

AMD's Strategic Bets
FP6 Advantage, Rack Density, HBM, AI NIC, TCO, Openness, UALink, more. Customer Momentum.

I attended AMD’s Advancing AI event last week, and the confidence from Lisa Su and her team was palpable, especially in the smaller analyst briefings.
AMD is executing a focused, differentiated strategy: open systems, massive on-package memory, low-precision compute, and full-rack deployments designed for cost, density, and time-to-value. And with ROCm now significantly improved, the software no longer feels like a limiting factor.
The question is whether AMD can capitalize on this momentum to establish repeat business with customers whose needs aren’t fully met by Nvidia’s premium, closed offerings.
We’ll also cover where AMD still has work to do.
Let’s dig in.
AI Accelerator *For Everyone*
First, AMD unveiled the MI350 series, its next-generation Instinct accelerator. And right away, it signaled a broader focus than just hyperscalers and AI labs, offering two variants: the air-cooled MI350 and the liquid-cooled MI355.

Both chips use the same silicon, but the MI355 is tuned for higher power and clock speeds, enabling denser, higher-performance rack deployments.
Notably, AMD is positioning air- and liquid-cooled options side by side, rather than spotlighting only the premium configuration. It’s a subtle yet telling signal that AMD is targeting a broader range of customers than its competitors.
Air-Cooled, Rack Density Leadership
AMD’s 350 series emphasizes deployment flexibility, offering customers options that align with their budget, infrastructure, and performance needs.
Consider the MI350X rack:

The MI350 rack features air cooling and Universal Baseboard 2.0 (UBB 2.0), the open hardware standard that supports modular, non-proprietary server integration. That translates to quicker deployments and better economics for customers who prefer standardized systems over expensive custom builds. It’s for those who can’t afford to rebuild their datacenter with every refresh! The more you change, the more you spend.
The MI350X rack does not operate as a single, unified GPU like Nvidia’s NVL72, which links 72 GPUs into one massive NVLink domain. Thus, it’s not technically “rack-scale” in that sense; yet for some customers, that’s a feature, not a bug. There are plenty of workloads today that don’t require full-rack GPU coherence.
So AMD is signaling that it’s ready to serve this segment with standards-based, air-cooled, high-density systems that are easier to deploy, more power-efficient, readily available, and most importantly, lower in upfront cost.
Wait, doesn’t Nvidia have air-cooled offerings too? Yes. Many might not know it, given the focus on liquid cooling from the stage, but air-cooled Blackwell systems are available. See Supermicro’s 10U B200 cluster:

If you look closely at AMD’s slides, you’ll notice a practical advantage that’s easy to miss but has significant implications for these customers: rack efficiency. Specifically, AMD highlights how their MI350X AC systems pack more GPUs into less space by fitting 8 GPUs into a 6U air-cooled chassis, compared to Nvidia’s typical 10U configuration for the same 8-GPU setup. (See the “nodes” diagrams).

This may seem subtle, but it adds up fast. A 6U vs. 10U chassis means AMD can fit eight 8-GPU servers per rack, while Nvidia’s 10U design fits just four. That’s 64 GPUs per rack for AMD, versus 32 for Nvidia. Double the density using standard rack heights. Have a look:

Higher density, standard hardware, and better economics. Rack efficiency might not be flashy, but it’s a major factor in total cost of ownership for air-cooled customers and AMD is leaning into it.
The MI355X pushes density even further with direct liquid cooling, supporting up to 128 GPUs in a single rack.

If you’re a customer that does want full rack-scale compute, AMD has coherent scale-up coming in the next generation MI450. (More on that later in this article).
AMD is betting that some customers want capable, efficient AI systems they can deploy now without breaking the budget. The MI350 series appears to be just that.
AMD Doubles Down on Big HBM
With the MI300X, AMD made an architectural bet that memory, not compute, would be the bottleneck for certain frontier LLM workloads.
That bet paid off.
The MI300X shipped with 192GB of HBM3, allowing customers like Meta to run large models such as Llama 3.1–405B on 8 AMD GPUs, something that 8 Nvidia H100s couldn’t handle. The TCO decision is obvious when you can do the job with 8 AMD GPUs instead of 16 from Nvidia:
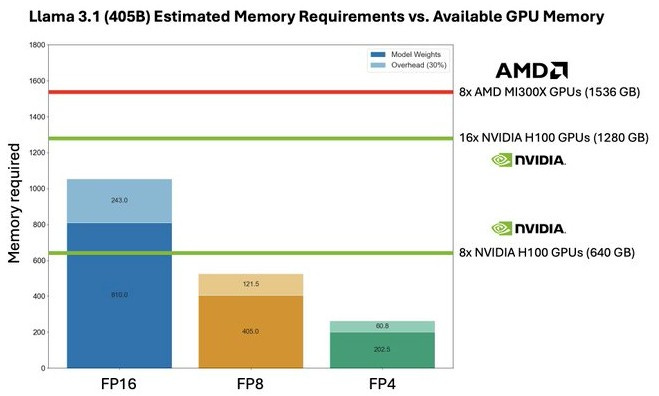
This was an important bet that helped AMD get in the door with high-value customers like Meta.
These workloads, especially those constrained by model size and context length rather than sheer throughput, began to favor AMD’s memory-first approach. Cohere CEO and “Attention Is All You Need” coauthor Aidan Gomez summed it up well at the keynote:
AMD’s Vamsi Boppana: Tell us a little bit about how you’re taking advantage of the memory system in Instinct, particularly as you serve large and more complex models like those used in reasoning.
Aiden Gomez: For agentic systems and complex reasoning workloads, the memory system becomes critical because these models rely heavily on large context windows. That puts a lot of pressure on memory capacity and bandwidth during inference. These models spend a significant amount of time ingesting and reasoning over external data—essentially “thinking” before producing a response.
Each of those steps increases the computational and memory demands on the hardware. AMD’s Instinct GPUs, with their high memory capacity and strong bandwidth, let us fit longer context windows directly onto the GPU. Most importantly, this reduces the overall infrastructure footprint required to serve these models, which in turn helps lower the total cost of ownership for our customers.
The bet paid off, and AMD is doubling down with the MI350 series. It extends AMD’s lead in memory per GPU while holding steady on inference performance against Nvidia’s current-gen B200:

