

Nvidia's Climb to $4T and the Peaks Ahead
Inference is scaling, autonomy and robotics are trillion-dollar markets, strength of annual cadence + limited supply, China's big future upside & risks

Nvidia is now worth $4 trillion. Peak? Nope. Just a checkpoint. This company has a habit of turning summits into basecamps.
To see why $4T is a milestone rather than the peak, we’ll retrace Nvidia’s rise from dominating the training era to powering the macro shift to inference. Then we’ll look ahead. Agentic AI, autonomy, and robotics are each shaping up to become a trillion-dollar market in their own right.
We’ll also explore why constrained supply has quietly been a strength and why Nvidia’s long-term growth will hinge on access to China, the world’s most strategically important market for physical AI.
If you’re tired of Nvidia being caught in geopolitical crossfire… its future is even more entangled with China.
The First Trillion
Nvidia’s first trillion-dollar milestone was the payoff of being the first and best platform for large-scale AI training.
Chips alone weren’t enough. Nvidia had to control the full system to make clusters scale. It already had the parallel compute (GPUs) and the software (CUDA). The missing piece was high-bandwidth interconnect.
That came in 2019 with the Mellanox acquisition. From the press release:
Datacenters in the future will be architected as giant compute engines with tens of thousands of compute nodes, designed holistically with their interconnects for optimal performance.
That vision came true faster than expected.
As transformer-based LLMs took off, training needs exploded. Only two companies had the AI stack to meet that scale: Nvidia and Google.
Yes, Google.
Over the past decade, Google built its own accelerated computing platform, including high-bandwidth interconnects. As Google Cloud’s blog recounts,
“In late 2014, when TPU v1 was being fabbed, we realized training capability was the limiting factor... So we built an interconnected machine with 256 TPU chips connected with a very high-bandwidth, custom interconnect to really get a lot of horsepower behind training models”
But Google doesn’t sell silicon. TPUs were kept internal for years and only became available through Google Cloud in 2018. GCP remains a small slice (~10%) of Google’s ad-driven business. And while TPUs delivered strong performance on internal workloads, they lacked a robust external-facing software ecosystem. Combined with Google’s track record of shelving side projects, TPUs were never a serious option for the broader market.
Nvidia, by contrast, exists to sell silicon.
Nvidia was the first, best, and only option for labs training at the frontier.
OpenAI, Meta, xAI, and others all built on its stack. Even Google used Nvidia P100s to train the original transformer model.
Yet for Nvidia’s market cap to take off, something was needed to drive industry enthusiasm and investment in training clusters.
ChatGPT was that spark.
By late 2022, ChatGPT’s viral launch revealed how disruptive large language models could be. OpenAI’s Nick Turley, Head of ChatGPT, recalls:
Everyone has their slightly own recollection of that era because it was a very confusing time. For me, day one was "Is the dashboard broken? The logging can’t be right".
Day two was like, "Oh, weird. I guess Japanese Reddit users discovered this thing. Maybe it’s like a local phenomenon."
Day three was like, "Okay, it's going viral, but it's definitely gonna die off."
And then by day four, you're like, "Okay, it's gonna change the world."
ChatGPT’s rapid rise prompted increased investment in developing more advanced models, not only by OpenAI but also by competitors.
OpenAI soon uncovered a scaling law too. More compute, more data, and larger models consistently yielded better performance.
That combination—ChatGPT’s popularity and the scaling law—ignited a wave of training cluster buildouts, funded by hyperscalers and powered by Nvidia’s GPUs, interconnects, and software.
Nvidia made the GenAI buildout possible. But wouldn’t rivals move quickly to challenge its dominance in large-scale training?
They couldn’t.
Nvidia’s scale-up and scale-out interconnect hardware is only half the battle. Efficient training at scale requires ultra-low-latency, lossless communication across accelerators. That’s where software comes in. Nvidia’s NCCL (NVIDIA Collective Communications Library) synchronizes gradients and parameters across massive clusters, making frontier-scale training even possible.
Getting this right is hard. It’s one reason AMD Instinct focused on inference first, and only later began catching up with RCCL. Same reason why AI accelerator startups focus on inference.
So when the GenAI wave hit, Nvidia was the only supplier with a production-ready, massively scalable training solution, software included.
