

Agentic AI Needs CPUs. Whose CPUs?
Nvidia Vera, Arm AGI CPU, Meta, x86, more

My kids like to make browser-based video games on demand, inspired by books they read (e.g. Super Rabbit Boy) or just random ideas:
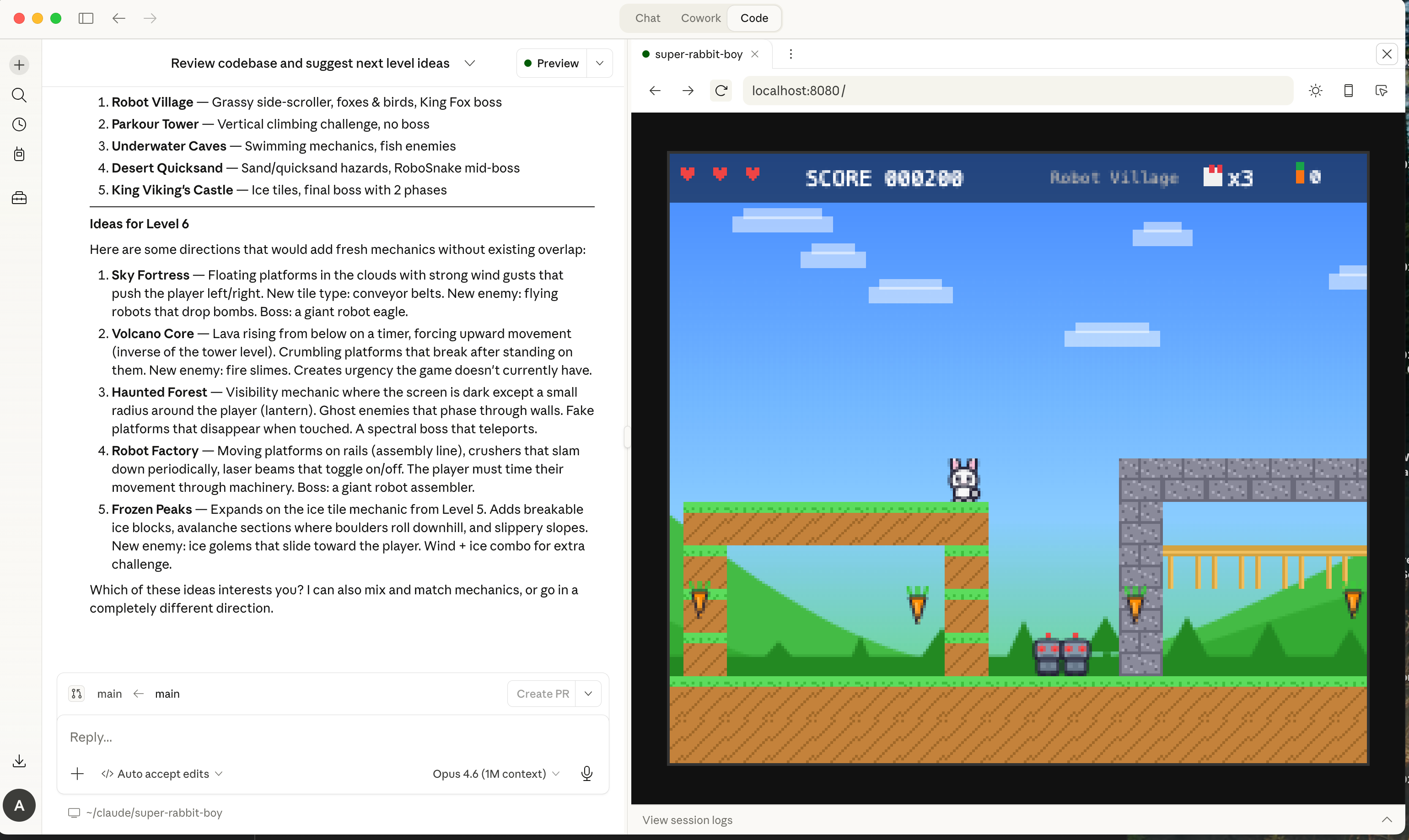
It’s amazing. They just describe what they want, and Claude code asks some clarifying questions, and then runs off and builds it.