Yet this is a temporal advantage; Blackwell Ultra (B300) will also have 288GB memory too. Of course, the subsequent generation Instinct (450) has even more HBM. This will be a long-term bet and leadership tango.
Relatedly, if you’re tracking memory (and you should, given its central role in LLM performance) Micron has announced it’s supplying HBM for AMD’s MI350. Micron is gaining momentum this year, having also landed HBM and SOCAMM design wins for Nvidia’s B300 systems.
The FP6 Bet
AI compute has been on a consistent trajectory toward lower precision, and for good reason. Lower-precision formats reduce memory use and power consumption while increasing throughput. This shift began with FP32 and BF16 for training and then transitioned to FP8 for inference. How low can you go?

The MI350 series delivers native acceleration for FP6 and FP4, two new formats defined under the OCP Microscaling Formats Specification (OCP MX), an industry standard. That matters. Previous formats like FP8 splintered into multiple incompatible variants, making software portability and model reproducibility harder. With OCP MX, AMD is aligning with an open standard.
As part of this shift, AMD is making a strategic bet on FP6 in particular.
But why FP6? Why not just push further to FP4?
Microsoft Research’s FP6-LLM paper highlights FP6 as a sweet spot, offering memory and compute savings over FP8 while preserving significantly more model quality than FP4.
Better model quality than 4-bit quantization. Although 4-bit quantization more aggressively reduces memory footprint and DRAM access, it unavoidably causes degradation in model quality. In contrast, near-lossless model compression can be achieved with 6-bit quantization.
Still, if FP6 isn’t a power of two, doesn’t that complicate hardware? Why not just emulate it using FP8?
Nvidia does precisely that. In Blackwell, FP6 is run on FP8-optimized matrix cores, meaning there’s no compute speedup, but only memory savings.
But AMD took a different path. With CDNA 4, it re-architected the matrix engine to natively accelerate FP6 at twice the throughput of FP8, matching FP4 speed.
From Chips & Cheese’s fantastic interview with MI350’s Chief Architect Alan Smith:
George: And speaking of Tensor Cores, you've now introduced microscaling formats to MI350x for FP8, FP6, and FP4 data types. Interestingly enough, a major differentiator for MI350 is that FP6 is the same rate as FP4. Can you talk a little bit about how that was accomplished and why that is?
Alan: Sure, yep, so one of the things that we felt like on MI350 in this timeframe, that it's going into the market and the current state of AI... we felt like that FP6 is a format that has potential to not only be used for inferencing, but potentially for training. And so we wanted to make sure that the capabilities for FP6 were class-leading relative to... what others maybe would have been implementing, or have implemented. And so, as you know, it's a long lead time to design hardware, so we were thinking about this years ago and wanted to make sure that MI350 had leadership in FP6 performance. So we made a decision to implement the FP6 data path at the same throughput as the FP4 data path. Of course, we had to take on a little bit more hardware in order to do that. FP6 has a few more bits, obviously, that's why it's called FP6. But we were able to do that within the area of constraints that we had in the matrix engine, and do that in a very power- and area-efficient way.
AMD is making a clear strategic bet on where the market is headed: if FP6 emerges as the standard for GenAI inference, AMD stands to gain a meaningful advantage.
Don’t get hung up on precision; this is about throughput, efficiency, and cost. More efficient compute + more on-package memory = more tokens per watt and more tokens per dollar.
Side note: If AMD continues to thread the needle like this, balancing hardware design, customer needs, and strategic bets like FP6 and HBM, its next few product cycles should be exciting.
And these bets are already resonating with customers. In the keynote, Meta’s VP of Engineering Yee Jiun Song underscored many of the same points:
Yee Jiun Song: We're also quite excited about the capabilities of MI350X. We like that it brings significantly more compute power, next-generation memory, and support for FP4, FP6, all while maintaining the same form factor as MI300, so we can deploy quickly.
Merchant AI Accelerator
AMD is subtly reframing Instinct as a merchant AI accelerator—not just a general-purpose GPU—by tuning its architecture specifically for transformer-based LLM workloads while preserving flexibility for future model evolution.
A telling moment came during Lisa Su’s onstage conversation with Sam Altman:
Lisa Su: One of the things that really sticks in my mind is when we sat down with your engineers, you were like, "Whatever you do, just give us lots and lots of flexibility because things change so much."
This MI350 architecture slide explicity articulates how this “GPU” is fine-tuned for LLM workloads:

For example, AMD doubled the transcendental rate to speed up the math behind attention mechanisms. It also expanded the Local Data Store (LDS) from 64KB to 160KB per compute unit and doubled its bandwidth, keeping activations and partial sums closer to the compute units. That reduces reliance on slower HBM during both inference and training.
And factor in that native support for FP6 we discussed, plus massive HBM, and it’s obvious: the MI350 series shouldn’t be thought of as a general-purpose GPU with some AI features, but rather a purpose-built AI accelerator.
And notably, this chip leans further away from traditional HPC.
BTW, what about MI300A?
Note that the previous Instinct generation included both the MI300X and the MI300A. The MI300A traded some accelerator dies for CPU dies:
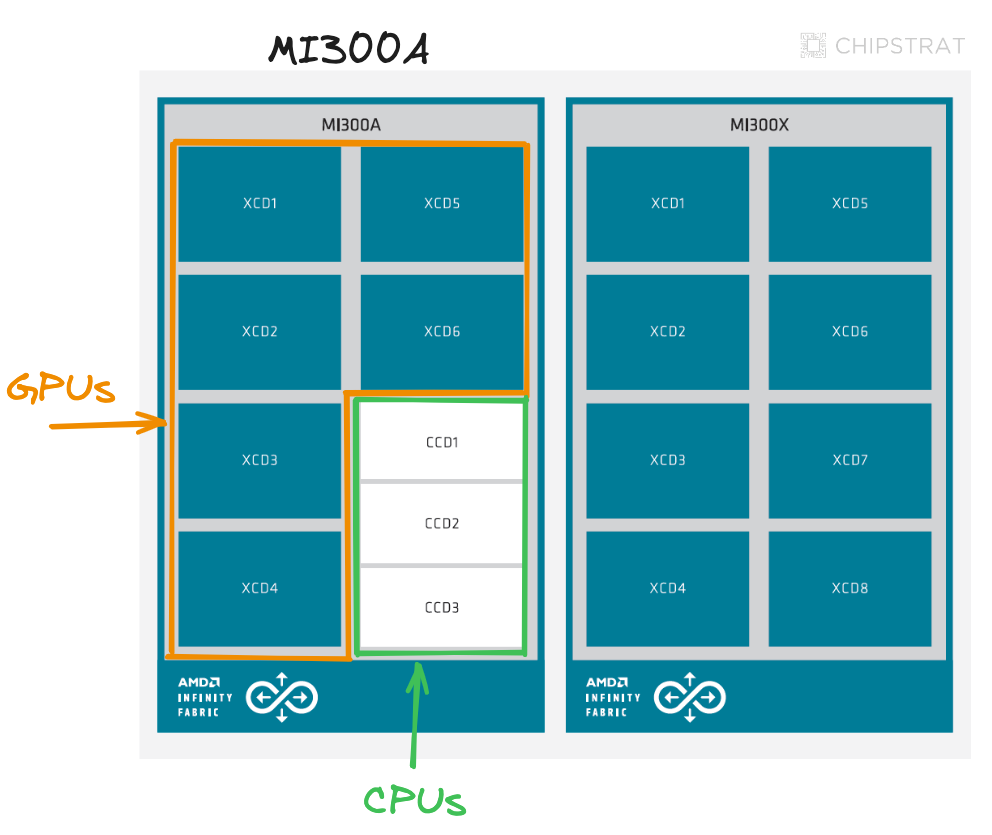
MI300A is an “APU” (Accelerated Processing Unit) combining Zen 4 CPUs and CDNA 3 GPUs on a unified package with shared HBM. This creates a coherent memory architecture for workloads needing tight CPU-GPU coupling.