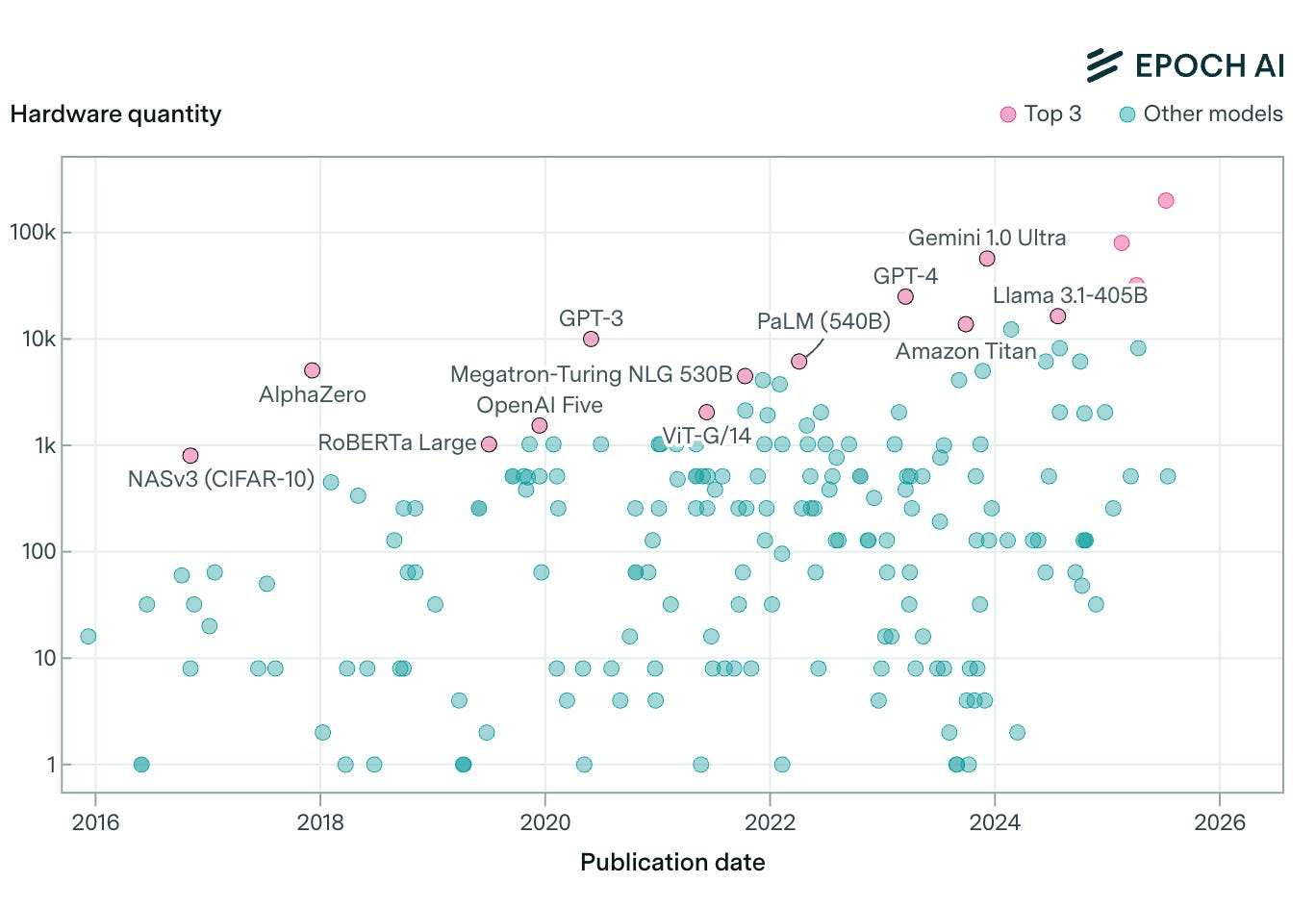
Consider the best models over time:

All Nvidia. And look at the cluster size explode.
Nvidia’s 2019 mention of “tens of thousands of compute nodes” from the Mellanox acquisition press release seems both prescient and quaint, doesn’t it?
That’s why Nvidia’s market cap shot up to $1T by May 2023. The best and only option to fuel training scaling.
But Was It Sustainable?
At the $1 trillion mark, the big question was whether Nvidia’s growth was sustainable.
CapEx from its top customers was soaring, but there must be a ceiling, right?