If you haven’t tried having AI build software for you yet... you gotta try it. Claude Code or Claude Cowork, Cursor, OpenAI’s Codex, Perplexity Computer, whatever. It’s easy to get started with something simple on your laptop.
We often spin up several simultaneous agents and build many things at once. Dad, can we create a black hole simulator while we wait for this game to build? Sure, buddy!
Now, if I spin up a bunch of agents and they are all doing heavy token generation on my behalf, are the deterministic tasks like API fetching and code execution running on server CPUs or just locally on my machine? Great question.
I personally use the command line version of Claude to spin up agents, so let’s see if we can figure out what it does.
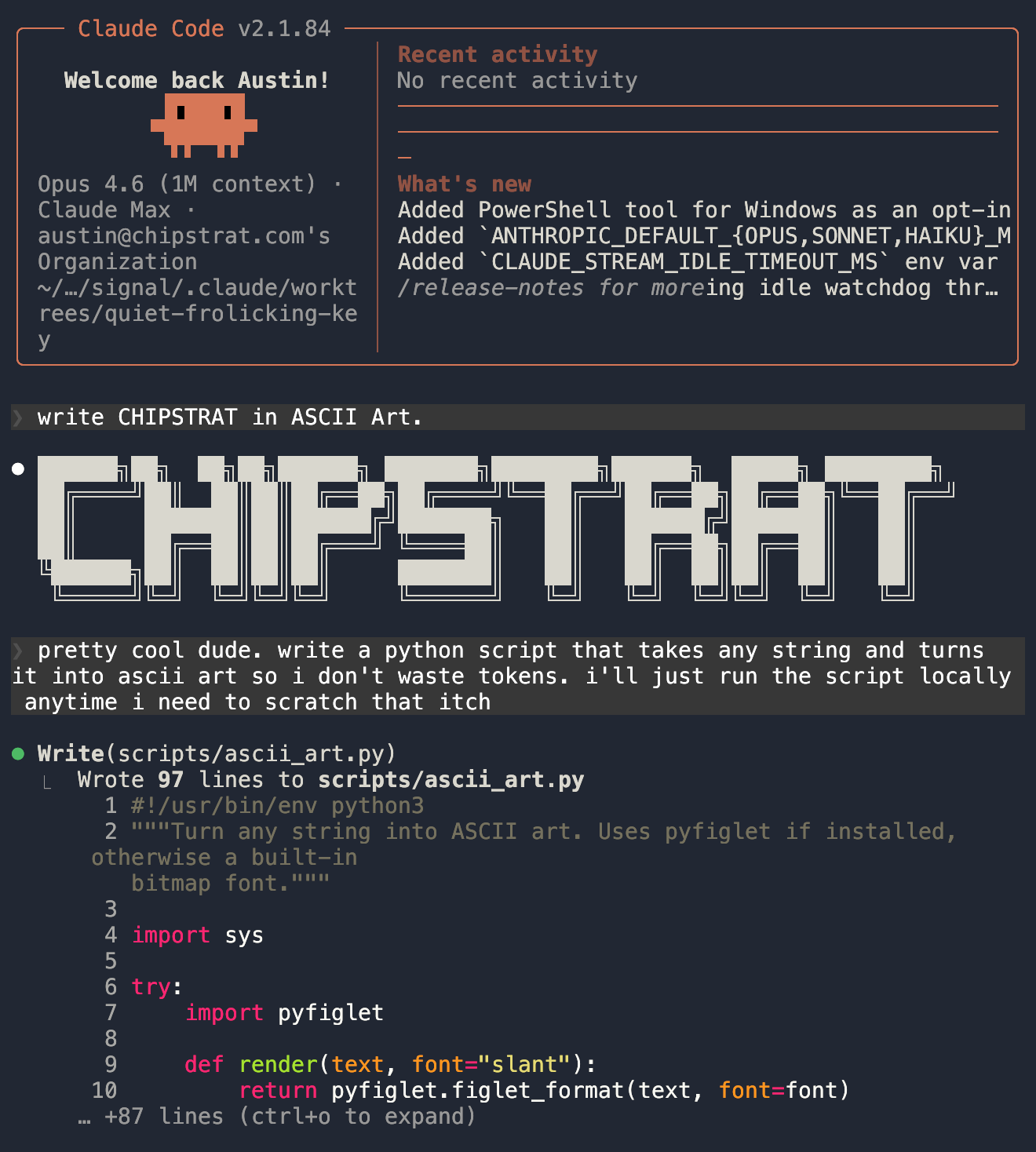
This CLI is open source, so we can read the code to figure out how it works. lol jk, we won’t read the code, we’ll just have Claude Code read its own source code for us. It turns out the CLI runs almost everything locally, which, in my case, is on an Apple M4 chip. So when Claude Code on my MacBook writes and executes code to generate the ASCII art in the image above, the non-GenAI bits run locally on my MacBook.
Now, that doesn’t mean EVERYTHING agentic will run locally. As cool as Claude Code and OpenClaw are, they aren’t the only way to run agentic AI. A lot of agentic AI will be kicked off via phone and web apps. The user will taps a button or type a sentence in a normal app, and behind the scenes an agent spins up in the cloud, runs tools, makes API calls, executes code, fetches data — all CPU work on server racks. The apps themselves can use the Claude API, which offers the same primitives the CLI offers locally — code execution, web search, programmatic tool calling, and so on. But they run in the cloud and can be scaled.
Cloud-based agents will contribute a ton of agentic AI inference in the coming years, and will continue to be a key driver of the majority of Anthropic’s revenue.
