

Enterprise AI: Nvidia, Dell, and Implications for AMD
Nvidia vision, Dell validation, AMD questions.

A year ago, if you asked me whether enterprise GenAI was real, I’d say maybe. There were surely many proofs of concept, but feasibility and value weren’t clear.
Now? It’s real.
Let’s walk you through what changed and what it means for Nvidia, Dell, and AMD.
Reasoning Enables AI Factory Era
From Training Era to Inference Era
At this time last year, we were in the training scaling era. Inference hadn’t taken off outside of the big AI labs like OpenAI. Nvidia sold a large number of GPUs, primarily for hyperscalers' massive training clusters and Tier 1 clouds.
Enterprise customers were interested in exploring AI, in the “we better understand this and see how it can help our business” kind of way. But it wasn’t clear if enterprise AI would take off.
There were lots of “internal, company-branded chat interfaces” that were simply an OpenAI or Microsoft OpenAI API wrapper, some RAG-powered customer support tools, and many concerns about hallucinations.
At the time, there were few signs that enterprise AI was a reality. Nvidia’s CFO said on the Q4 2024 earnings call (Feb 2024) that “approximately 40% of data center revenue was for AI” inference, hinting at a shift to inference. But they didn’t explain where that demand was coming from.
Was it just the hyperscalers? Meta using Gen AI internally? Microsoft running ChatGPT inference at scale? Could there be some product-market fit in consumer?
Not sure… but nothing screamed “enterprise AI inference is driving this shift!” Not yet anyway.
After all, reasoning models hadn’t arrived yet, and without them, the path to agents was unclear. Enterprises need robust automation that can reason and follow instructions in plain English, but that simply didn’t exist.
Just as important: Nvidia’s partners weren’t signaling that enterprise AI was gaining real traction.
Reasoning Models Unlock Enterprise AI
Fast forward a year, and the picture has changed.
The key unlock for enterprise AI? Reasoning models.
To automate workflows and operationalize GenAI, the AI must perform reliably in messy, dynamic environments. Standard one-shot LLMs often fall short, struggling with ambiguity, incomplete data, and multi-step tasks. They’re also opaque and difficult to debug when things go wrong. But reasoning models fill that gap. They adapt, revise plans, infer meaning from incomplete inputs, and expose their logic. That makes them more resilient, auditable, and ultimately more trustworthy. Sounds like the qualities enterprises need to deploy AI
Equally important, we have a variety of open and proprietary reasoning models, from DeepSeek’s R-series to Anthropic’s Claude 4, Google’s Gemini 2.5 Flash to Nvidia’s Llama Nemotron, and of course OpenAI’s o-series. This variety matters.
Open reasoning models enable companies to run AI within their own data centers. Bring the AI to the data. Open models offer more control and may be cheaper too. (However, there are compelling arguments that companies underestimate the operational costs and trade-offs associated with open models.)
Meanwhile, closed reasoning models are often easier to use out of the box, require less maintenance, and are often more performant.
The mix of open and closed options allows enterprises to choose what works best for their needs.
Note that reasoning models are more computationally demanding than one-shot LLMs—they often generate an order of magnitude more tokens. Enterprise use cases also tend to involve longer context windows, such as several attached PDFs, which further increase cost. And because reasoning agents can revise plans and recover from failure, they’re often used in multi-turn interactions where each exchange builds on prior context, driving up both memory and computation requirements.
Enterprises face a catch-22: reasoning models unlock real enterprise AI, but they’re costly to run, and enterprises are deeply cost-sensitive.
Nvidia Dynamo
That’s where Nvidia Dynamo comes in.
At GTC in March, Nvidia announced Dynamo, a datacenter-scale inference platform built to make serving large, multi-turn reasoning models more efficient. It does this by intelligently splitting transformer workloads into prefill and decode phases, optimizing how and where each runs to lower serving costs.
A Quick Nvidia Dynamo Primer
You can skip past this if you already understand Dynamo.
Transformer models operate in two stages, prefill and decode.
Prefill is the initial setup stage, where the model analyzes the entire input prompt to create a key-value (KV) cache of intermediate activations. This stage is highly compute-intensive, as the model has to attend to each token in the input, which in enterprise scenarios can encompass thousands of tokens across multiple documents.
Decode is the generation phase. The model produces output tokens one at a time Decode refers to the generation phase where the model outputs tokens one-by-one in an "autoregressive" manner, focusing solely on the latest token while utilizing the cached keys and values from the prefill. This approach reduces computational intensity but is limited by memory bandwidth and latency. To ensure responsiveness, particularly in reasoning applications, each token needs to be generated quickly.