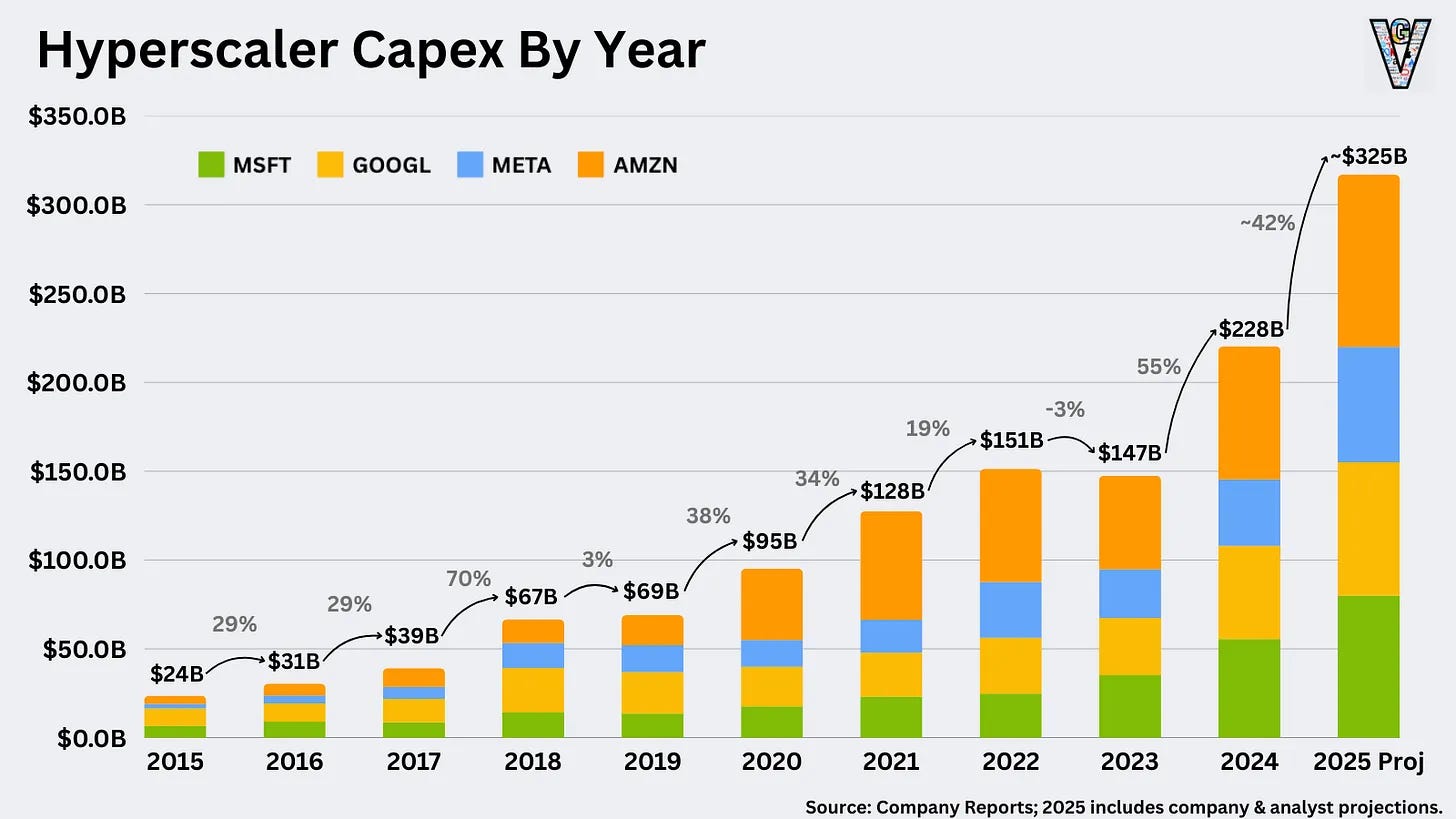
It wasn’t clear how long training clusters could keep scaling before hitting diminishing returns.
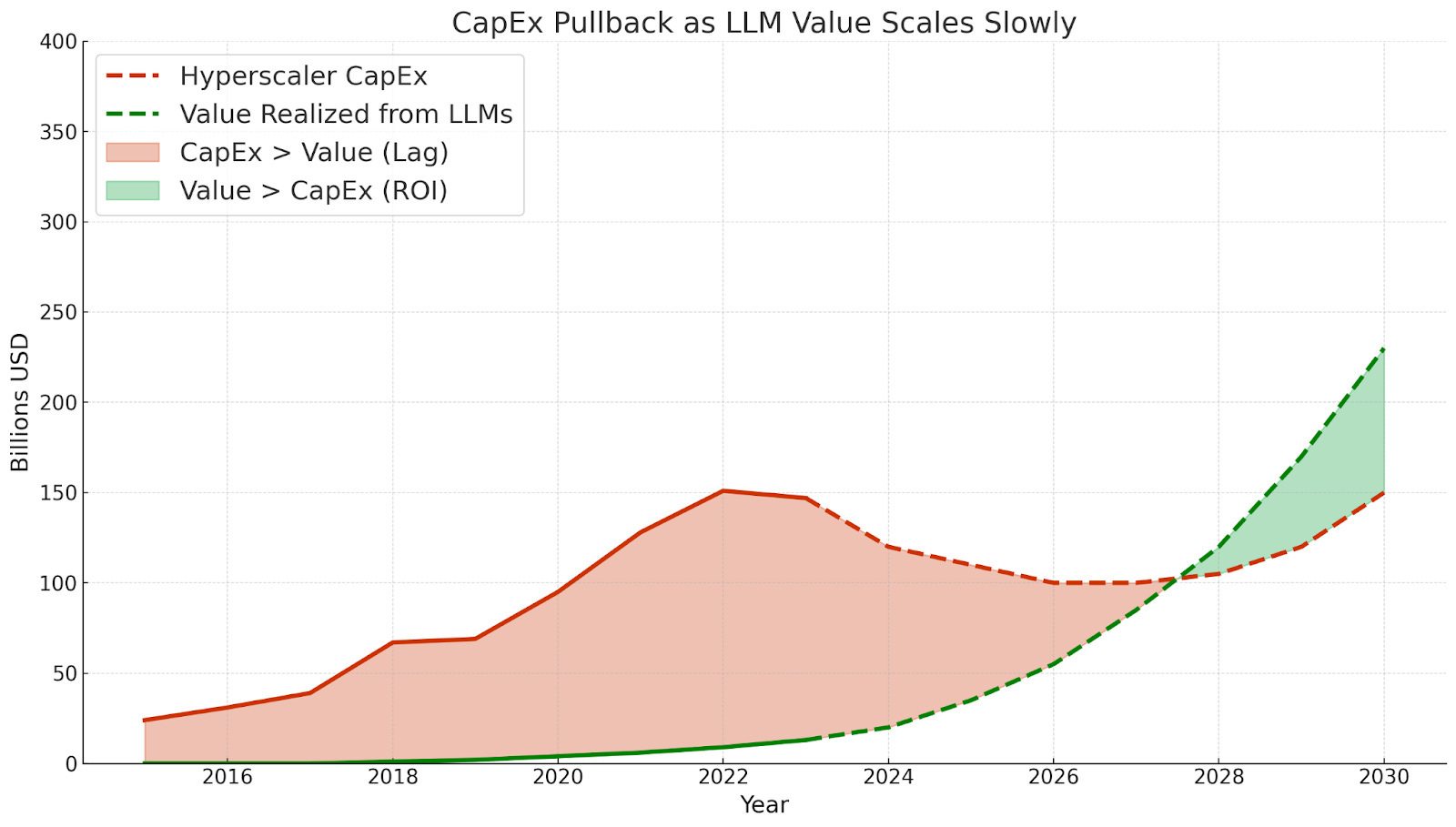
There was real concern about a gap between infrastructure buildout and realized value. LLMs take time to monetize, and CFOs won’t fund massive CapEx ahead of proof forever. A pullback felt possible. History offers plenty of cautionary tales: dot-com datacenters built in 1999 and fiber that sat idle until cloud demand materialized. Nvidia faced a similar risk that GPU clusters might outpace adoption, leaving capacity stranded.
Of course the AGI optimists on X didn’t dwell on this. But if you listened to the voices near the purse strings, the doubt was there.
Here’s my attempt at visually depicting how this pullback scenario could have played out:
At the same time, in 2023 there was another possible future, one where value was clear as these models were deployed, and thus CapEx continued to grow
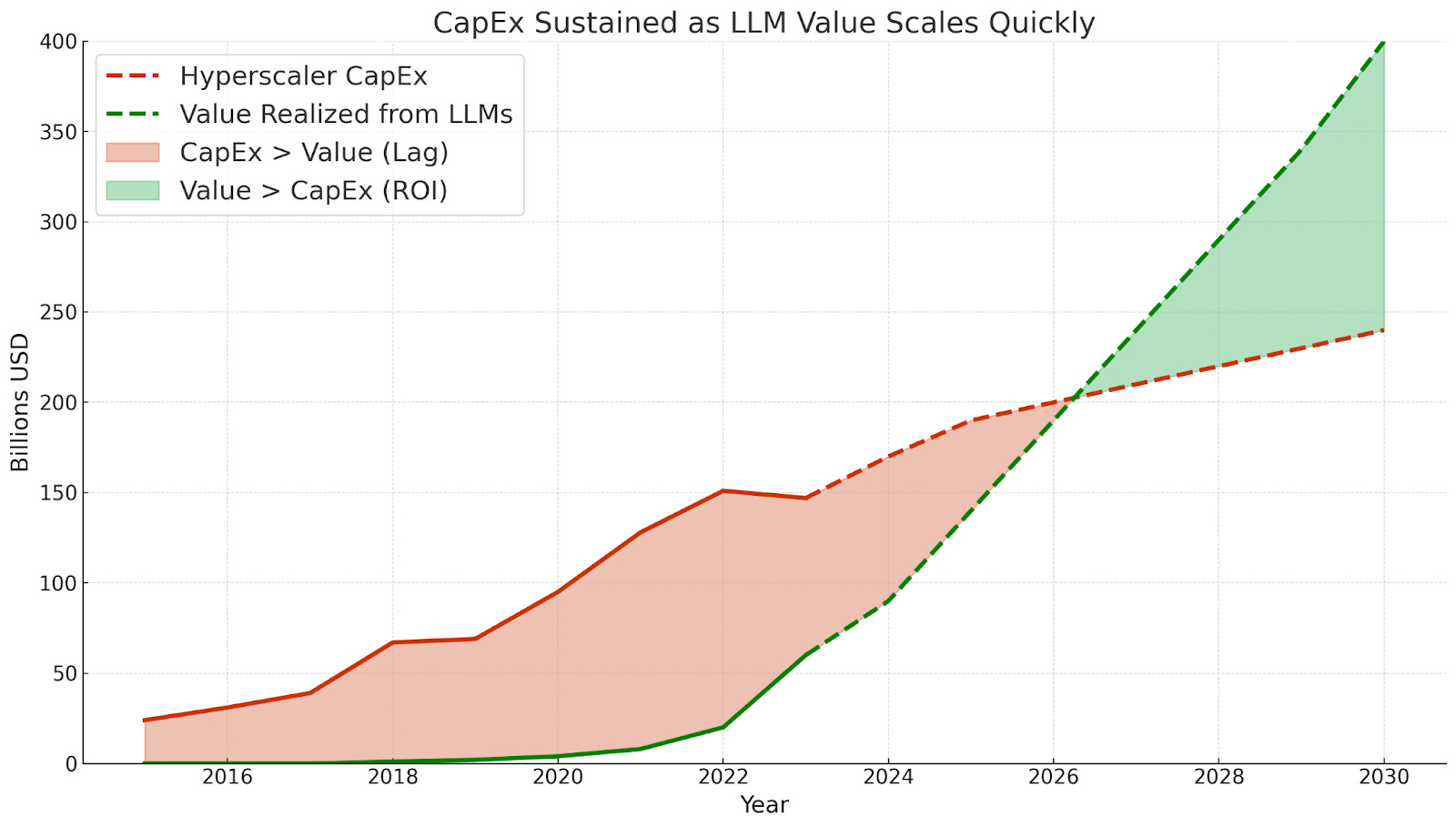
Fortunately for Nvidia, this is the path we’re on!
Inference is here, and while ROI is hard to quantify, it’s definitely compounding.
We’re off the shaky ground of training scaling hope and into the inference era.
Inference Takes The Torch
And inference volume is scaling fast.
On the consumer side, ChatGPT reportedly reached 1 billion weekly users in under three years. For comparison, TikTok and Facebook Messenger took about five years, while Instagram, Facebook, and YouTube nearly eight years to reach 1 billion monthly users.