The MI300A was primarily used in supercomputers, most notably El Capitan at Lawrence Livermore National Laboratory, the top system on the TOP500 list.
But there was no mention of a successor last week. AMD is focused on AI this generation, not HPC. With MI350, AMD is betting its transistors on low-precision compute, where demand and growth are strongest. While MI350 still supports high-precision workloads, it doesn’t improve on MI300’s performance in that area:

That’s a deliberate tradeoff. But it doesn’t mean AMD has abandoned CPU-GPU coherence. HPC buyers don’t need annual upgrades, so a future APU could still come.
For now, AMD is positioning Instinct as a flexible, standards-based AI accelerator tuned for LLMs. It’s a viable alternative not just to Nvidia’s closed stack but also to hyperscaler ASICs like Trainium and MTIA.
Single Vendor Rack If You Want, Open Standards If You Don’t
AMD is embracing openness, but not at the cost of simplicity. With the rise of AI infrastructure complexity, many buyers want the speed and ease of deploying a full-stack solution from a single vendor. AMD delivers exactly that, with racks outfitted entirely with AMD silicon and optimized to work together out of the box:

But if you prefer choice, AMD enables it. Through its “Ultra Open Ecosystem,” AMD champions open standards such as Ultra Ethernet (UEC) and Ultra Accelerator Link (UALink), providing customers with the freedom to mix and match components from different vendors.
That openness contrasts with Nvidia’s vertically integrated approach. While Nvidia gestures toward flexibility with offerings like SpectrumX and NVLink Fusion, its ecosystem remains tightly controlled. You can bring your own CPU, but only if you use Nvidia’s GPU and networking. Or bring your own accelerator, but must use Nvidia’s CPU and networking.
AMD is betting that hyperscalers, neoclouds, and enterprises will increasingly value true modularity. Meta’s Yee Jiun Song highlighted this in AMD’s keynote:
Yee Jiun Song: Operating at scale requires that the accelerators we use be compatible with our network and data center infrastructure. We rely on our common infrastructure hardware racks as the integration point between accelerators, the network, and the data centers. That’s one reason we were able to introduce MI300 into production so quickly.
AMD’s openness isn’t just philosophical, but practical. As Meta shows, in this market time-to-value matters!
AI System Optimization with Pollara
That same philosophy of modularity and optimization extends to networking.
AMD launched the Pensando Pollara 400 AI NIC, purpose-built for AI workloads.