In GPU inference servers, the head node's CPU is there to keep GPUs fully utilized. Agentic workloads introduce orchestration and tool execution overhead that erodes CPU headroom and constrains GPU utilization. The fix is to extend beyond the head node into a proximate CPU rack, positioned close to the GPU racks to minimize latency and maintain throughput.
Ok then, if we need racks of AI CPUs for agentic AI... which racks? Like AMD Epyc or Intel Xeon racks? Or Graviton / Cobalt / Axion racks? Or what?
Well, it probably makes sense to start with the same kind of CPUs that are already running the Gen AI related CPU workloads today, right? The existing head node CPUs already handle orchestration, multi-modal fan-out, data pre- and post-processing, and so on.
Maybe just buy more of those? Like my dad always said, if it ain’t broke, don’t fix it.
And interesting, those are often Arm CPUs these days.
As a reminder, Hopper systems typically paired GPUs with Intel Xeon CPUs, most often Sapphire Rapids or Emerald Rapids. Nvidia had little incentive to drive AMD CPU share given Instinct competition, though OEMs still offered server configurations with AMD EPYC head nodes.
But, Blackwell-era GPUs were mostly paired with Nvidia’s Grace CPU (Arm Neoverse V2). Which means the most important workload of our lifetime to date, LLM inference, was initially deployed on x86 but quickly moved to Arm.
Now I’m curious. What about XPUs?
Claude inference on Trainium 2 uses x86 head nodes, purportedly Intel Sapphire Rapids. At roughly one CPU socket per eight Trn2 chips, the one-million-accelerator Trn2 deployment implies about 125K x86 CPUs. Nice. But wait! According to SemiAnalysis, Trainium3 is moving to Graviton4 (Arm Neoverse V2).
Hmm. Another instance of inference clusters swapping CPU sockets to Arm.
And maybe TPUs are heading that direction too? Per SA, “in the future, Google will design Axion CPUs for use as head nodes in their TPU clusters powering Gemini”.
It sure seems like a lot of the CPU workloads that support LLM inference are already running on Arm, or heading in that direction.
