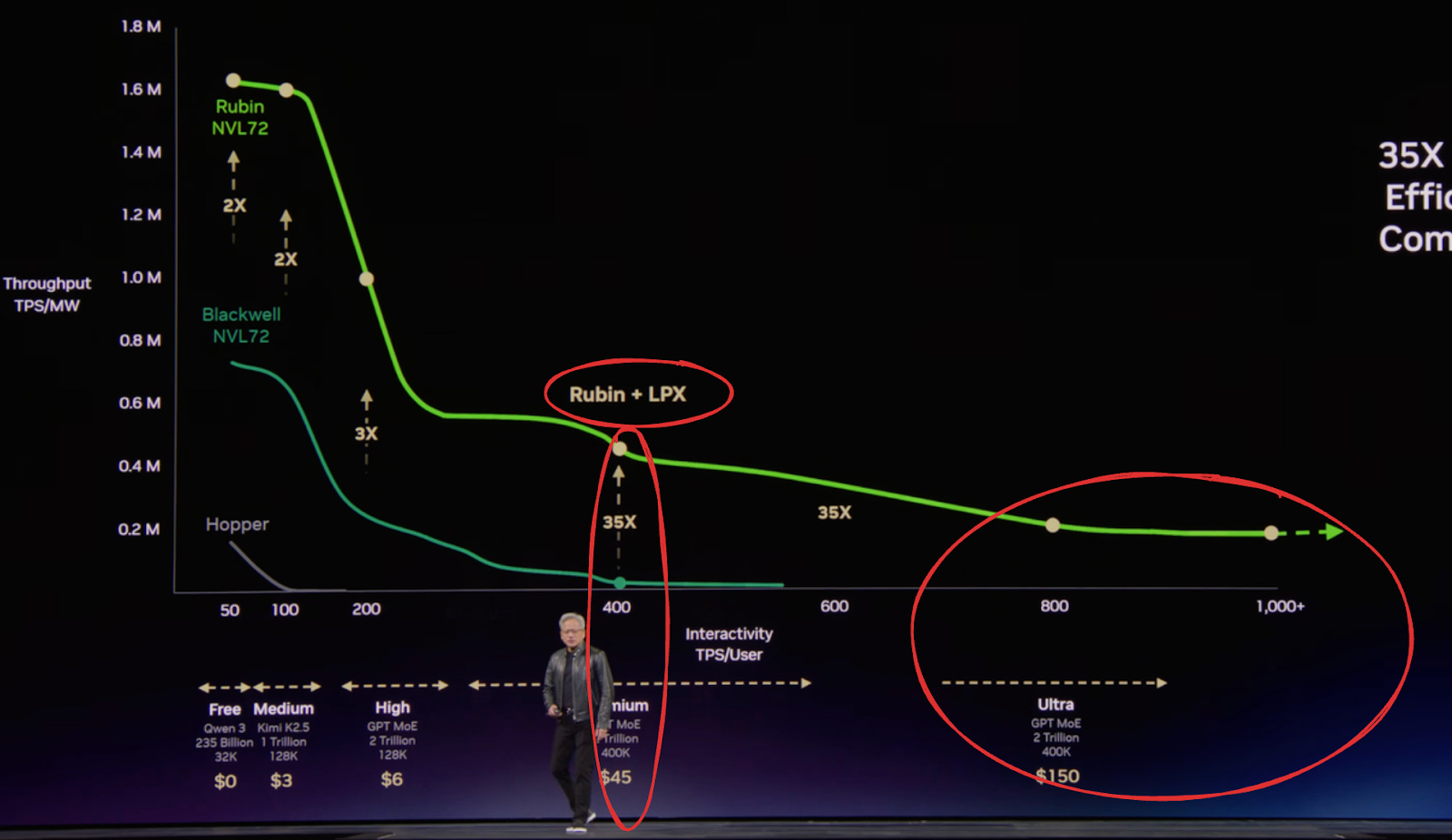
Want to unlock super low latency (or very high tokens/sec) for insanely fast Claude coding? ABC – Always Be Claudin’, amiright?
You got it! GPU + LPU. See the far right side of the chart.
Disaggregation unlocks “right silicon for the workload”. And the right silicon isn’t always GPUs; a bunch of Groq’s chips can tally up much more bandwidth for memory-bandwidth bound workloads:

Yet Rubin has way more FLOPs for compute-bound workloads. So put the two together, and you can outperform just GPUs. Of course it will cost you $$$, but for certain customers and points on the Pareto curve it can make economic sense.