Let that sink in. ChatGPT is likely the fastest application ever to reach 1 billion users, by far. Brought to you by Nvidia-powered inference.
ChatGPT processes ~2.5 billion queries per day! 😮💨
This isn’t just a training story anymore. Nvidia’s business now rests on massive, sustained inference at scale.
Some thoughts for another day:
2.5B queries per day makes the case that an advertising-supported business model would be rational…
And it suggests strong product-market fit; but what is the market(s)? Could these each be broken out into vertical companies with better user experience for the particular workflow, e.g. Cursor, and will this diminish the chat interface dominance or just be additive?
It’s not just OpenAI; Gemini claims at least 400M MAUs too. That means TPU volume will keep scaling, which is good news for the custom AI accelerator supply chain. It helps that Google’s biggest apps, such as YouTube, Gmail, Maps, and Android, are all internal customers with massive user bases.
Commercial adoption of LLMs is accelerating. Across industries, GenAI is driving measurable productivity by reducing costs in customer support, accelerating code generation, enhancing marketing copy, and speeding up research.
The ROI case includes both cost savings and increased output.
Here’s an eye-opening anecdote from the Wall Street Journal. Accounting firm RSM is finding enough value in generative AI to justify a fivefold increase in its GenAI investment!
RSM’s U.S. unit plans to invest $1 billion in artificial intelligence over the next three years, well above its previous investments, in part to use AI agents to automate more tax and accounting workflows.
The funds would go toward integrating generative AI into internal workflows as well as platforms the firm provides to middle-market companies and overall helping clients with their AI strategies, said Sergio de la Fe, enterprise digital leader and partner with RSM US. Some of the $1 billion will also go toward building the core AI infrastructure predictive models, talent upskilling and partnerships.
The investment marks a step up from the $150 million to $200 million that the Chicago-based firm spent on AI the past three years, as well as an opportunity to codify and industrialize its AI work, de la Fe said.
Previously it had made generative AI tools available to individual employees, but found that workers weren’t always using them consistently or prompting them effectively at any given step of the process.
Now the firm has stitched together multistep workflows that it can automate through agents, AI systems that can take actions or make decisions on behalf of people, bringing what was previously a 5% to 25% productivity boost to up to 80% in some cases.
Note two things from this RSM anecdote.