And thus adding nearby racks of Arm CPUs to create headroom for agentic AI seems very sensible.
OK then, where does one buy such racks of Arm CPUs anyway?
Option A: Build Your Own
The cloud providers (AWS, Google, Microsoft) are already building custom Arm CPUs (Graviton, Axion, Cobalt). But these existing Arm CPUs were designed for traditional cloud server workloads. Ya know, APIs, databases, web servers, and all that jazz used to build SaaS empires. Agentic AI workloads have different requirements than cloud-native ones. They want much more memory bandwidth per core. Low tail latency. Etc.
So CSPs could add new custom CPU SKUs to the roadmap, tuned appropriately. Same team can reuse a lot of the same IP, it wouldn’t be that bad. But the agentic AI CPU demand/supply imbalance is hitting RIGHT NOW. No one has time to wait for an agentic-flavored Graviton to be designed, validated, and taped out.
In the meantime, sure, CSPs could just use their existing custom CPUs. They might not be perfectly optimized for the workload, but given we’re in agentic takeoff, all CPUs on deck. Perfect is the enemy of good. But, of course, at massive scale, every inefficiency adds up, so there’s still going to be a need for the right CPUs designed for the agentic AI workload in the fullness of time.
Btw, this “good enough” argument could be applied to Arm-based server SKUs from Qualcomm and Ampere, which were not designed with Agentic AI in mind. But silicon is in short supply... if you’ve got ‘em, sell ‘em.
One final observation: future agentic CPUs from hyperscalers will likely adopt Arm’s Neoverse V3 CSS, which carries higher royalty rates than V2. If so, agentic AI drives both unit volume and Arm’s average royalty per chip.
Option B: Buy Nvidia Vera
If you want to stay on Arm and you need racks now, you’re in luck — Nvidia is selling them. The Vera CPU, which Nvidia calls “the world’s first processor purpose-built for the age of agentic AI,” is built on 88 custom Olympus cores (Arm Neoverse V2). The liquid-cooled Vera rack has “256 liquid-cooled Vera CPUs to sustain more than 22,500 concurrent CPU environments, each running independently at full performance”.
Nvidia’s gonna sell a lot of these Vera racks for agentic AI.
Profit pools don’t stay uncontested, though. If there’s money to be made, competitors will appear. And who might that be? The CSPs are the obvious candidates, but their model centers on deploying infrastructure for internal use and rental, not selling merchant silicon. Well, maybe not GCP if the rumors about selling TPUs are true.
OK. I’ve buried the lede... you’ve surely put this together by now…
Who else can sell Arm-based agentic AI CPU racks?
Option C: Buy from Arm
Arm can!
They’ve already done most of the heavy lifting with CSS, the Compute Subsystem that stitches together CPU cores and system IP, and handles the backend physical design too. At that point, why not just take it all the way across the finish line and build the full chip?
And that is exactly what happened.
This week, Arm announced the Arm AGI CPU, the first merchant silicon offering from Arm.

For the first time in its 35+ year history, Arm is a merchant silicon CPU vendor.