In tasks with long prompts and short answers, like retrieval-augmented summarization, prefill often becomes the bottleneck. But for agentic reasoning, where the model generates long outputs step-by-step, decoding tends to dominate runtime.
Running LLMs on multi-GPU setups underutilizes compute by ignoring prefill and decode's distinct needs. Prefill is compute-intensive but brief, while decode is long-running and memory-bound. Without intelligent scheduling, prefill stalls due to insufficient compute, and decode idles GPUs waiting for data from memory. This imbalance worsens at scale; adding GPUs amplifies inefficiency rather than resolving it. Without software to intelligently split and route prefill and decode across different GPUs, utilization will remain low and companies will struggle to meet latency targets for real-time, multi-turn reasoning tasks. One common workaround is simply overprovisioning hardware to mask the inefficiency.
Dynamo introduces disaggregated serving by splitting the prefill and decode phases across different GPUs, each optimized for the workload it handles. Dynamo monitors the system in real-time and reallocates compute resources to whichever phase becomes a bottleneck. Think of it as an intelligent load-balancer for transformer workloads on large GPU fleets.
With Dynamo, enterprise-grade reasoning becomes economically and operationally viable. Without Dynamo, overprovisioning has a negative impact on tokenomics. Alternatively, engineering teams can attempt to handle this load balancing themselves, but it’s challenging, error-prone, and expensive.
(By the way, Dynamo demonstrates the power of Nvidia’s systems thinking.)
The Big Picture
So in summary thus far,
Reasoning models unlock enterprise AI
These models are token-intensive and compute-hungry
Efficient scheduling across prefill and decode is required to optimize cost
Nvidia Dynamo does that
Yet enterprises need help not just serving the intelligence, but putting it to good use too.
Enterprise Agent Tooling
Accordingly, we’re seeing the necessary software scaffolding to create powerful enterprise workflow automation agents.
At Build 2025, Microsoft unveiled its software stack for operationalizing agentic AI in the enterprise. That’s good news for enterprise AI and for Nvidia. As Nvidia builds the compute infrastructure, Microsoft is creating connective tissue that ties it into real workflows.
The Model Context Protocol (MCP) formalizes how agents call tools. Windows 11 adds enterprise-grade controls: sandboxing, permissions, audit logs. Copilot Studio lowers the barrier to entry, letting teams assemble agents with minimal code. Windows AI Foundry handles local model execution. Microsoft even demoed agents that scream enterprise, for example see the RFP response agent and the contract builder demos here (~4:00)
Enterprises and AI Factories
For the foreseeable future, AI won’t be the product for most companies. But AI will become essential to how they deliver their products and operate internally. AI becomes part of enterprise operations.
As the demand for AI factories grows, it’s worth pointing out that AI is becoming infrastructure, not just capability. If that’s hard to grasp, ponder the question of whether software is infrastructure for the world’s leading companies like Wal-mart, Visa, Home Depot, McDonald’s, Netflix, Tesla, and so on.
AI is Eating the World
Take this quote from Marc Andreesen’s 2011 Why Software Is Eating the World:
More and more major businesses and industries are being run on software and delivered as online services—from movies to agriculture to national defense.
Now replace software with AI.
More and more major businesses and industries are being run on AI—from movies to agriculture to national defense.
Yep, that’s long been true. And replace AI with “Gen AI” (e.g. Vision Transformers), and it increasingly describes reality too.
AI is infrastructure. And, like software, AI will comprise part of the product for an increasing amount of industries.
AI Factories
If enterprise adoption of agentic AI accelerates, token generation will explode. And unlike AI labs or hyperscalers, most enterprises can’t ignore cost. They won’t tolerate inefficiencies at scale. For enterprises, every generated token must be justified by utility and margin.
That’s why token economics matters. If tokens are how AI does work, then the cost, speed, and energy to produce those tokens becomes core to infrastructure planning.
This is what Jensen means when he talks about an AI Factory. It’s an AI datacenter designed to generate tokens quickly, cost-effectively, and reliably.
These systems define a new efficiency frontier: how many tokens you can produce per second, per watt, per dollar—and how fast that intelligence can be served to the user.