Pollara is UEC-ready and built around open Ethernet standards, combining high bandwidth, low latency, and hardware acceleration for GPU-to-GPU communication. It’s AMD’s answer to the growing bottleneck of communication overhead in large-scale AI systems.
But it’s not just a NIC; it can be used as an offload co-processor for AI system orchestration. Remember how DeepSeek’s V3 paper discussed how they had to waste GPU cycles managing communication, with up to 20 of 132 Nvidia streaming multiprocessors tied up handling communication instead of compute. As they wrote:
“We aspire to see future vendors developing hardware that offloads these communication tasks from the valuable computation unit SM, serving as a GPU co-processor or a network co-processor like NVIDIA SHARP Graham et al. (2016).”
Pollara delivers on that aspiration:
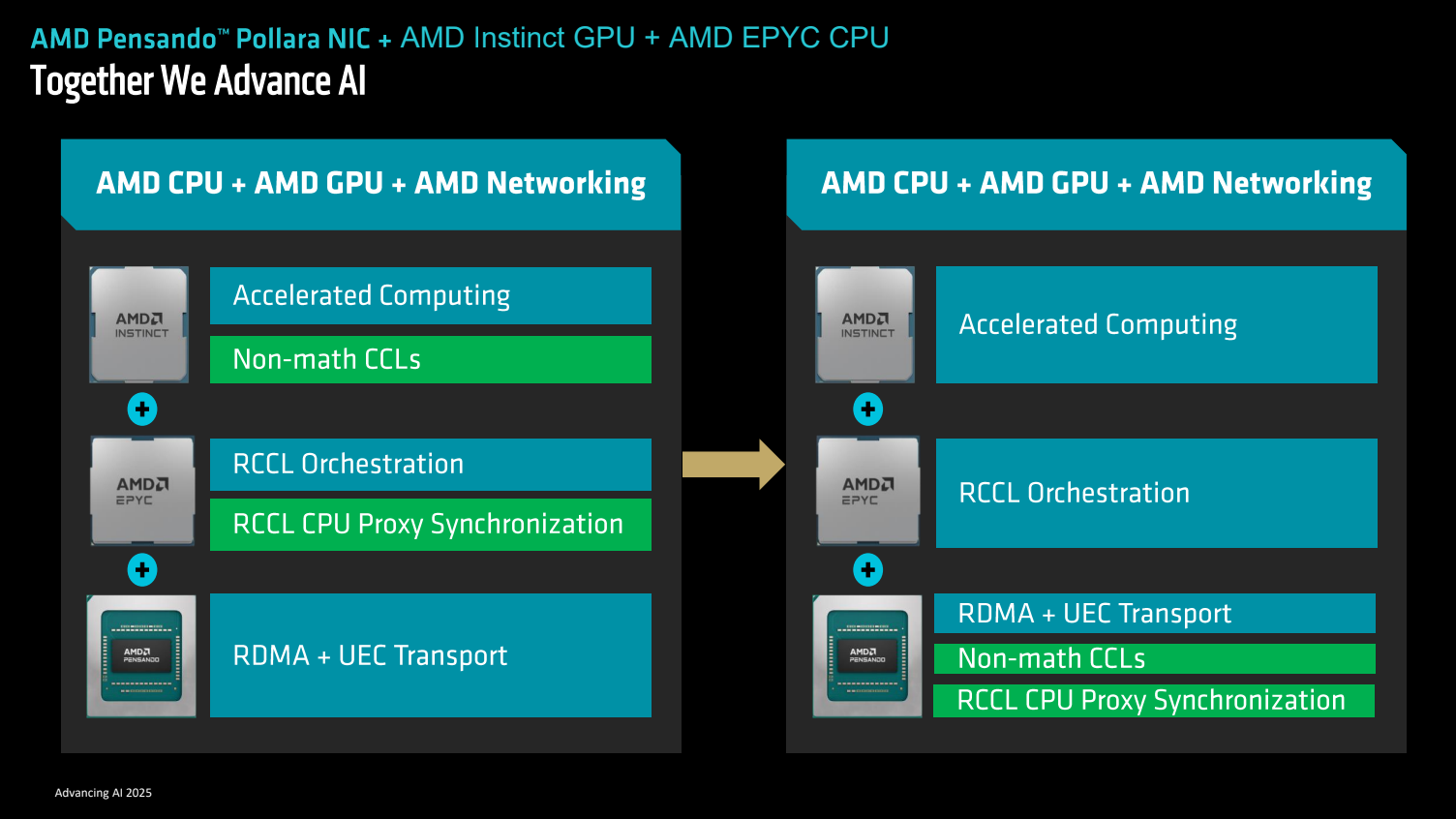
In the traditional setup (see left side of image), GPUs and CPUs handle the orchestration overhead of collective communication tasks—broadcast, reduce, gather, and scatter operations essential to parallel processing. But this coordination burns valuable compute cycles and adds latency.
Pollara changes that. AMD proposes offloading overhead directly to the NIC. That keeps the GPU focused on math, the CPU on orchestration, and delegates communication to a dedicated AI co-processor.
Crucially, it does this using open standards like Ultra Ethernet (UEC), avoiding the lock-in of proprietary fabrics.
This kind of NIC offload is exactly what DeepSeek—and surely other model builders—have been calling for. In large-scale AI clusters, it could be just as critical as FP6 or HBM in boosting performance and reducing cost.
Open Software Ecosystem Is Gaining Momentum
As we are all aware, AMD is making a deliberate strategic bet on open-source software. ROCm, its open-source compute stack, has long been seen as a weak point, but that’s starting to change. ROCm is gaining real traction, and more importantly, credible traction.
What stands out is that customers themselves are contributing back. These aren’t superficial endorsements from the keynote stage, but rather actual code collaborations that make ROCm better for everyone using Instinct GPUs.
Meta’s Yee Jiun Song explained:
We’ve partnered closely to enable ROCm through PyTorch, ensuring developers can use AMD GPUs with PyTorch’s ease of use out of the box. Beginning last year, we started working on improving ROCm’s communication library, RCCL, which is critical for AI training.
We also collaborate on optimizing Llama models to run well on AMD GPUs.
Because Meta works in the open on PyTorch and Llama those ROCm improvements ripple across the entire AI developer ecosystem, not just Meta’s own infrastructure! That’s the power of open.
xAI is doing the same. As Xiao Sun shared:
Our inference infrastructure is based on SGLang, a popular open-source platform. Many of the major contributors are also part of xAI. As they advance one of the most optimized inference systems, they also contribute heavily to the open-source community.
We upstream our innovations to the public SGLang repo, and in return, we benefit from the community—people find bugs, fix code, and we merge those improvements into our production infrastructure. That’s been really helpful. Open source is essential to us, and we’re committed to continuing our contributions and collaboration with the community.
SGLang runs well on Instinct. And as xAI improves it, those gains cascade to other AMD customers and prospects.
AMD’s open strategy is working, and momentum is building. Major players are not only adopting ROCm but also investing in it. Can the weight of the open ecosystem and these big players accelerate ROCm enough that we stop talking about the CUDA moat?
Systems Roadmap
AMD’s roadmap makes clear it’s in this for the long haul. The MI400 series (often referred to as the 450 series) is slated for 2026.

As AI shifts from training to inference, and from R&D to large-scale deployment, buyers need more than just chips. They need a predictable platform, a full stack they can build around and trust to evolve with their needs.
Historically, Nvidia won by owning the stack: great GPUs, yes, but also software and interconnects. Nvidia had a turn-key, optimized system. AMD lagged here. But that gap is narrowing.
AMD is following suit, announcing systems on an annual cadence across CPUs, GPUs, and networking, all built for interoperability and openness.