First, given Nvidia controls nearly 90 percent of AI infrastructure revenue, it’s safe to assume RSM’s generative AI workloads most likely run on Nvidia hardware:
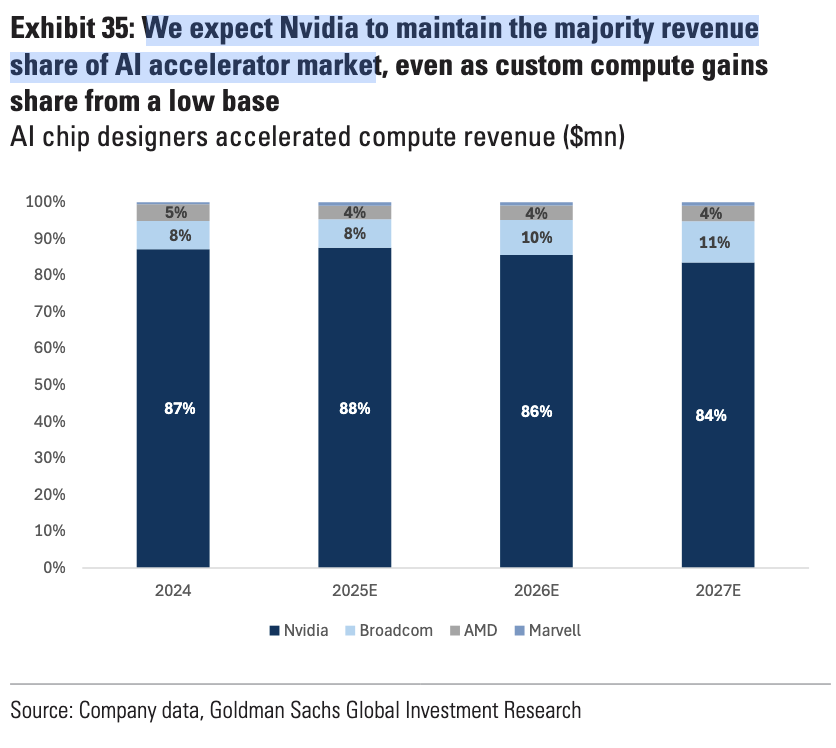
So enterprises like RSM are seeing value and increasing investment, to the benefit of Nvidia.
The Importance of Reasoning Models
Second, agentic AI is the core unlock. RSM connected multiple tasks into automated workflows powered by agents that can take action or make decisions. This shift increased productivity significantly.
That kind of leap comes from reasoning models like OpenAI’s o3. These models can plan, understand cause and effect, use tools, and recover when things go wrong. In contrast to fast-thinking AI, which many saw as limited in usefulness and ROI, reasoning models arrived just in time to break through those concerns.
And RSM shows how valuable this can be for enterprise adoption.
At face value, reasoning models are bullish for Nvidia. When AI can reason, those GPUs generate more value across more use cases.
But there’s an even more important implementation detail. Agentic “thinking” increases the amount of tokens generated per query, often by 5 to 10 times. That means each use case demands more compute!
This combination—more use cases and more compute per use case—drives higher GPU utilization and stronger demand for FLOPs. Nvidia benefits from both.
There’s even a downstream effect. Higher utilization leads to shorter hardware lifetimes, which will further reinforce demand.

Agentic AI will drive ROI, and not just for early adopters like RSM.
The result is sustained infrastructure growth across the industry, the benefit which largely accrues to Nvidia.
Agentic AI Drives Demand, And Value
The shift to agentic AI is in the earliest of innings. New tooling is arriving quickly, from MCP to Computer-Using Agent to Windows AI Foundry. As they mature, more ambitious projects will emerge. Adoption will grow. So will token demand.
Nvidia is ready. The DGX platform, which excels at training, is already optimized for scaled inference too. On the software side, the new Dynamo platform dynamically routes inference workloads, maximizing utilization across the entire AI datacenter.
And it’s selling like hotcakes. The Blackwell architecture is ramping faster than any chip in Nvidia’s history. Major hyperscalers are now deploying nearly 1,000 NVL72 racks every week (72K GPUs weekly!)
Blackwell Ultra is also coming online, offering even greater efficiency and a lower cost per token. CoreWeave and Dell are already shipping GB300-based NVL72 systems, with more to follow.

This agentic inference era is why Nvidia’s $4T valuation is defensible and perhaps still conservative.
Value is already being realized. Inference volumes are exploding. And the models themselves are becoming more capable by the month.
If you think today’s text-based AI is compute-intensive, just wait for multimodal workloads to become a fad. Video-generation alone could dwarf current demand. Remember what the Ghibli fad did to GPU utilization?
Images are but one frame of a video, which is much more computationally intensive.
Netflix is using GenAI in production already, and Disney is kicking the tires too. Just wait until the kids go crazy with video.
Limited Supply Helps Avoid an AI Bubble?!
One underappreciated driver of Nvidia’s sustained revenue growth is the persistent constraint on supply. The AI infrastructure buildout is unfolding more slowly than demand suggests, largely due to TSMC’s limited CoWoS advanced packaging capacity and the time-intensive process of building liquid-cooled datacenters with sufficient power access.
This is actually good for Nvidia! It keeps prices high, stretches demand across multiple quarters, and gives customers time to realize returns before doubling down on their investments.