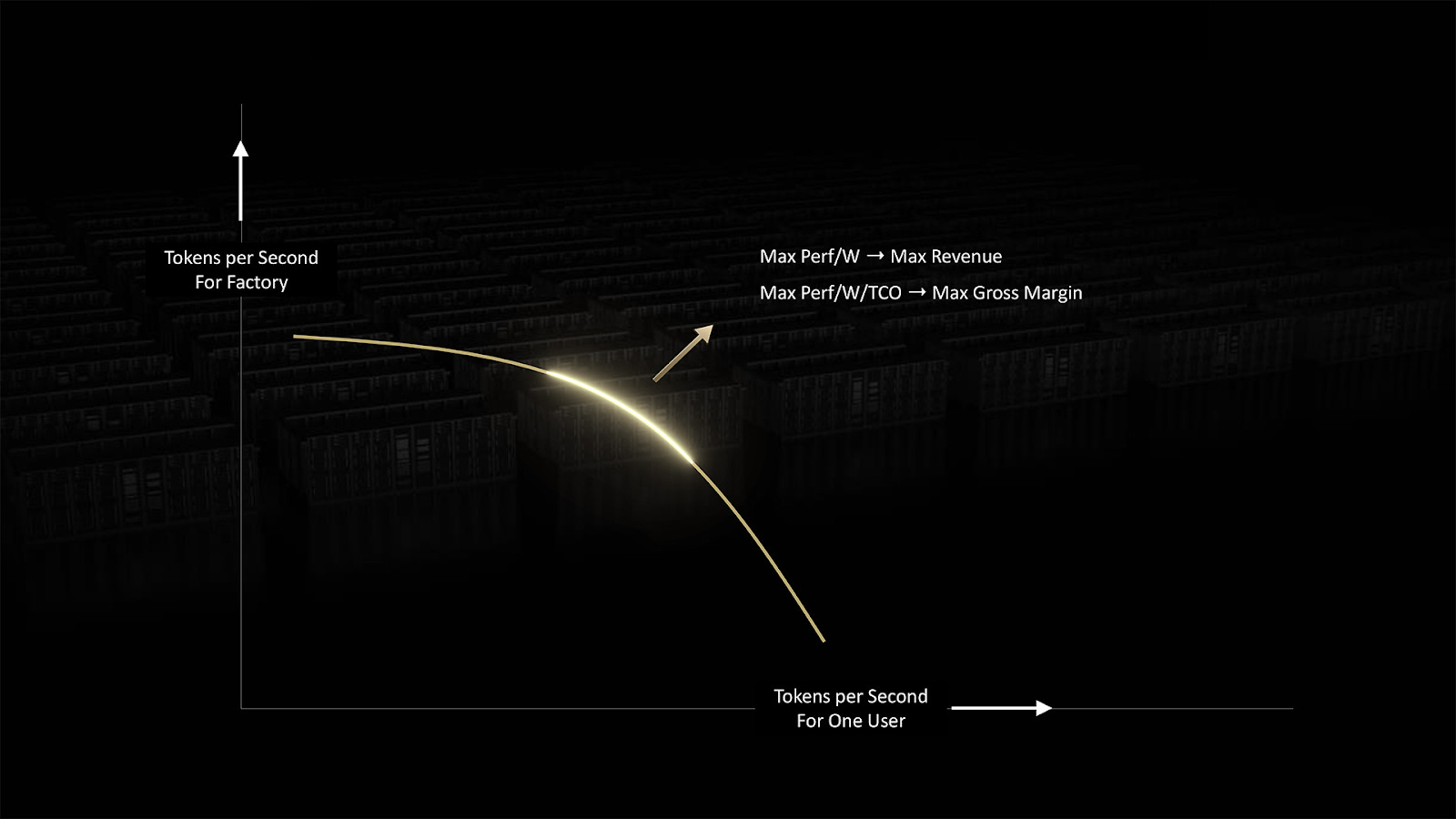
This AI Factory efficiency frontier emphasizes the importance of system-level innovations: AI compute, networking, software, and now factory-level orchestration tools like Dynamo that stretch that curve outward.
But Is It Real?
Skepticism is healthy.
So let’s ask: is this enterprise AI vision grounded in reality? That is — do enterprises care?
Are they actually thinking about adopting AI at a scale that justifies all this infrastructure, orchestration, and optimization?
Well, a recent WSJ article, How Morgan Stanley Tackled One of Coding’s Toughest Problems has a data point:
Pizzi said you’re not going to see fewer heads in software engineering, just more code—including more AI apps—that will help Morgan Stanley deliver on its business goals. Currently, the company has hundreds of AI use-cases in production aimed at growing the business, automating workflows and doing it more efficiently.