MI350 is already shipping.
In 2026, the MI400 series will launch alongside Venice EPYC CPUs (first TSMC 2nm HPC product) and Vulcano NICs, marking the first time AMD GPUs will support UALink for true rack-scale coherence. Vulcano is a UEC 1.0-compliant AI NIC with 800G throughput, PCIe and UALink connectivity, and 8× the scale-out bandwidth per GPU over the prior generation.
Also in 2026, AMD’s systems future comes into focus with Helios, AMD’s first full-rack, AI-native system with ZTSystem’s fingerprints on it.

Notice anything about that rack? It’s double-wide. Thicc.
Yes, it looks different than Nvidia’s single-vendor, liquid-cooled AI system.

Helios is the first single-vendor, full-rack AI platform from someone other than Nvidia.
If you want competitive AI systems but with different priorities—more memory capacity, OCP-compliant design, and higher bandwidth—there’s finally an off-the-shelf alternative. And it holds its own:

Of course, openness means flexibility. AMD’s composable hardware still allows customers to design their own systems; Helios is just one instantiation of that capability.
Remember, until now, there wasn’t a true end-to-end alternative to NVIDIA’s vertically integrated AI stack. Yes, AMD had solid components (MI300, EPYC) but no integrated systems. That left customers to stitch together solutions through OEMs and integrators, and ROCm was still maturing and lacking the polish needed for platform-level adoption.
In many ways, that experience mirrored what hyperscalers go through when building custom AI accelerators: relying on partners for design and integration, writing a lot of software, and wrestling with compatibility headaches.
That’s no longer the case. In just a year, AMD has executed across the stack to deliver end-to-end systems. ROCm 7 is shipping with real ecosystem traction, and the ZT Systems acquisition gives AMD tighter control over how its silicon translates into rack-level deployments. Importantly, there is now a credible turnkey alternative to a closed, premium offering or rolling your own custom accelerator stack.
Customer Excitement
I think the most surprising and bullish signal for AMD’s approach is the excitement from customers and partners.
Of course, there’s no one bigger in AI than Sam Altman:
Lisa Su: One of those customers who has been a very, very early design partner and has given us significant feedback on the requirements for next-generation training and inference is OpenAI. We've been honored—we’ve really appreciated the partnership and collaboration between OpenAI and AMD over the last few years, working together in Azure, supporting your research, and especially the deep design work on MI450. You were really early with some important insights. Can you tell us a little about how that collaboration has evolved, and how we can do more for you?
Sam Altman: It’s been amazing working with you all. We’re already running some workloads on the MI300X, but the MI450 series—and the work we’ve done together over the last couple of years—has been incredibly exciting. We’re very grateful you listened to our input. Hopefully we’ve been a good representative of what the industry needs more broadly. We’re extremely excited for the MI450. The memory architecture looks great for inference, and we believe it can be an incredible option for training as well. When you first told me the specs, I thought, “There’s no way—that sounds totally crazy, that’s too big.” But it’s been exciting to see you get close to delivering it. I think this is going to be amazing.
Wow. Did anyone see that coming a year ago?
And check out what Oracle Cloud is doing with Instinct, and how their customers perceive AMD. From Mahesh Thiagarajan, EVP at Oracle Cloud Infrastructure:
Mahesh Thiagarajan: Eighteen months ago, we launched our AMD Instinct partnership, and we’re seeing strong momentum—customer demand is growing rapidly. We’re projecting about 10× growth over the next year as we continue to drive adoption of the AMD Instinct platform on OCI.
What’s most exciting for me is that we’re now announcing our partnership on MI355, bringing AMD’s latest accelerator to the cloud, with support for zettascale clusters. I’m especially excited because this isn’t just roadmap—we’re going live in a couple of months with over 27,000 MI355 GPUs in a single cluster on OCI.
How’s that for scale out! Mahesh continues,
Lisa Su: This conversation is also about the future. Oracle has been leading when it comes to giga-scale data centers, and we’re thinking about what’s required at a systems level. Tell us what it really means to build at giga scale—and how AMD can be part of that journey.
Mahesh Thiagarajan: Today, the biggest challenge is still power—it’s the core bottleneck. That, and how fast we can build. The second factor is time to market. One of the things we’ve pioneered at OCI is deploying cloud infrastructure in as little as three racks, which dramatically shortens deployment time. And of course, we’re always focused on delivering price-performance value. With over 100 regions now live, we can reach customers globally—and that’s exactly why AMD and Oracle make such a strong team. It’s all about value.
AMD is seen by customers as having strong price-performance value.
Hey, that’s how AMD eked out share in CPUs too!