Some details from the announcement:
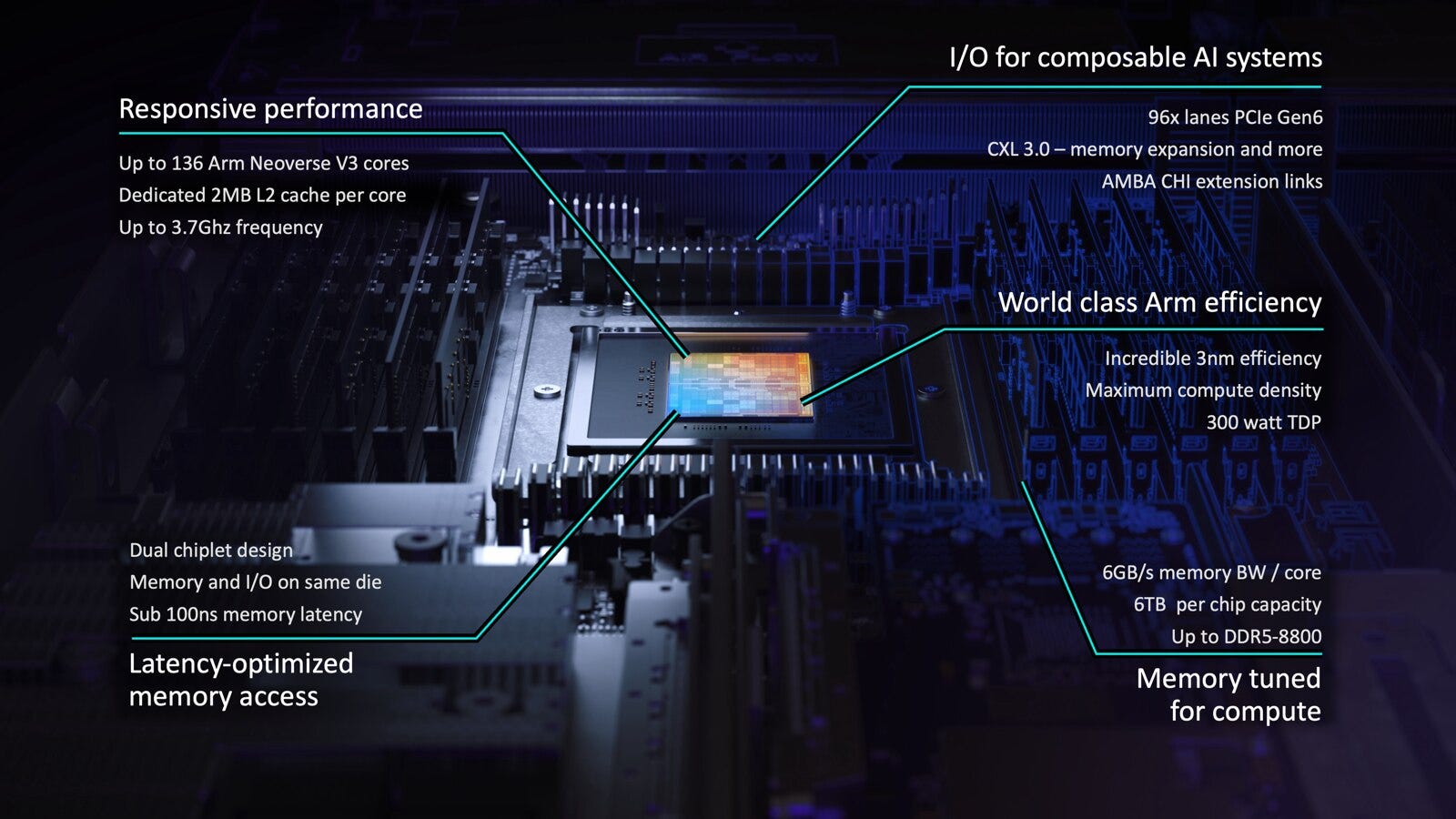
For the workloads driving CPU demand in AI like agentic orchestration (web searches, API calls, agent fan-out), RL training sandboxes (code compilation, verification, tool use), and data processing, you need lots of performant cores.
That’s exactly what the AGI CPU claims to deliver. In a liquid-cooled 200kW rack it has over 45,000 cores:

Note that these CPUs to GPU racks over the network, not via direct chip-to-chip links. Nvidia’s NVLink C2C only applies in the integrated Vera Rubin NVL72, where CPUs and GPUs live in the same rack. I had heard some confusion here so wanted to clarify.
So… Arm is now selling chips. If you need agentic Arm racks you can build, buy from Nvidia, or buy from Arm.
But there are still many questions to think through, including:
Vera vs. AGI. Different strengths, different price points.
Where are the x86 agentic AI CPU racks?
Why are Meta and OpenAI launch customers for both Vera and AGI CPU?
I’ll hit on these and more for paid subscribers.