But none of that is possible without a modern, standardized, well-thought out architecture, Pizzi said.
“You’re always modernizing in tech,” he said. “Today, with AI this becomes even more important.”
Hundreds of use-cases… in production… automating workflows… very promising!
But let’s look at Nvidia and Dell’s earnings for more evidence.
Nvidia Earnings
Enterprise Signals
Nvidia’s earnings show that revenue is no longer coming just from hyperscalers. Enterprises are now building AI factories too.
The pace and scale of AI factory deployments are accelerating with nearly 100 NVIDIA-powered AI factories in flight this quarter, a two-fold increase year-over-year, with the average number of GPUs powering each factory also doubling in the same period. And more AI factory projects are starting across industries and geographies. NVIDIA's full stack architecture is underpinning AI factory deployments as industry leaders like AT&T, BYD, Capital One, Foxconn, MediaTek, and Telenor, are strategically vital sovereign clouds like those recently announced in Saudi Arabia, Taiwan and the UAE.
These AI factories imply the shift from training to inference is real; after all, AT&T and Capital One aren’t spinning up training clusters.
Inference is rising across the board, even among customers who do not buy hardware but purchase tokens instead.
We are witnessing a sharp jump in inference demand. OpenAI, Microsoft and Google are seeing a step function leap in token generation. Microsoft processed over 100 trillion tokens in Q1, a five-fold increase on a year-over-year basis. This exponential growth in Azure OpenAI is representative of strong demand for Azure AI Foundry as well as other AI services across Microsoft's platform.
Whether for consumer use cases or enterprise deployments, reasoning models are driving real value and a sharp increase in token generation.
My favorite nugget from the call:
We also announced a partnership with Yum! Brands, the world's largest restaurant company, to bring NVIDIA AI to 500 of its restaurants this year and expanding to 61,000 restaurants over time to streamline order-taking, optimize operations and enhance service across its restaurants.
Yum! Brands includes Taco Bell, KFC, and Pizza Hut. Franchise chains like Yum! may not fit the classic enterprise mold, but they behave like enterprises with centralized infrastructure, standardized workflows, and large deployments. And fast food operates on low margins and high volume, so new technology must work and promise a return on investment.
Yum! is a compelling indicator of GenAI’s enterprise viability.
RTX Pro 6000
Another important takeaway: enterprise AI isn’t one-size-fits-all.
Not every company needs a liquid-cooled Blackwell cluster. Enterprises vary widely in their workloads, constraints, and deployment environments. Nvidia recognizes this and is expanding its portfolio to match.
Jensen Huang: We're going to see AI go into enterprise, which is on-prem, because so much of the data is still on-prem. Access control is really important. It's really hard to move all of every company's data into the cloud. And so, we're going to move AI into the enterprise.
Bring the AI to the data. But can enterprises manage liquid-cooled Blackwell racks?
JH: And you saw that we announced a couple of really exciting new products, our RTX Pro Enterprise AI server that runs everything enterprise and AI, our DGX Spark and DGX Station, which is designed for developers who want to work on-prem. And so, enterprise AI is just taking off.
RTX Pro is a high-end workstation GPU, traditionally used for high-performance compute workflows like design, real-time rendering, and AI.

Nvidia used this to build a server, the NVIDIA RTX PRO 6000 Blackwell Server Edition.

This slots into enterprise and edge server deployments where form factor constraints, reasonable power envelope (600W), and passive thermal support are needed, but where HBM-class AI throughput isn’t required.

This image shows eight NVIDIA RTX Pro 6000 Blackwell Server Edition GPUs installed in a rack-mounted chassis. Each is passively cooled and designed for airflow-optimized server deployments. This isn’t a hyperscaler build; it’s infrastructure tailored for the enterprise edge.
That makes it a strong fit for on-prem enterprise data centers, especially in industries like finance, healthcare, manufacturing, and government. These organizations may not need the highest token throughput or the lowest cost per token, because their workloads won’t run at hyperscaler volume or intensity. For them, RTX Pro cards deployed in standard rack-mount form factors via Nvidia’s partners offer the right balance of performance, efficiency, and integration.

RTX Pro servers also make sense in environments with broader workloads beyond AI, such as graphics, simulations, and digital twins. These use cases require precision and flexibility, especially in settings where infrastructure is still evolving or designed for multi-purpose use.