Like everyone else, OCI is very excited about 2026 too.
Mahesh Thiagarajan: Our customers benefit from the AMD plus Oracle combination, and we’re really looking forward to what’s coming next. I’ve seen some of the specs on the 450X platform—it looks truly special.
And one final note. Oracle has possibly upped the ante from 30K to more than 130K MI355X, see here. But I’m not quite sure how to interpret “up to 131K…” as it doesn’t seem like a commitment, but that they are open to it? 🤷🏼♂️
Enterprise AI
Yet Instinct isn’t just for AI labs or hyperscalers, but is enterprise-ready, batteries included. After all, many enterprises aren’t AI experts, and they need things to just work.
That starts with software. ROCm now supports PyTorch, ONNX, vLLM, and SGLang out of the box:

I was pleasantly surprised to see the progress of ROCm Enterprise AI, which provides the operational tooling enterprises need too, including MLOps integration, workload and quota management, Kubernetes and Slurm orchestration, and cluster-level telemetry:

It also plugs into the broader enterprise ecosystem, with support for Canonical, Red Hat OpenShift AI, VMware Cloud Foundation, UbiOps, and ClearML—meaning enterprises can adopt AMD’s stack easily within existing IT infra.
Enterprise buyers are pragmatic. Most prioritize time to value, seamless integration, and predictable costs over raw peak FLOPS. With stronger software and practical hardware—air-cooled, OCP-compliant, standards-based, and shipping today—AMD’s enterprise positioning is looking increasingly competitive.
One more space to watch is AMD’s enterprise edge AI push, where flexible form factors like discrete Radeon GPUs and manycore Threadripper CPUs could offer practical, cost-effective solutions for smaller-scale inference and on-prem deployment.
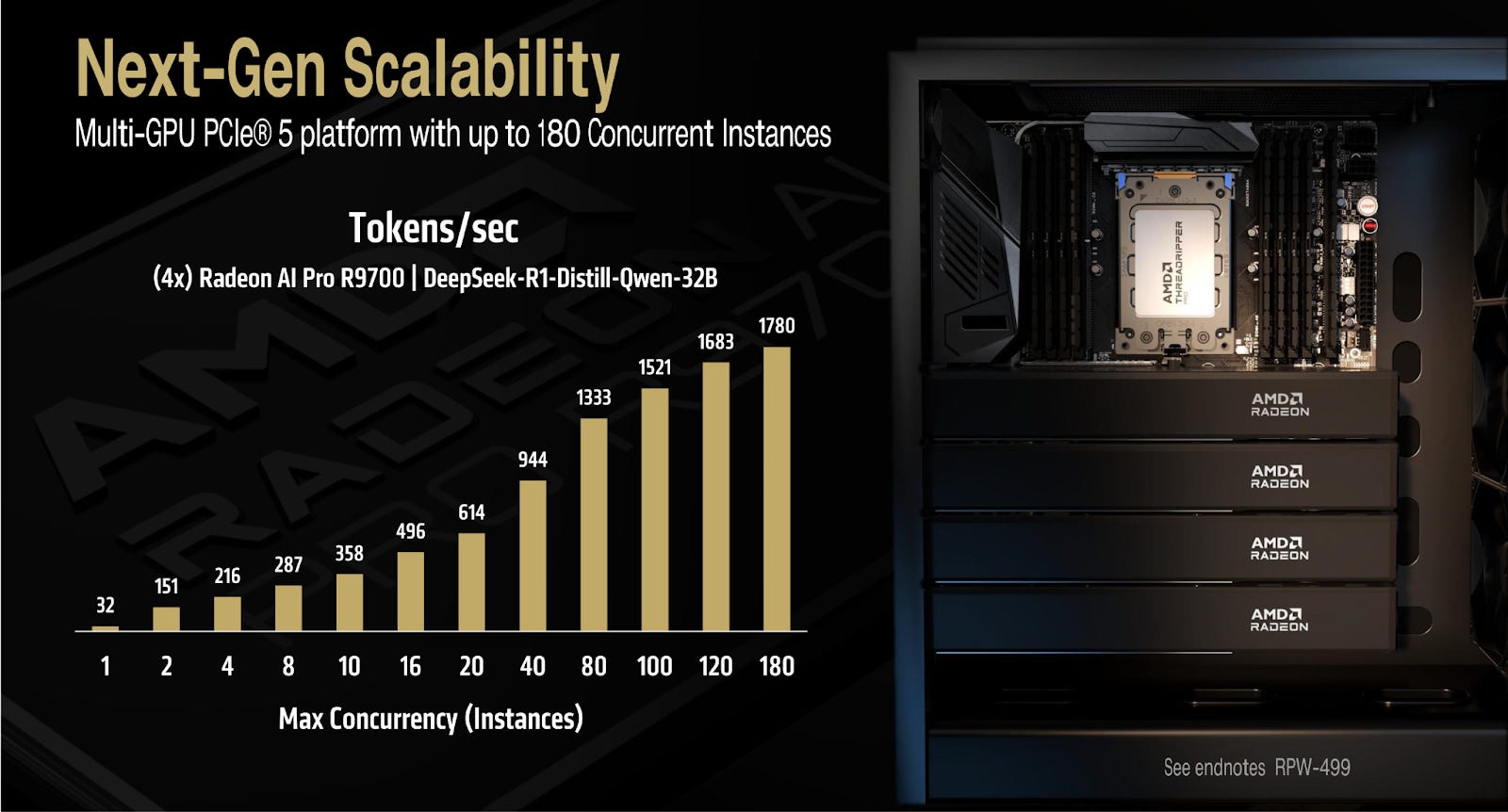