To be fair, disagg has been out of the bag for over a year now, but the full ramifications are becoming clear. In the past year we learned of Dynamo and prefill/decode disaggregation. And we even saw Nvidia unveil the Rubin CPX as a SKU specifically for prefill. But that was still just splitting the workload amongst GPUs. But now we see further disaggregation, and AI ASICs have entered the picture:
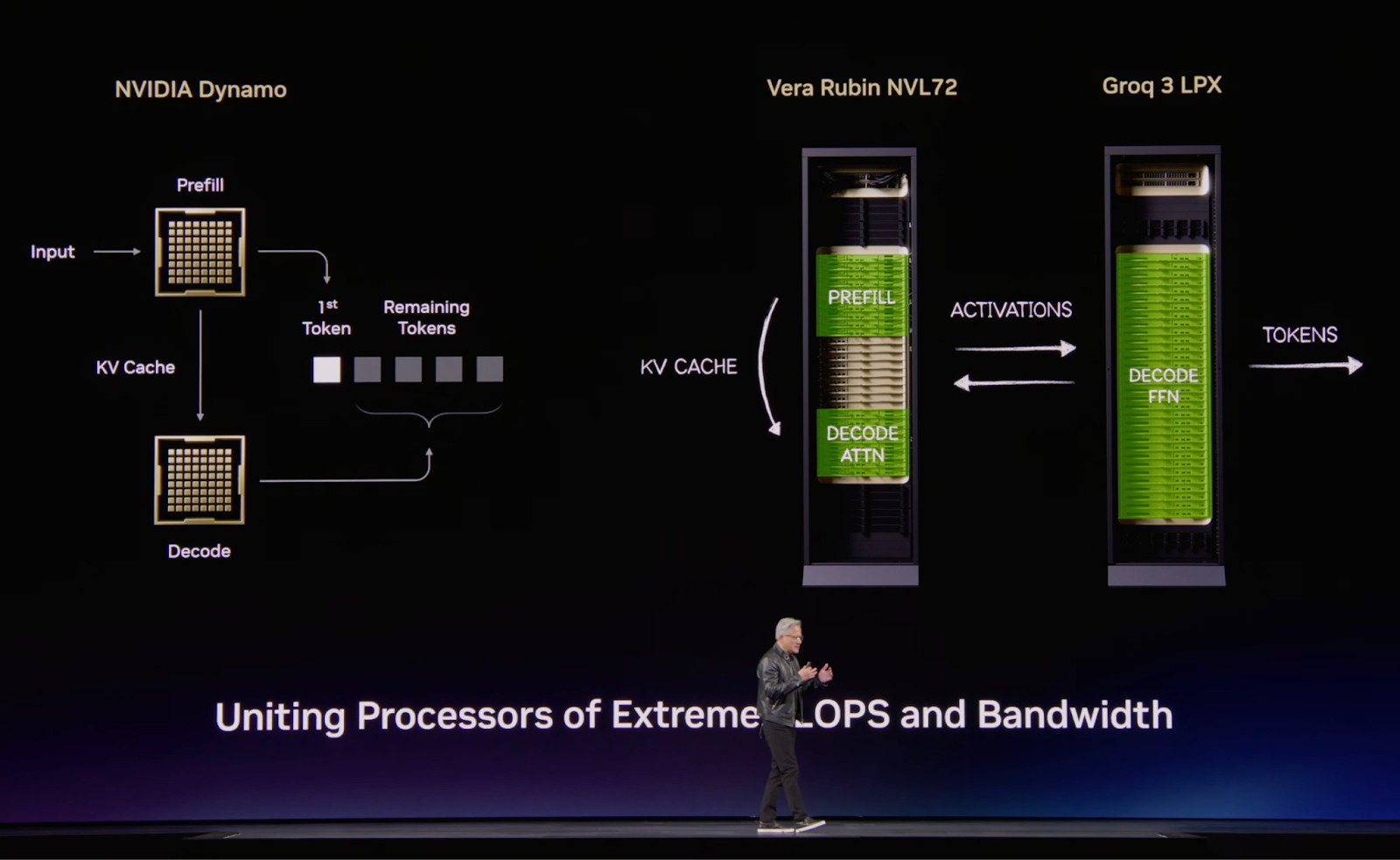
So GPUs aren’t enough!