Gating supply while value builds is very important. If CapEx was unconstrained, we would have seen a larger ROI lag sooner, which would have freaked CFOs out and increased the risk of CapEx pullback:
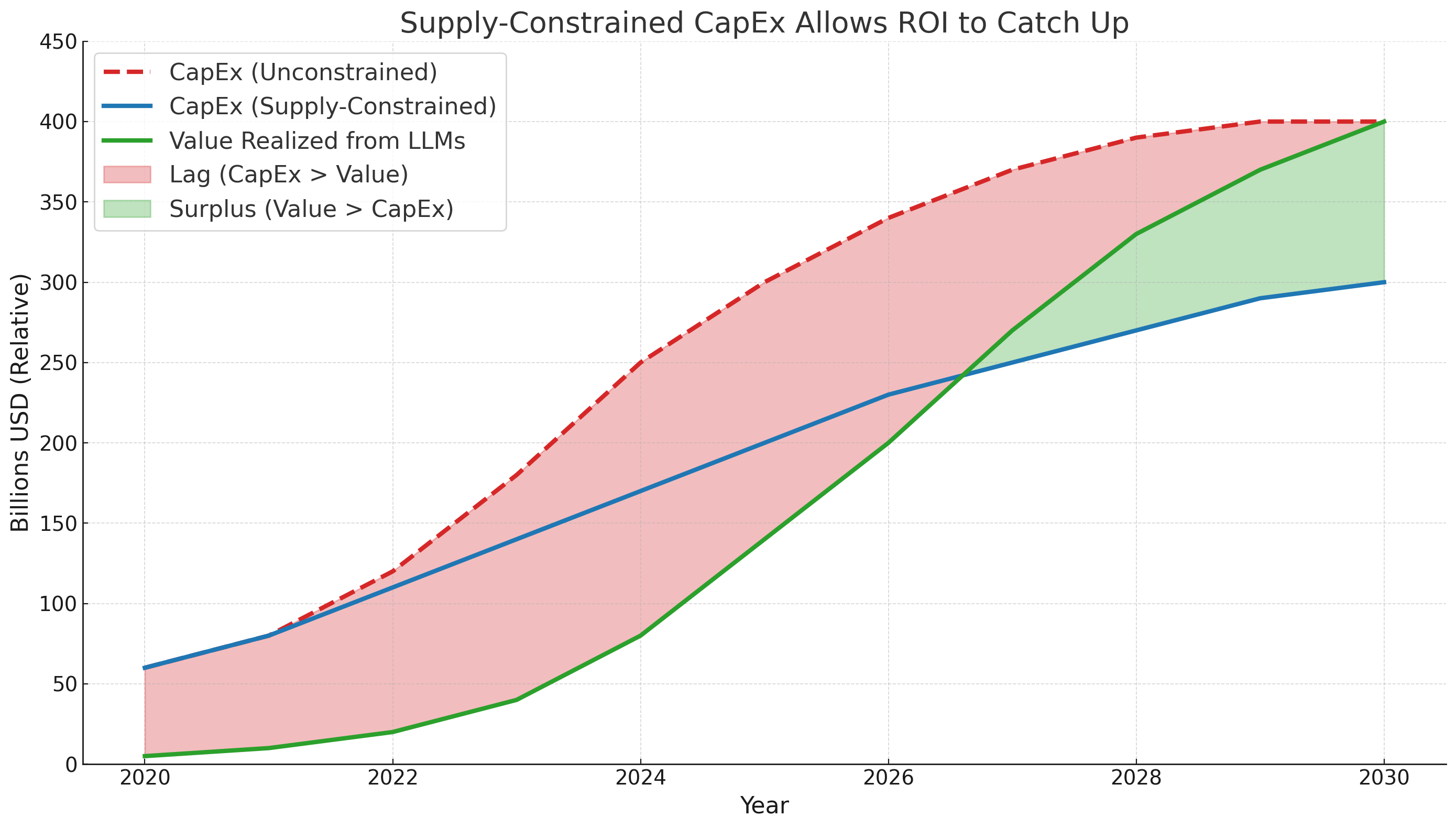
Instead of a boom-and-bust overbuild, Nvidia gets a paced rollout that preserves pricing power, smooths its revenue curve, and even reduces stock price volatility by making forward guidance more predictable.
Of course this is conceptual as we don’t yet have hard GenAI ROI data readily available. (Another post for another time!)
However, the underlying point remains: capacity bottlenecks help pace investment, allowing for the time it takes GenAI projects to be built, deployed, adopted, and monetized. That pacing may help avoid an AI bubble.
Annual Cadence Helps Too
Nvidia’s shift to an annual product cadence reinforces this dynamic.
Beginning with the Hopper-to-Blackwell transition and continuing with Blackwell Ultra and its successors, each new GPU generation promises more tokens per dollar thanks to better energy efficiency, higher FLOPS, and more HBM memory.
These improvements make new chips not just incrementally better, but also economically compelling to deploy, even for customers who have already invested in the prior generation!
The significantly increased tokens-per-dollar of each generation is how Nvidia avoids the Osborne effect.