Of course, enterprises focused solely on high-scale AI inference can still choose liquid or air-cooled Blackwell systems built for maximum throughput. But RTX Pro expands the AI Factory portfolio to meet real-world constraints like budget, form factor, and mixed-use infrastructure.

An important take-home is this: the AI Factory is a portfolio, with offerings scaled and shaped to fit the needs of real-world enterprises.
Nvidia’s enterprise AI narrative is compelling. Are these cherry-picked examples though, or is a broad trend happening? To understand that, we have to move past supplier messaging and examine buyer behavior.
Dell’s Earnings
Dell is a key partner in Nvidia’s AI Factory strategy, delivering full-stack infrastructure beyond just servers. Its PowerEdge platforms support the full Nvidia GPU range, from liquid-cooled Blackwell to air-cooled RTX Pro 6000. Dell also provides professional services to help enterprises plan, deploy, and run AI systems efficiently, with validated architectures, thermal and power engineering, and on-site support for those without deep in-house expertise.
If Dell’s says customers are standing up AI factories, it’s a good sign that Nvidia’s hype is real.
AI Factories Are Real and Scaling
Well, Dell booked $12.1B in AI-optimized server orders in Q1, more than all of FY2025:
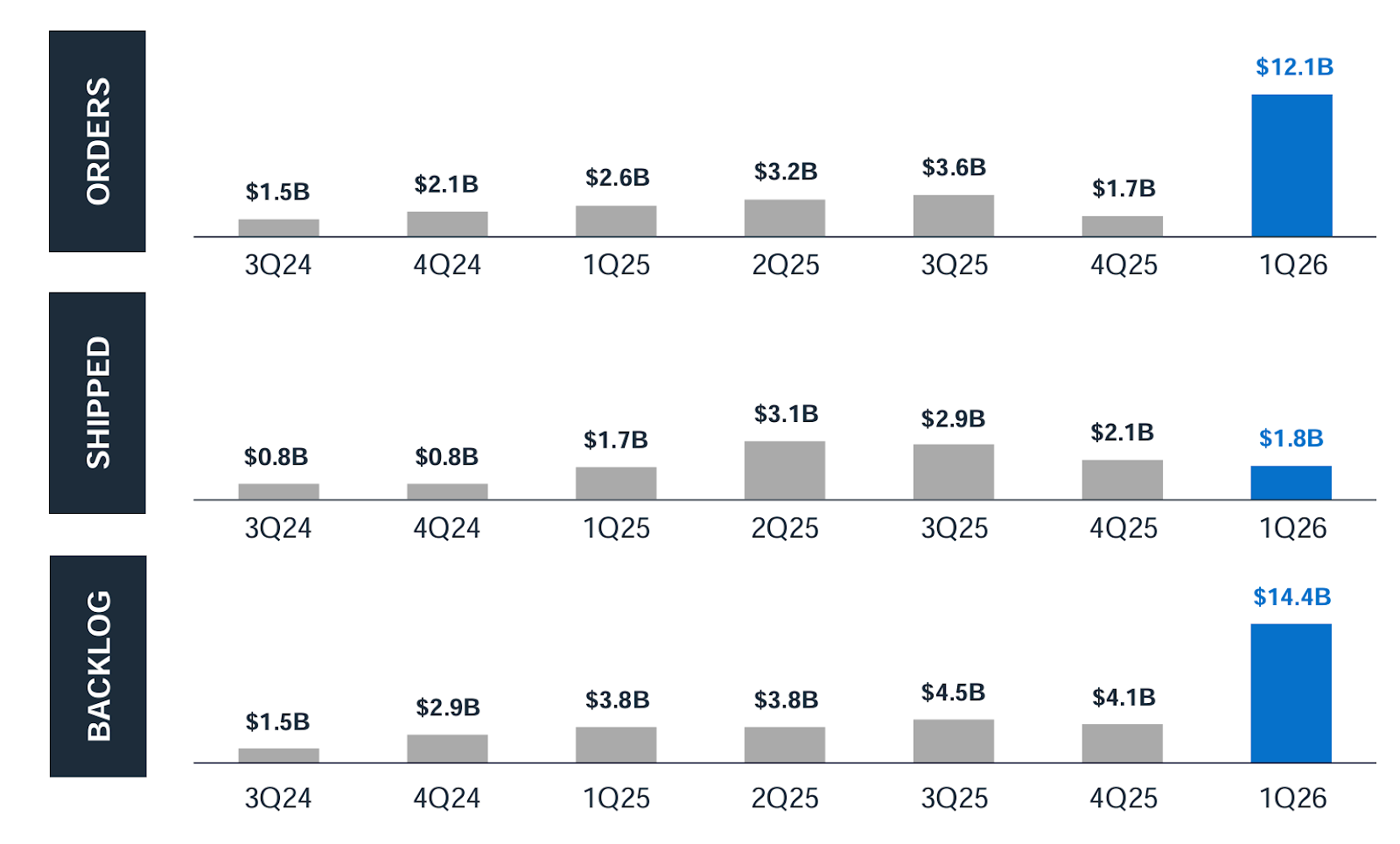
📈. Whew. That had to feel good to print. Of course they need to deliver on those orders, but it’s still a strong demand signal.