AMD’s Opening Vs Nvidia
The TAM pie is growing. AMD’s slice can grow too, and faster than the training era.
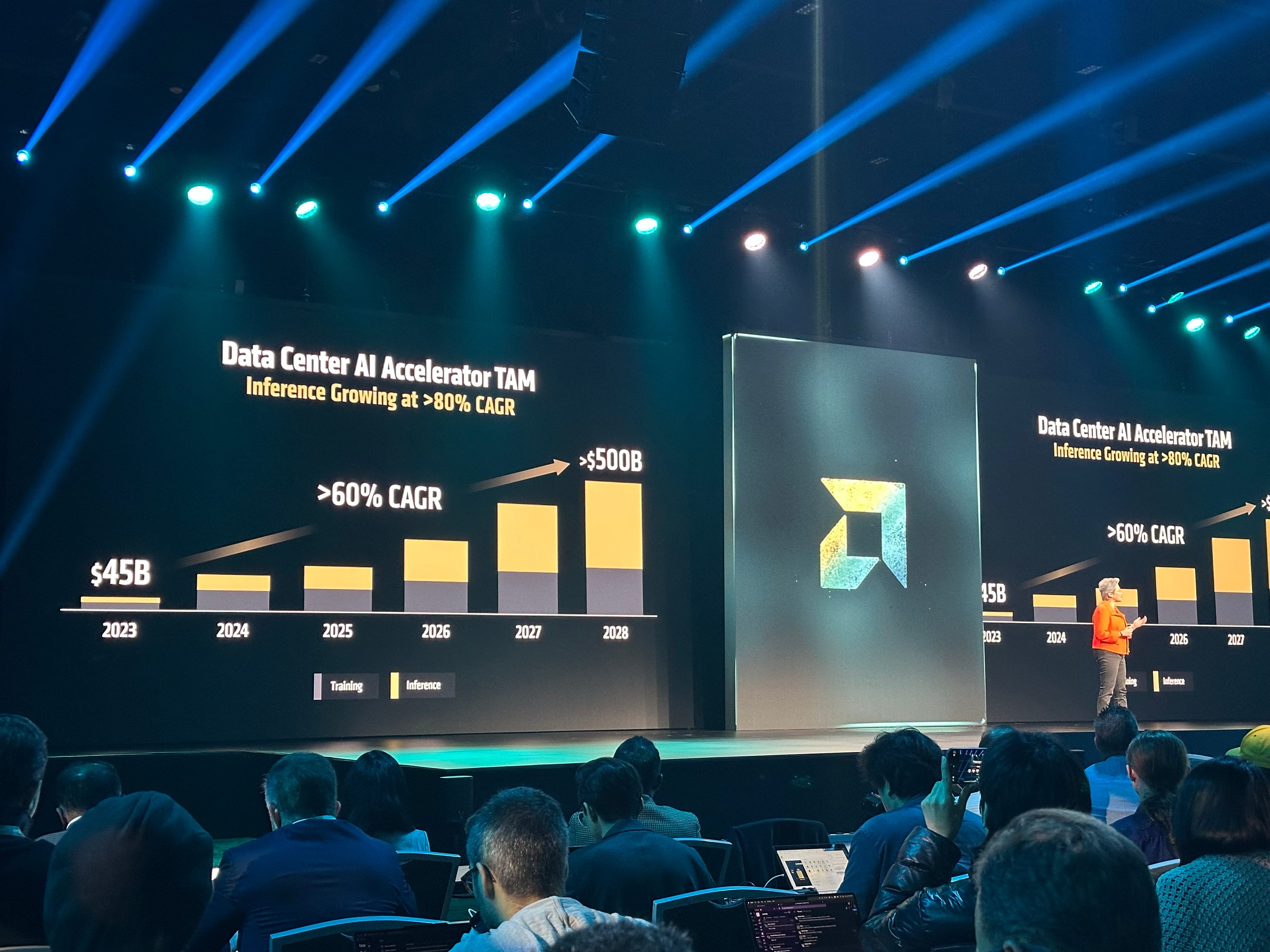
After all, no single company can be “everything to everyone”.
There’s an opening for AMD to serve the part of the market Nvidia isn’t optimizing for.
But who are these customers, exactly?
What are they optimizing for?
And where does AMD still fall short?
There are definitely opportunities, but challenges too.
Can AMD deliver? I’ll unpack all this below for paid subscribers.