Fundamentals Still Anchor the Valuation
The inference era is real. Demand is accelerating, and use-case traction is mounting. But at a $4 trillion market cap is there still meaningful upside?
A broader look at the fundamentals suggests the latter. Nvidia’s P/E ratio has remained relatively stable over the past two years, even as the stock surged. The reason is simple: earnings are climbing just as fast.
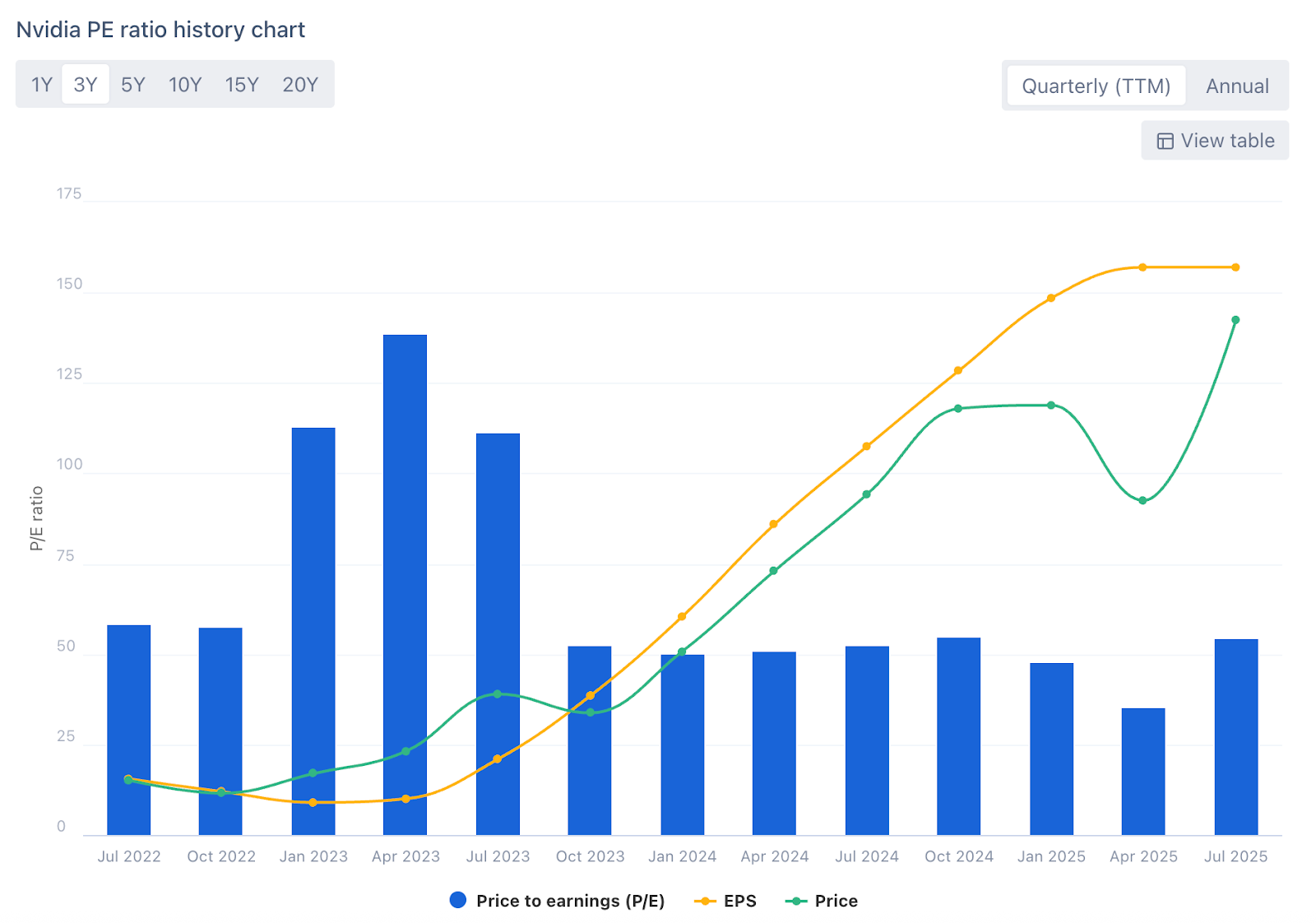
Share price is tracking demand, not speculation.
It’s a story of rising earnings powered by growing demand for AI tokens. That dynamic is what makes the $4T valuation defensible.
Of course, a steady multiple doesn’t protect against overestimated forward growth. Some argue Nvidia is priced for perfection.
But here’s why I think the future still looks compelling, and why, remarkably, the world’s largest company still has room to grow.
What’s Next
Nvidia’s next growth wave spans autonomy, robotics, and China—each a massive market in its own right. Goldman sees 90% CAGR in one segment. Morgan Stanley sees trillions in another. And China is key to Nvidia’s success, but adds risk.
At the center of it all is Nvidia’s “Three-Computer” thesis: train, simulate, deploy. And it’s already taking off.