And it’s not just coming from training clusters like xAI, but includes enterprise AI too. From Dell’s COO Jeff Clarke on the earnings call:
Jeff Clarke: We experienced exceptionally strong demand for AI-optimized servers, building on the momentum discussed in February and further demonstrating that our differentiation is winning in the marketplace. We built $12.1 billion in orders in the first quarter, surpassing the entirety of shipments in all of FY 2025. We shipped $1.8 billion, leaving us with a backlog of $14.4 billion. Our five-quarter pipeline continued to grow sequentially across both Tier 2 CSPs and private and public enterprise customers and remains multiples of that backlog.
Enterprise AI customers grew again sequentially with good representation across key industry verticals, including Web Tech, Financial Services Industry, Manufacturing, Media & Entertainment and Education. AI momentum continues to remain strong.
Dell reinforces Nvidia’s claim that enterprise AI factories are real and accelerating.
Enterprise AI customer base is growing, with over 3,000 customers now buying Dell AI infrastructure across web tech, financials, manufacturing, education, and M&E.
That many customers across a broad spectrum of industries is a strong signal.
Jeff Clarke: I made a reference that the five-quarter pipeline continues to grow and grow significantly. It remains multiples of our backlog. The enterprise component of that continues to grow. In fact, it's growing at a faster rate than the CSP part of that pipeline. And we're optimistic.
Enterprise is growing faster than cloud service providers. Sure, maybe it was a small number to start with, but still!
One more telling quote in the Q&A:
Jeff Clarke: In terms of orders, clearly, while we're talking about specific customers, we saw CSP customers, we saw enterprise customers, the number of enterprise customers grew, the number of repeat enterprise customers grew as well. Our enterprise growth is exciting with over 3,000 customers now buying various forms of our Dell AI factories. We saw a mix from Hopper technology and Blackwell technology across those.
This answer checks all the boxes needed to validate Nvidia’s strategy.
Enterprise buyers? ✅
Repeat enterprise buyers? ✅
Buying AI factories? ✅
Buying a variety of AI factories? ✅
Dell is seeing demand across a range of AI factory configurations, suggesting enterprises are choosing solutions that fit their specific constraints rather than defaulting to the largest or highest-throughput options.
Dell AI Factory
Dell appropriately calls their offering the “Dell AI Factory”.
It’s no longer an Nvidia term, but an industry term.
Here’s a snippet from an e-book (clearly they know how to sell to enterprises) about the “Dell AI Factory with Nvidia”:
Note Dell’s value prop. If you buy into Jensen’s vision, you can trust Dell to help you turn dreams into reality.
Dell also mentioned partnerships with Cohere and Google to bring AI on-prem, and validated enterprise demand for both closed and open models.
Jeff Clarke: We expanded our ecosystem of partners and announced our collaboration with Google to bring Gemini on-prem exclusively for Dell customers, an industry first. Additionally, we announced our partnership with the innovative Cohere to simplify the deployment of Agentic technology on-prem.
Enterprise reasoning AI is coming on premises to an enterprise near you.
Takeaway: Dell as Ground Truth
Nvidia can sell the vision, but it is partners like Dell that help make it real for enterprise buyers. That means Dell is a good ground truth for enterprise AI reality.
And Dell’s earnings call confirmed what’s actually happening on the ground. Enterprises are deploying real infrastructure, across a range of SKUs and cooling configurations, matched to their own constraints.
Dell’s adoption signals that Nvidia’s AI Factory is moving from concept to cornerstone in enterprise AI strategy.
AMD
Enterprise AI is taking off, and it could shake up the competitive landscape for AMD’s Instinct accelerators. There are signs this shift plays to AMD’s advantage, but the path forward isn’t so simple. I’m left with many questions.
Let’s dig in.