The narrative has officially moved past GPU for everything, as said on Nvidia’s blog:
Hardware tuned for peak throughput under large batches isn’t ideal for the most latency-sensitive execution paths, while hardware optimized for low-latency execution is less efficient for the most compute-intensive phases.
Multi-Vendor Inference
It’s not a stretch to call this a multi-vendor inference system. Or a heterogeneous system if you prefer. Sure, it’s the Groq 3 LPU with an Nvidia label on it, but conceptually its an AI ASIC startup rack with an Nvidia GPU rack.
Hence, the corollary: If Groq racks can be slotted in, so can Cerebras, MatX, Etched, AMD, Intel, and so on.
The unbundling of the workload is the unbundling the AI inference datacenter.
That said, although the narrative has changed from “GPUs for everything” to “right silicon for the workload”, I’d argue that Nvidia’s strategy hasn’t changed one bit.
I’d sum up Nvidia’s strategy as ensuring that the whole inference system is greater than the sum of the parts. Said another way, Nvidia is betting that full Nvidia inference AI clusters will outperform competitive clusters piecemealed together from different vendors.
And Nvidia is betting that outperformance is unlocked through vertical integration. Think Apple, Tesla.
Take Nvidia GPUs vs AMD Instinct GPUs as an example. When AMD first came on the scene, even though MI300X was a good inference chip, it didn’t have performant enough software to extract all the value from the chip. So Nvidia’s whole system (H100s + CUDA) was better than AMD (MI300 + ROCm).
Grace Blackwell NVL72 took it up a notch. The scale-up NVLink switch enabled Nvidia to have 72 GPUs acting as one big GPU. Thus, Nvidia’s whole system (accelerator + scale-up networking + software) outperformed AMD MI350, which didn’t have competitive scale-up networking technology. AMD won’t have a scale-up domain size of 72 until MI450 with Helios, and even then, it’s UALoE.
And Nvidia is already showing they’ll be running further ahead with a portfolio of inference-centric offerings like the Vera CPU racks for agentic AI and the STX Storage racks:

Just look at that row of CPU + GPU + LPU + switches + storage. Whatever agentic AI factory you can put together, can it outperform this fully integrated system? And was the opportunity cost of sourcing it all, hooking it up, validating it, and making sure the software works across it all worth it?
Again, even though disagg is out of the bag, Nvidia believes it can outperform an “open” modular system with components from different vendors, e.g. CPU and GPU from AMD, AI ASIC from a startup, scale-up switch from Celestica / HPE / Astera Labs / etc.
Agentic AI is GenAI’s Killer App
Given that Nvidia is competing on “full AI factory performance”, it’s no wonder Nvidia is shipping Vera CPU racks.
No, Nvidia isn’t trying to take down Intel or AMD.
It’s much simpler. What was the North Star? The whole is greater than the sum of the parts.
And the “killer app” for GenAI has appeared; it’s agentic AI. Claude Code. OpenClaw. The world will never be the same.
And Nvidia wants to make the best Agentic AI Factory.
Agentic AI involves a lot of tool calling, data processing, and so on. The head node CPUs can’t handle it all. So Nvidia added two racks of Vera CPUs in the same row as all the GPUs, optimized for agentic AI. From Ben Thompson’s interview with Jensen after the keynote:
JH: ... you want the fastest single-threaded computer you can possibly get… the most important thing is single-threaded performance and the I/O has to be really great… if the CPU gets throttled, then we’re holding back a whole bunch of GPUs.
Clearly, Jensen is thinking about making the whole Agentic AI Factory greater than the sum of the parts. CPU was a bottleneck, so CPU racks were included.
And we want agents to be fast. Generating code is awesome. Generating hours worth of code in minutes is even more awesome. High interactivity is necessary for agentic AI, hence LPUs.
Implications
So disagg is out of the bag, and now many implications and questions are piling up:
What does “right silicon for the workload” mean for the CPU market when agentic AI is the killer app?
If the datacenter can be disaggregated, the door is open for other SKUs… but can they actually slot in? Will Dynamo allow it? Will an open alternative emerge?
Where do XPUs fit?
What about other Pareto frontiers? Why only the largest models at 1000+ token throughput? What about medium or small models at 1000+ tokens?
I have strong views on all of these, and more. Let’s go deeper.